 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifeIR at the NTCIR-18 Lifelog-6 Task
May 27, 2025In recent years, sharing lifelogs recorded through wearable devices such as sports watches and GoPros, has gained significant popularity. Lifelogs involve various types of information, including images, videos, and GPS data, revealing users' lifestyles, dietary patterns, and physical activities. The Lifelog Semantic Access Task(LSAT) in the NTCIR-18 Lifelog-6 Challenge focuses on retrieving relevant images from a large scale of users' lifelogs based on textual queries describing an action or event. It serves users' need to find images about a scenario in the historical moments of their lifelogs. We propose a multi-stage pipeline for this task of searching images with texts, addressing various challenges in lifelog retrieval. Our pipeline includes: filtering blurred images, rewriting queries to make intents clearer, extending the candidate set based on events to include images with temporal connections, and reranking results using a multimodal large language model(MLLM) with stronger relevance judgment capabilities. The evaluation results of our submissions have shown the effectiveness of each stage and the entire pipeline.
KnobTree: Intelligent Database Parameter Configuration via Explainable Reinforcement Learning
Jun 21, 2024Databases are fundamental to contemporary information systems, yet traditional rule-based configuration methods struggle to manage the complexity of real-world applications with hundreds of tunable parameters. Deep reinforcement learning (DRL), which combines perception and decision-making, presents a potential solution for intelligent database configuration tuning. However, due to black-box property of RL-based method, the generated database tuning strategies still face the urgent problem of lack explainability. Besides, the redundant parameters in large scale database always make the strategy learning become unstable. This paper proposes KnobTree, an interpertable framework designed for the optimization of database parameter configuration. In this framework, an interpertable database tuning algorithm based on RL-based differentatial tree is proposed, which building a transparent tree-based model to generate explainable database tuning strategies. To address the problem of large-scale parameters, We also introduce a explainable method for parameter importance assessment, by utilizing Shapley Values to identify parameters that have significant impacts on database performance. Experiments conducted on MySQL and Gbase8s databases have verified exceptional transparency and interpretability of the KnobTree model. The good property makes generated strategies can offer practical guidance to algorithm designers and database administrators. Moreover, our approach also slightly outperforms the existing RL-based tuning algorithms in aspects such as throughput, latency, and processing time.
CHEAT: A Large-scale Dataset for Detecting ChatGPT-writtEn AbsTracts
Apr 24, 2023

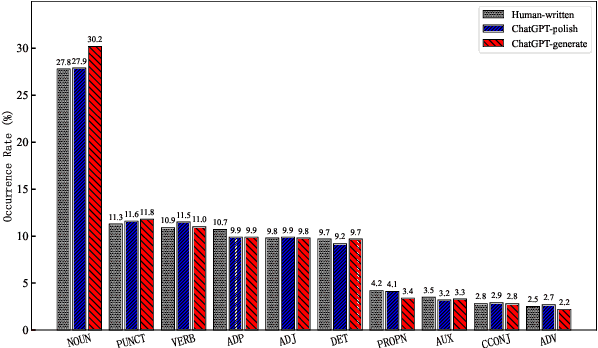
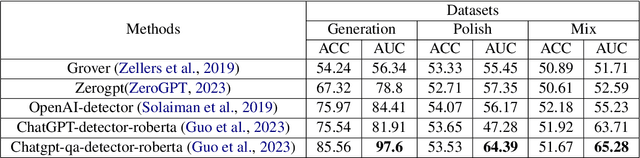
The powerful ability of ChatGPT has caused widespread concern in the academic community. Malicious users could synthesize dummy academic content through ChatGPT, which is extremely harmful to academic rigor and originality. The need to develop ChatGPT-written content detection algorithms call for large-scale datasets. In this paper, we initially investigate the possible negative impact of ChatGPT on academia,and present a large-scale CHatGPT-writtEn AbsTract dataset (CHEAT) to support the development of detection algorithms. In particular, the ChatGPT-written abstract dataset contains 35,304 synthetic abstracts, with Generation, Polish, and Mix as prominent representatives. Based on these data, we perform a thorough analysis of the existing text synthesis detection algorithms. We show that ChatGPT-written abstracts are detectable, while the detection difficulty increases with human involvement.