 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpand VSR Benchmark for VLLM to Expertize in Spatial Rules
Dec 24, 2024



Distinguishing spatial relations is a basic part of human cognition which requires fine-grained perception on cross-instance. Although benchmarks like MME, MMBench and SEED comprehensively have evaluated various capabilities which already include visual spatial reasoning(VSR). There is still a lack of sufficient quantity and quality evaluation and optimization datasets for Vision Large Language Models(VLLMs) specifically targeting visual positional reasoning. To handle this, we first diagnosed current VLLMs with the VSR dataset and proposed a unified test set. We found current VLLMs to exhibit a contradiction of over-sensitivity to language instructions and under-sensitivity to visual positional information. By expanding the original benchmark from two aspects of tunning data and model structure, we mitigated this phenomenon. To our knowledge, we expanded spatially positioned image data controllably using diffusion models for the first time and integrated original visual encoding(CLIP) with other 3 powerful visual encoders(SigLIP, SAM and DINO). After conducting combination experiments on scaling data and models, we obtained a VLLM VSR Expert(VSRE) that not only generalizes better to different instructions but also accurately distinguishes differences in visual positional information. VSRE achieved over a 27\% increase in accuracy on the VSR test set. It becomes a performant VLLM on the position reasoning of both the VSR dataset and relevant subsets of other evaluation benchmarks. We open-sourced the expanded model with data and Appendix at \url{https://github.com/peijin360/vsre} and hope it will accelerate advancements in VLLM on VSR learning.
DeCoF: Generated Video Detection via Frame Consistency
Feb 06, 2024The escalating quality of video generated by advanced video generation methods leads to new security challenges in society, which makes generated video detection an urgent research priority. To foster collaborative research in this area, we construct the first open-source dataset explicitly for generated video detection, providing a valuable resource for the community to benchmark and improve detection methodologies. Through a series of carefully designed probe experiments, our study explores the significance of temporal and spatial artifacts in developing general and robust detectors for generated video. Based on the principle of video frame consistency, we introduce a simple yet effective detection model (DeCoF) that eliminates the impact of spatial artifacts during generalizing feature learning. Our extensive experiments demonstrate the efficacy of DeCoF in detecting videos produced by unseen video generation models and confirm its powerful generalization capabilities across several commercial proprietary models.
Sparse high-dimensional linear mixed modeling with a partitioned empirical Bayes ECM algorithm
Oct 18, 2023High-dimensional longitudinal data is increasingly used in a wide range of scientific studies. However, there are few statistical methods for high-dimensional linear mixed models (LMMs), as most Bayesian variable selection or penalization methods are designed for independent observations. Additionally, the few available software packages for high-dimensional LMMs suffer from scalability issues. This work presents an efficient and accurate Bayesian framework for high-dimensional LMMs. We use empirical Bayes estimators of hyperparameters for increased flexibility and an Expectation-Conditional-Minimization (ECM) algorithm for computationally efficient maximum a posteriori probability (MAP) estimation of parameters. The novelty of the approach lies in its partitioning and parameter expansion as well as its fast and scalable computation. We illustrate Linear Mixed Modeling with PaRtitiOned empirical Bayes ECM (LMM-PROBE) in simulation studies evaluating fixed and random effects estimation along with computation time. A real-world example is provided using data from a study of lupus in children, where we identify genes and clinical factors associated with a new lupus biomarker and predict the biomarker over time.
Heteroscedastic sparse high-dimensional linear regression with a partitioned empirical Bayes ECM algorithm
Oct 03, 2023Sparse linear regression methods for high-dimensional data often assume that residuals have constant variance. When this assumption is violated, it can lead to bias in estimated coefficients, prediction intervals (PI) with improper length, and increased type I errors. We propose a heteroscedastic high-dimensional linear regression model through a partitioned empirical Bayes Expectation Conditional Maximization (H-PROBE) algorithm. H-PROBE is a computationally efficient maximum a posteriori estimation approach based on a Parameter-Expanded Expectation-Conditional-Maximization algorithm. It requires minimal prior assumptions on the regression parameters through plug-in empirical Bayes estimates of hyperparameters. The variance model uses a multivariate log-Gamma prior on coefficients that can incorporate covariates hypothesized to impact heterogeneity. The motivation of our approach is a study relating Aphasia Quotient (AQ) to high-resolution T2 neuroimages of brain damage in stroke patients. AQ is a vital measure of language impairment and informs treatment decisions, but it is challenging to measure and subject to heteroscedastic errors. It is, therefore, of clinical importance -- and the goal of this paper -- to use high-dimensional neuroimages to predict and provide PIs for AQ that accurately reflect the heterogeneity in residual variance. Our analysis demonstrates that H-PROBE can use markers of heterogeneity to provide narrower PI widths than standard methods without sacrificing coverage. Through extensive simulation studies, we exhibit that H-PROBE results in superior prediction, variable selection, and predictive inference than competing methods.
SVDE: Scalable Value-Decomposition Exploration for Cooperative Multi-Agent Reinforcement Learning
Mar 16, 2023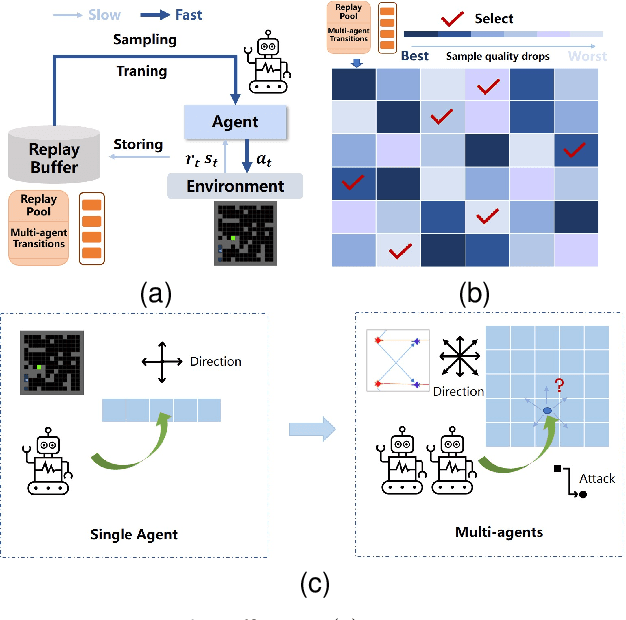
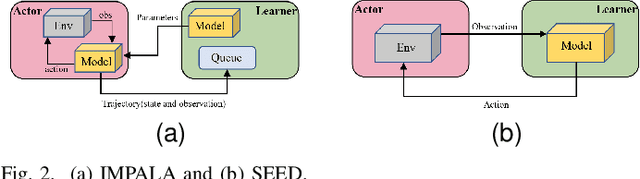
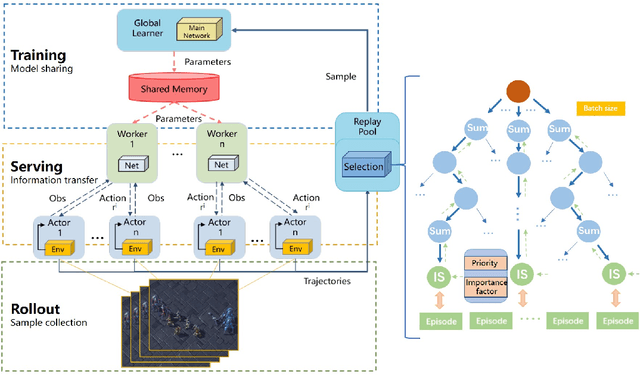
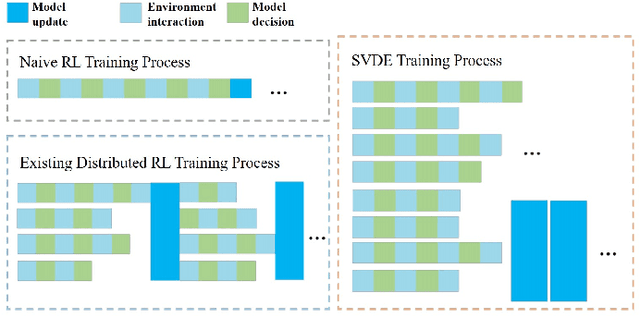
Value-decomposition methods, which reduce the difficulty of a multi-agent system by decomposing the joint state-action space into local observation-action spaces, have become popular in cooperative multi-agent reinforcement learning (MARL). However, value-decomposition methods still have the problems of tremendous sample consumption for training and lack of active exploration. In this paper, we propose a scalable value-decomposition exploration (SVDE) method, which includes a scalable training mechanism, intrinsic reward design, and explorative experience replay. The scalable training mechanism asynchronously decouples strategy learning with environmental interaction, so as to accelerate sample generation in a MapReduce manner. For the problem of lack of exploration, an intrinsic reward design and explorative experience replay are proposed, so as to enhance exploration to produce diverse samples and filter non-novel samples, respectively. Empirically, our method achieves the best performance on almost all maps compared to other popular algorithms in a set of StarCraft II micromanagement games. A data-efficiency experiment also shows the acceleration of SVDE for sample collection and policy convergence, and we demonstrate the effectiveness of factors in SVDE through a set of ablation experiments.
Efficient Distributed Framework for Collaborative Multi-Agent Reinforcement Learning
May 11, 2022


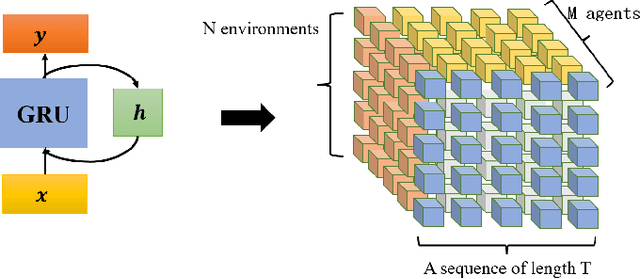
Multi-agent reinforcement learning for incomplete information environments has attracted extensive attention from researchers. However, due to the slow sample collection and poor sample exploration, there are still some problems in multi-agent reinforcement learning, such as unstable model iteration and low training efficiency. Moreover, most of the existing distributed framework are proposed for single-agent reinforcement learning and not suitable for multi-agent. In this paper, we design an distributed MARL framework based on the actor-work-learner architecture. In this framework, multiple asynchronous environment interaction modules can be deployed simultaneously, which greatly improves the sample collection speed and sample diversity. Meanwhile, to make full use of computing resources, we decouple the model iteration from environment interaction, and thus accelerate the policy iteration. Finally, we verified the effectiveness of propose framework in MaCA military simulation environment and the SMAC 3D realtime strategy gaming environment with imcomplete information characteristics.
Design and experimental investigation of a vibro-impact self-propelled capsule robot with orientation control
Mar 01, 2022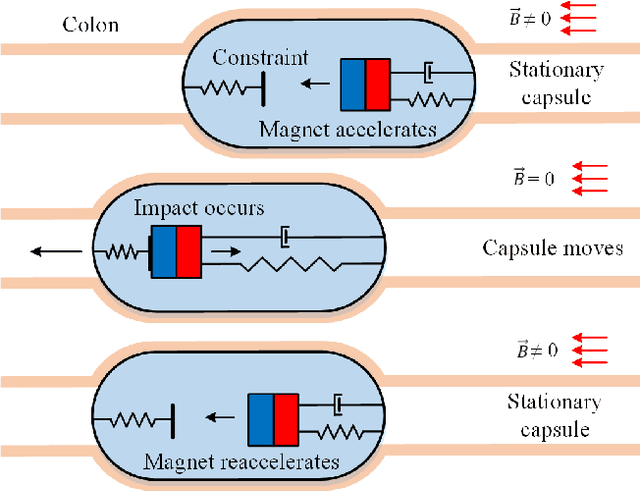

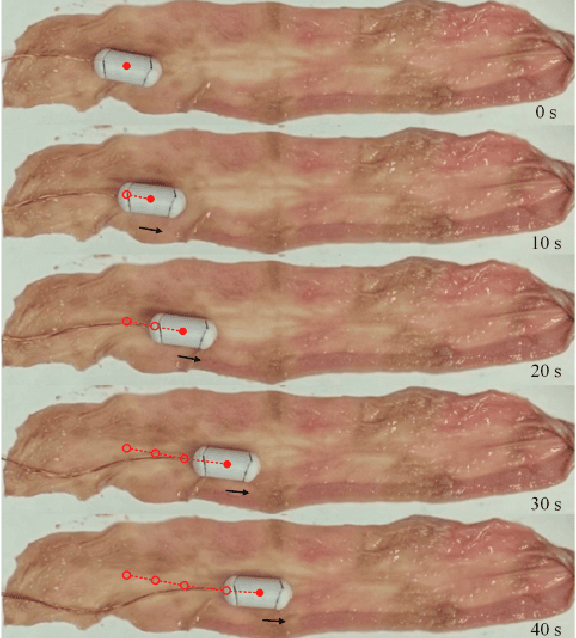
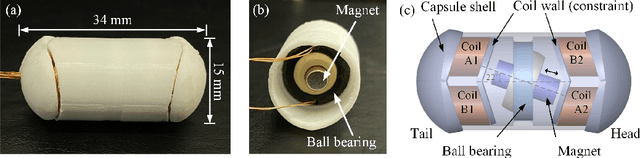
This paper presents a novel design and experimental investigation for a self-propelled capsule robot that can be used for painless colonoscopy during a retrograde progression from the patient's rectum. The steerable robot is driven forward and backward via its internal vibration and impact with orientation control by using an electromagnetic actuator. The actuator contains four sets of coils and a shaft made by permanent magnet. The shaft can be excited linearly in a controllable and tilted angle, so guide the progression orientation of the robot. Two control strategies are studied in this work and compared via simulation and experiment. Extensive results are presented to demonstrate the progression efficiency of the robot and its potential for robotic colonoscopy.
NNCFR: Minimize Counterfactual Regret with Neural Networks
May 26, 2021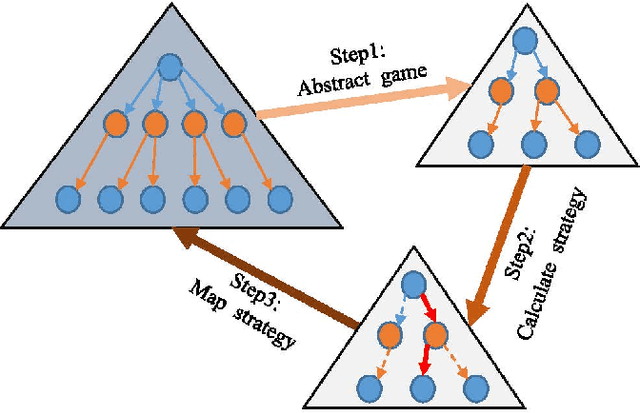
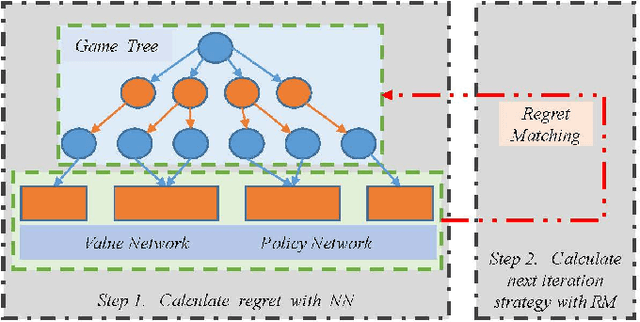
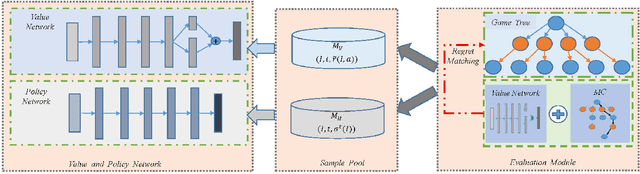
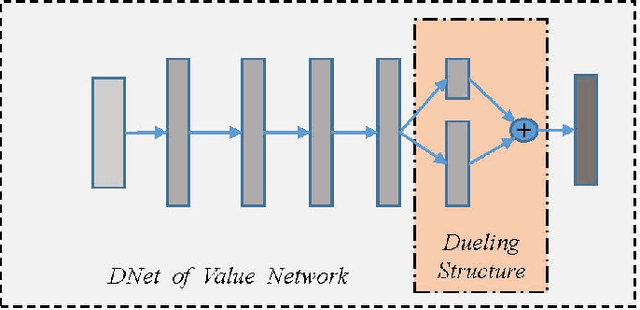
Counterfactual Regret Minimization (CFR)} is the popular method for finding approximate Nash equilibrium in two-player zero-sum games with imperfect information. CFR solves games by travsersing the full game tree iteratively, which limits its scalability in larger games. When applying CFR to solve large-scale games in previously, large-scale games are abstracted into small-scale games firstly. Secondly, CFR is used to solve the abstract game. And finally, the solution strategy is mapped back to the original large-scale game. However, this process requires considerable expert knowledge, and the accuracy of abstraction is closely related to expert knowledge. In addition, the abstraction also loses certain information, which will eventually affect the accuracy of the solution strategy. Towards this problem, a recent method, \textit{Deep CFR} alleviates the need for abstraction and expert knowledge by applying deep neural networks directly to CFR in full games. In this paper, we introduces \textit{Neural Network Counterfactual Regret Minimization (NNCFR)}, an improved variant of \textit{Deep CFR} that has a faster convergence by constructing a dueling netwok as the value network. Moreover, an evaluation module is designed by combining the value network and Monte Carlo, which reduces the approximation error of the value network. In addition, a new loss function is designed in the procedure of training policy network in the proposed \textit{NNCFR}, which can be good to make the policy network more stable. The extensive experimental tests are conducted to show that the \textit{NNCFR} converges faster and performs more stable than \textit{Deep CFR}, and outperforms \textit{Deep CFR} with respect to exploitability and head-to-head performance on test games.
Onfocus Detection: Identifying Individual-Camera Eye Contact from Unconstrained Images
Mar 29, 2021Onfocus detection aims at identifying whether the focus of the individual captured by a camera is on the camera or not. Based on the behavioral research, the focus of an individual during face-to-camera communication leads to a special type of eye contact, i.e., the individual-camera eye contact, which is a powerful signal in social communication and plays a crucial role in recognizing irregular individual status (e.g., lying or suffering mental disease) and special purposes (e.g., seeking help or attracting fans). Thus, developing effective onfocus detection algorithms is of significance for assisting the criminal investigation, disease discovery, and social behavior analysis. However, the review of the literature shows that very few efforts have been made toward the development of onfocus detector due to the lack of large-scale public available datasets as well as the challenging nature of this task. To this end, this paper engages in the onfocus detection research by addressing the above two issues. Firstly, we build a large-scale onfocus detection dataset, named as the OnFocus Detection In the Wild (OFDIW). It consists of 20,623 images in unconstrained capture conditions (thus called ``in the wild'') and contains individuals with diverse emotions, ages, facial characteristics, and rich interactions with surrounding objects and background scenes. On top of that, we propose a novel end-to-end deep model, i.e., the eye-context interaction inferring network (ECIIN), for onfocus detection, which explores eye-context interaction via dynamic capsule routing. Finally, comprehensive experiments are conducted on the proposed OFDIW dataset to benchmark the existing learning models and demonstrate the effectiveness of the proposed ECIIN. The project (containing both datasets and codes) is at https://github.com/wintercho/focus.
RLCFR: Minimize Counterfactual Regret by Deep Reinforcement Learning
Sep 10, 2020



Counterfactual regret minimization (CFR) is a popular method to deal with decision-making problems of two-player zero-sum games with imperfect information. Unlike existing studies that mostly explore for solving larger scale problems or accelerating solution efficiency, we propose a framework, RLCFR, which aims at improving the generalization ability of the CFR method. In the RLCFR, the game strategy is solved by the CFR in a reinforcement learning framework. And the dynamic procedure of iterative interactive strategy updating is modeled as a Markov decision process (MDP). Our method, RLCFR, then learns a policy to select the appropriate way of regret updating in the process of iteration. In addition, a stepwise reward function is formulated to learn the action policy, which is proportional to how well the iteration strategy is at each step. Extensive experimental results on various games have shown that the generalization ability of our method is significantly improved compared with existing state-of-the-art methods.