 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hierarchical Framework for Measuring Scientific Paper Innovation via Large Language Models
Apr 20, 2025Measuring scientific paper innovation is both important and challenging. Existing content-based methods often overlook the full-paper context, fail to capture the full scope of innovation, and lack generalization. We propose HSPIM, a hierarchical and training-free framework based on large language models (LLMs). It introduces a Paper-to-Sections-to-QAs decomposition to assess innovation. We segment the text by section titles and use zero-shot LLM prompting to implement section classification, question-answering (QA) augmentation, and weighted novelty scoring. The generated QA pair focuses on section-level innovation and serves as additional context to improve the LLM scoring. For each chunk, the LLM outputs a novelty score and a confidence score. We use confidence scores as weights to aggregate novelty scores into a paper-level innovation score. To further improve performance, we propose a two-layer question structure consisting of common and section-specific questions, and apply a genetic algorithm to optimize the question-prompt combinations. Comprehensive experiments on scientific conference paper datasets show that HSPIM outperforms baseline methods in effectiveness, generalization, and interpretability.
On the Opportunities of Green Computing: A Survey
Nov 09, 2023



Artificial Intelligence (AI) has achieved significant advancements in technology and research with the development over several decades, and is widely used in many areas including computing vision, natural language processing, time-series analysis, speech synthesis, etc. During the age of deep learning, especially with the arise of Large Language Models, a large majority of researchers' attention is paid on pursuing new state-of-the-art (SOTA) results, resulting in ever increasing of model size and computational complexity. The needs for high computing power brings higher carbon emission and undermines research fairness by preventing small or medium-sized research institutions and companies with limited funding in participating in research. To tackle the challenges of computing resources and environmental impact of AI, Green Computing has become a hot research topic. In this survey, we give a systematic overview of the technologies used in Green Computing. We propose the framework of Green Computing and devide it into four key components: (1) Measures of Greenness, (2) Energy-Efficient AI, (3) Energy-Efficient Computing Systems and (4) AI Use Cases for Sustainability. For each components, we discuss the research progress made and the commonly used techniques to optimize the AI efficiency. We conclude that this new research direction has the potential to address the conflicts between resource constraints and AI development. We encourage more researchers to put attention on this direction and make AI more environmental friendly.
RLCFR: Minimize Counterfactual Regret by Deep Reinforcement Learning
Sep 10, 2020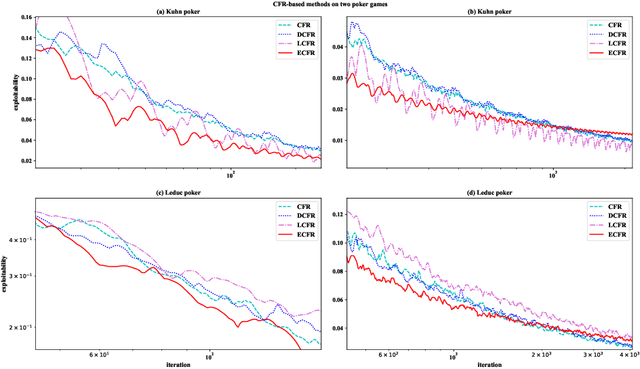



Counterfactual regret minimization (CFR) is a popular method to deal with decision-making problems of two-player zero-sum games with imperfect information. Unlike existing studies that mostly explore for solving larger scale problems or accelerating solution efficiency, we propose a framework, RLCFR, which aims at improving the generalization ability of the CFR method. In the RLCFR, the game strategy is solved by the CFR in a reinforcement learning framework. And the dynamic procedure of iterative interactive strategy updating is modeled as a Markov decision process (MDP). Our method, RLCFR, then learns a policy to select the appropriate way of regret updating in the process of iteration. In addition, a stepwise reward function is formulated to learn the action policy, which is proportional to how well the iteration strategy is at each step. Extensive experimental results on various games have shown that the generalization ability of our method is significantly improved compared with existing state-of-the-art methods.