 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuplex: Dual Prototype Learning for Compositional Zero-Shot Learning
Jan 13, 2025



Compositional Zero-Shot Learning (CZSL) aims to enable models to recognize novel compositions of visual states and objects that were absent during training. Existing methods predominantly focus on learning semantic representations of seen compositions but often fail to disentangle the independent features of states and objects in images, thereby limiting their ability to generalize to unseen compositions. To address this challenge, we propose Duplex, a novel dual-prototype learning method that integrates semantic and visual prototypes through a carefully designed dual-branch architecture, enabling effective representation learning for compositional tasks. Duplex utilizes a Graph Neural Network (GNN) to adaptively update visual prototypes, capturing complex interactions between states and objects. Additionally, it leverages the strong visual-semantic alignment of pre-trained Vision-Language Models (VLMs) and employs a multi-path architecture combined with prompt engineering to align image and text representations, ensuring robust generalization. Extensive experiments on three benchmark datasets demonstrate that Duplex outperforms state-of-the-art methods in both closed-world and open-world settings.
Hybrid Routing Transformer for Zero-Shot Learning
Mar 29, 2022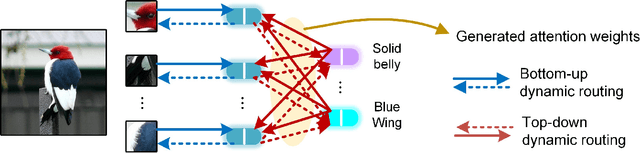
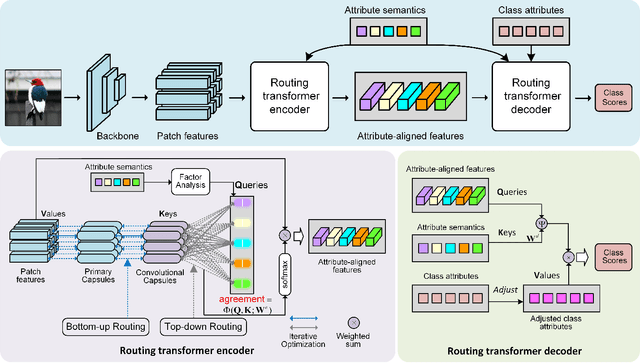
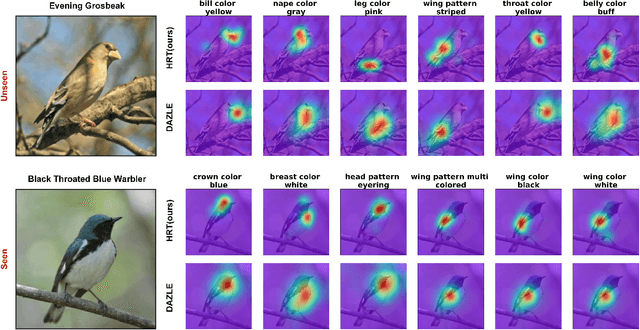
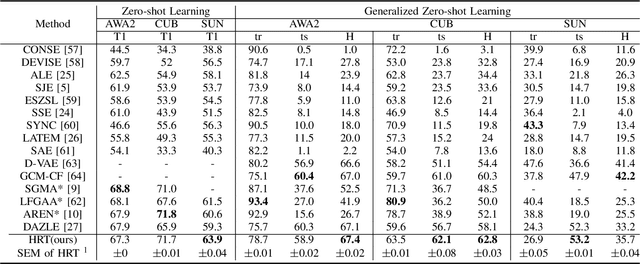
Zero-shot learning (ZSL) aims to learn models that can recognize unseen image semantics based on the training of data with seen semantics. Recent studies either leverage the global image features or mine discriminative local patch features to associate the extracted visual features to the semantic attributes. However, due to the lack of the necessary top-down guidance and semantic alignment for ensuring the model attending to the real attribute-correlation regions, these methods still encounter a significant semantic gap between the visual modality and the attribute modality, which makes their prediction on unseen semantics unreliable. To solve this problem, this paper establishes a novel transformer encoder-decoder model, called hybrid routing transformer (HRT). In HRT encoder, we embed an active attention, which is constructed by both the bottom-up and the top-down dynamic routing pathways to generate the attribute-aligned visual feature. While in HRT decoder, we use static routing to calculate the correlation among the attribute-aligned visual features, the corresponding attribute semantics, and the class attribute vectors to generate the final class label predictions. This design makes the presented transformer model a hybrid of 1) top-down and bottom-up attention pathways and 2) dynamic and static routing pathways. Comprehensive experiments on three widely-used benchmark datasets, namely CUB, SUN, and AWA2, are conducted. The obtained experimental results demonstrate the effectiveness of the proposed method.
Onfocus Detection: Identifying Individual-Camera Eye Contact from Unconstrained Images
Mar 29, 2021Onfocus detection aims at identifying whether the focus of the individual captured by a camera is on the camera or not. Based on the behavioral research, the focus of an individual during face-to-camera communication leads to a special type of eye contact, i.e., the individual-camera eye contact, which is a powerful signal in social communication and plays a crucial role in recognizing irregular individual status (e.g., lying or suffering mental disease) and special purposes (e.g., seeking help or attracting fans). Thus, developing effective onfocus detection algorithms is of significance for assisting the criminal investigation, disease discovery, and social behavior analysis. However, the review of the literature shows that very few efforts have been made toward the development of onfocus detector due to the lack of large-scale public available datasets as well as the challenging nature of this task. To this end, this paper engages in the onfocus detection research by addressing the above two issues. Firstly, we build a large-scale onfocus detection dataset, named as the OnFocus Detection In the Wild (OFDIW). It consists of 20,623 images in unconstrained capture conditions (thus called ``in the wild'') and contains individuals with diverse emotions, ages, facial characteristics, and rich interactions with surrounding objects and background scenes. On top of that, we propose a novel end-to-end deep model, i.e., the eye-context interaction inferring network (ECIIN), for onfocus detection, which explores eye-context interaction via dynamic capsule routing. Finally, comprehensive experiments are conducted on the proposed OFDIW dataset to benchmark the existing learning models and demonstrate the effectiveness of the proposed ECIIN. The project (containing both datasets and codes) is at https://github.com/wintercho/focus.