 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Routing Transformer for Zero-Shot Learning
Paper and Code
Mar 29, 2022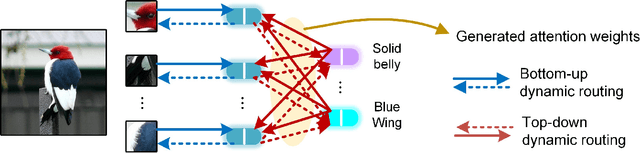
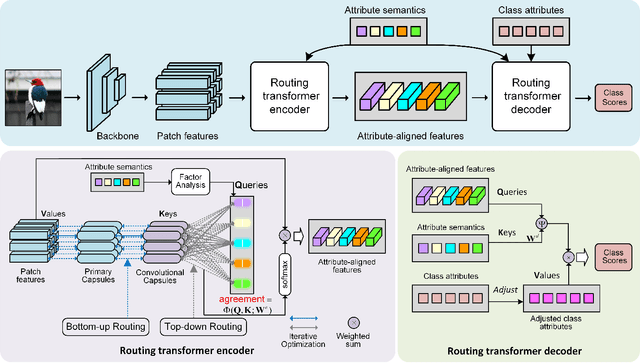
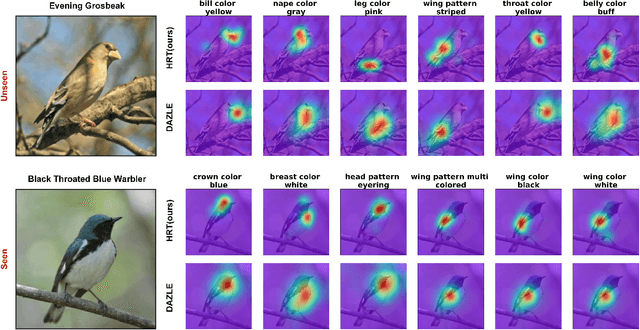
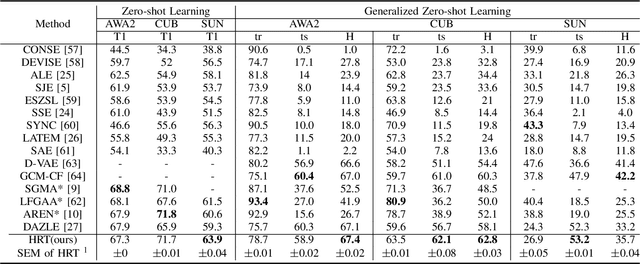
Zero-shot learning (ZSL) aims to learn models that can recognize unseen image semantics based on the training of data with seen semantics. Recent studies either leverage the global image features or mine discriminative local patch features to associate the extracted visual features to the semantic attributes. However, due to the lack of the necessary top-down guidance and semantic alignment for ensuring the model attending to the real attribute-correlation regions, these methods still encounter a significant semantic gap between the visual modality and the attribute modality, which makes their prediction on unseen semantics unreliable. To solve this problem, this paper establishes a novel transformer encoder-decoder model, called hybrid routing transformer (HRT). In HRT encoder, we embed an active attention, which is constructed by both the bottom-up and the top-down dynamic routing pathways to generate the attribute-aligned visual feature. While in HRT decoder, we use static routing to calculate the correlation among the attribute-aligned visual features, the corresponding attribute semantics, and the class attribute vectors to generate the final class label predictions. This design makes the presented transformer model a hybrid of 1) top-down and bottom-up attention pathways and 2) dynamic and static routing pathways. Comprehensive experiments on three widely-used benchmark datasets, namely CUB, SUN, and AWA2, are conducted. The obtained experimental results demonstrate the effectiveness of the proposed method.