 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTriPlay-RL: Tri-Role Self-Play Reinforcement Learning for LLM Safety Alignment
Jan 26, 2026In recent years, safety risks associated with large language models have become increasingly prominent, highlighting the urgent need to mitigate the generation of toxic and harmful content. The mainstream paradigm for LLM safety alignment typically adopts a collaborative framework involving three roles: an attacker for adversarial prompt generation, a defender for safety defense, and an evaluator for response assessment. In this paper, we propose a closed-loop reinforcement learning framework called TriPlay-RL that enables iterative and co-improving collaboration among three roles with near-zero manual annotation. Experimental results show that the attacker preserves high output diversity while achieving a 20%-50% improvement in adversarial effectiveness; the defender attains 10%-30% gains in safety performance without degrading general reasoning capability; and the evaluator continuously refines its fine-grained judgment ability through iterations, accurately distinguishing unsafe responses, simple refusals, and useful guidance. Overall, our framework establishes an efficient and scalable paradigm for LLM safety alignment, enabling continuous co-evolution within a unified learning loop.
FABLE: Forest-Based Adaptive Bi-Path LLM-Enhanced Retrieval for Multi-Document Reasoning
Jan 26, 2026The rapid expansion of long-context Large Language Models (LLMs) has reignited debate on whether Retrieval-Augmented Generation (RAG) remains necessary. However, empirical evidence reveals persistent limitations of long-context inference, including the lost-in-the-middle phenomenon, high computational cost, and poor scalability for multi-document reasoning. Conversely, traditional RAG systems, while efficient, are constrained by flat chunk-level retrieval that introduces semantic noise and fails to support structured cross-document synthesis. We present \textbf{FABLE}, a \textbf{F}orest-based \textbf{A}daptive \textbf{B}i-path \textbf{L}LM-\textbf{E}nhanced retrieval framework that integrates LLMs into both knowledge organization and retrieval. FABLE constructs LLM-enhanced hierarchical forest indexes with multi-granularity semantic structures, then employs a bi-path strategy combining LLM-guided hierarchical traversal with structure-aware propagation for fine-grained evidence acquisition, with explicit budget control for adaptive efficiency trade-offs. Extensive experiments demonstrate that FABLE consistently outperforms SOTA RAG methods and achieves comparable accuracy to full-context LLM inference with up to 94\% token reduction, showing that long-context LLMs amplify rather than fully replace the need for structured retrieval.
Robust Privacy: Inference-Time Privacy through Certified Robustness
Jan 24, 2026Machine learning systems can produce personalized outputs that allow an adversary to infer sensitive input attributes at inference time. We introduce Robust Privacy (RP), an inference-time privacy notion inspired by certified robustness: if a model's prediction is provably invariant within a radius-$R$ neighborhood around an input $x$ (e.g., under the $\ell_2$ norm), then $x$ enjoys $R$-Robust Privacy, i.e., observing the prediction cannot distinguish $x$ from any input within distance $R$ of $x$. We further develop Attribute Privacy Enhancement (APE) to translate input-level invariance into an attribute-level privacy effect. In a controlled recommendation task where the decision depends primarily on a sensitive attribute, we show that RP expands the set of sensitive-attribute values compatible with a positive recommendation, expanding the inference interval accordingly. Finally, we empirically demonstrate that RP also mitigates model inversion attacks (MIAs) by masking fine-grained input-output dependence. Even at small noise levels ($σ=0.1$), RP reduces the attack success rate (ASR) from 73% to 4% with partial model performance degradation. RP can also partially mitigate MIAs (e.g., ASR drops to 44%) with no model performance degradation.
DIVER: Dynamic Iterative Visual Evidence Reasoning for Multimodal Fake News Detection
Jan 12, 2026Multimodal fake news detection is crucial for mitigating adversarial misinformation. Existing methods, relying on static fusion or LLMs, face computational redundancy and hallucination risks due to weak visual foundations. To address this, we propose DIVER (Dynamic Iterative Visual Evidence Reasoning), a framework grounded in a progressive, evidence-driven reasoning paradigm. DIVER first establishes a strong text-based baseline through language analysis, leveraging intra-modal consistency to filter unreliable or hallucinated claims. Only when textual evidence is insufficient does the framework introduce visual information, where inter-modal alignment verification adaptively determines whether deeper visual inspection is necessary. For samples exhibiting significant cross-modal semantic discrepancies, DIVER selectively invokes fine-grained visual tools (e.g., OCR and dense captioning) to extract task-relevant evidence, which is iteratively aggregated via uncertainty-aware fusion to refine multimodal reasoning. Experiments on Weibo, Weibo21, and GossipCop demonstrate that DIVER outperforms state-of-the-art baselines by an average of 2.72\%, while optimizing inference efficiency with a reduced latency of 4.12 s.
SAPL: Semantic-Agnostic Prompt Learning in CLIP for Weakly Supervised Image Manipulation Localization
Jan 09, 2026Malicious image manipulation threatens public safety and requires efficient localization methods. Existing approaches depend on costly pixel-level annotations which make training expensive. Existing weakly supervised methods rely only on image-level binary labels and focus on global classification, often overlooking local edge cues that are critical for precise localization. We observe that feature variations at manipulated boundaries are substantially larger than in interior regions. To address this gap, we propose Semantic-Agnostic Prompt Learning (SAPL) in CLIP, which learns text prompts that intentionally encode non-semantic, boundary-centric cues so that CLIPs multimodal similarity highlights manipulation edges rather than high-level object semantics. SAPL combines two complementary modules Edge-aware Contextual Prompt Learning (ECPL) and Hierarchical Edge Contrastive Learning (HECL) to exploit edge information in both textual and visual spaces. The proposed ECPL leverages edge-enhanced image features to generate learnable textual prompts via an attention mechanism, embedding semantic-irrelevant information into text features, to guide CLIP focusing on manipulation edges. The proposed HECL extract genuine and manipulated edge patches, and utilize contrastive learning to boost the discrimination between genuine edge patches and manipulated edge patches. Finally, we predict the manipulated regions from the similarity map after processing. Extensive experiments on multiple public benchmarks demonstrate that SAPL significantly outperforms existing approaches, achieving state-of-the-art localization performance.
Disentangling Fact from Sentiment: A Dynamic Conflict-Consensus Framework for Multimodal Fake News Detection
Dec 19, 2025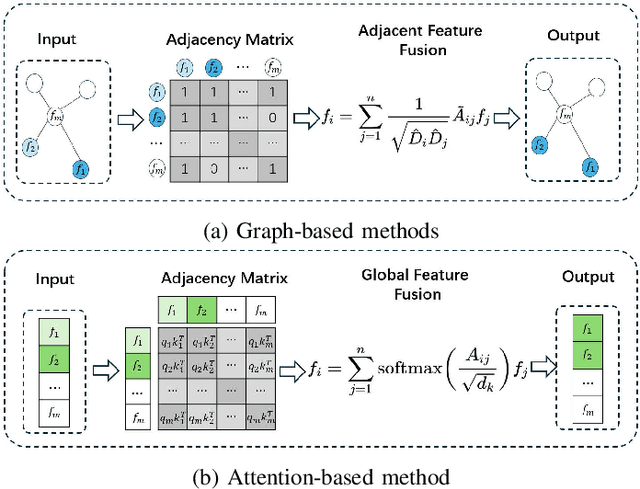
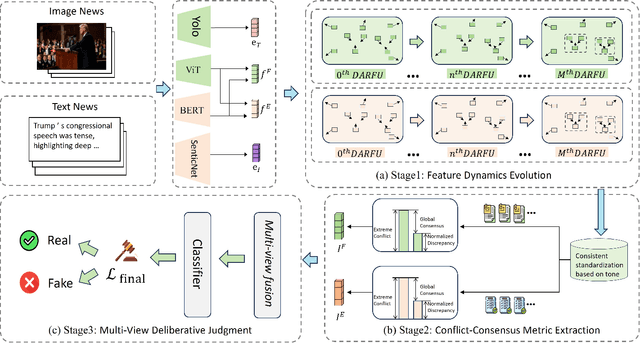
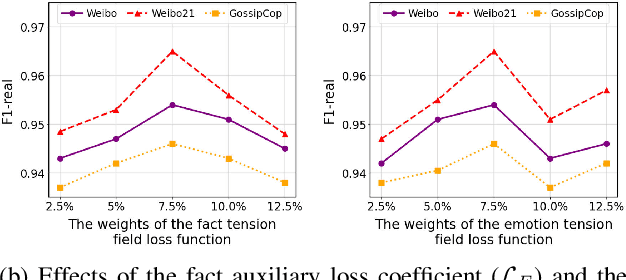
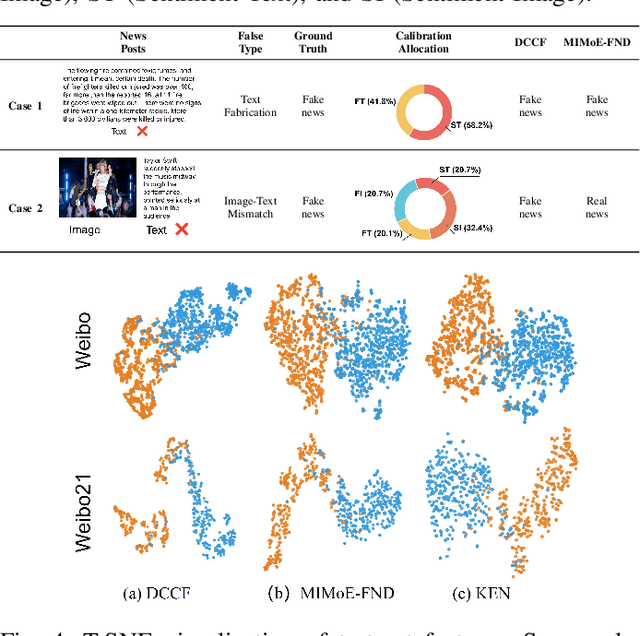
Prevalent multimodal fake news detection relies on consistency-based fusion, yet this paradigm fundamentally misinterprets critical cross-modal discrepancies as noise, leading to over-smoothing, which dilutes critical evidence of fabrication. Mainstream consistency-based fusion inherently minimizes feature discrepancies to align modalities, yet this approach fundamentally fails because it inadvertently smoothes out the subtle cross-modal contradictions that serve as the primary evidence of fabrication. To address this, we propose the Dynamic Conflict-Consensus Framework (DCCF), an inconsistency-seeking paradigm designed to amplify rather than suppress contradictions. First, DCCF decouples inputs into independent Fact and Sentiment spaces to distinguish objective mismatches from emotional dissonance. Second, we employ physics-inspired feature dynamics to iteratively polarize these representations, actively extracting maximally informative conflicts. Finally, a conflict-consensus mechanism standardizes these local discrepancies against the global context for robust deliberative judgment.Extensive experiments conducted on three real world datasets demonstrate that DCCF consistently outperforms state-of-the-art baselines, achieving an average accuracy improvement of 3.52\%.
TextlessRAG: End-to-End Visual Document RAG by Speech Without Text
Sep 10, 2025Document images encapsulate a wealth of knowledge, while the portability of spoken queries enables broader and flexible application scenarios. Yet, no prior work has explored knowledge base question answering over visual document images with queries provided directly in speech. We propose TextlessRAG, the first end-to-end framework for speech-based question answering over large-scale document images. Unlike prior methods, TextlessRAG eliminates ASR, TTS and OCR, directly interpreting speech, retrieving relevant visual knowledge, and generating answers in a fully textless pipeline. To further boost performance, we integrate a layout-aware reranking mechanism to refine retrieval. Experiments demonstrate substantial improvements in both efficiency and accuracy. To advance research in this direction, we also release the first bilingual speech--document RAG dataset, featuring Chinese and English voice queries paired with multimodal document content. Both the dataset and our pipeline will be made available at repository:https://github.com/xiepeijinhit-hue/textlessrag
Evaluation is All You Need: Strategic Overclaiming of LLM Reasoning Capabilities Through Evaluation Design
Jun 05, 2025Reasoning models represented by the Deepseek-R1-Distill series have been widely adopted by the open-source community due to their strong performance in mathematics, science, programming, and other domains. However, our study reveals that their benchmark evaluation results are subject to significant fluctuations caused by various factors. Subtle differences in evaluation conditions can lead to substantial variations in results. Similar phenomena are observed in other open-source inference models fine-tuned based on the Deepseek-R1-Distill series, as well as in the QwQ-32B model, making their claimed performance improvements difficult to reproduce reliably. Therefore, we advocate for the establishment of a more rigorous paradigm for model performance evaluation and present our empirical assessments of the Deepseek-R1-Distill series models.
360-LLaMA-Factory: Plug & Play Sequence Parallelism for Long Post-Training
May 28, 2025Adding sequence parallelism into LLaMA-Factory, we open-sourced 360-LLaMA-Factory at https://github.com/Qihoo360/360-LLaMA-Factory. 360-LLaMA-Factory has received wide recognition and used in models such as Light-R1 arXiv:2503.10460, TinyR1 arXiv:2503.04872, Kaggle AIMO math models and also in large companies' training frameworks. This technical report delves deeper into the different sequence parallel modes behind 360-LLaMA-Factory and discusses our implementation insights.
Light-R1: Curriculum SFT, DPO and RL for Long COT from Scratch and Beyond
Mar 13, 2025This paper presents our work on the Light-R1 series, with models, data, and code all released. We first focus on training long COT models from scratch, specifically starting from models initially lacking long COT capabilities. Using a curriculum training recipe consisting of two-stage SFT and semi-on-policy DPO, we train our model Light-R1-32B from Qwen2.5-32B-Instruct, resulting in superior math performance compared to DeepSeek-R1-Distill-Qwen-32B. Despite being trained exclusively on math data, Light-R1-32B shows strong generalization across other domains. In the subsequent phase of this work, we highlight the significant benefit of the 3k dataset constructed for the second SFT stage on enhancing other models. By fine-tuning DeepSeek-R1-Distilled models using this dataset, we obtain new SOTA models in 7B and 14B, while the 32B model, Light-R1-32B-DS performed comparably to QwQ-32B and DeepSeek-R1. Furthermore, we extend our work by applying reinforcement learning, specifically GRPO, on long-COT models to further improve reasoning performance. We successfully train our final Light-R1-14B-DS with RL, achieving SOTA performance among 14B parameter models in math. With AIME24 & 25 scores of 74.0 and 60.2 respectively, Light-R1-14B-DS surpasses even many 32B models and DeepSeek-R1-Distill-Llama-70B. Its RL training also exhibits well expected behavior, showing simultaneous increase in response length and reward score. The Light-R1 series of work validates training long-COT models from scratch, showcases the art in SFT data and releases SOTA models from RL.