 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiroThinker: Pushing the Performance Boundaries of Open-Source Research Agents via Model, Context, and Interactive Scaling
Nov 18, 2025We present MiroThinker v1.0, an open-source research agent designed to advance tool-augmented reasoning and information-seeking capabilities. Unlike previous agents that only scale up model size or context length, MiroThinker explores interaction scaling at the model level, systematically training the model to handle deeper and more frequent agent-environment interactions as a third dimension of performance improvement. Unlike LLM test-time scaling, which operates in isolation and risks degradation with longer reasoning chains, interactive scaling leverages environment feedback and external information acquisition to correct errors and refine trajectories. Through reinforcement learning, the model achieves efficient interaction scaling: with a 256K context window, it can perform up to 600 tool calls per task, enabling sustained multi-turn reasoning and complex real-world research workflows. Across four representative benchmarks-GAIA, HLE, BrowseComp, and BrowseComp-ZH-the 72B variant achieves up to 81.9%, 37.7%, 47.1%, and 55.6% accuracy respectively, surpassing previous open-source agents and approaching commercial counterparts such as GPT-5-high. Our analysis reveals that MiroThinker benefits from interactive scaling consistently: research performance improves predictably as the model engages in deeper and more frequent agent-environment interactions, demonstrating that interaction depth exhibits scaling behaviors analogous to model size and context length. These findings establish interaction scaling as a third critical dimension for building next-generation open research agents, complementing model capacity and context windows.
Evaluation is All You Need: Strategic Overclaiming of LLM Reasoning Capabilities Through Evaluation Design
Jun 05, 2025Reasoning models represented by the Deepseek-R1-Distill series have been widely adopted by the open-source community due to their strong performance in mathematics, science, programming, and other domains. However, our study reveals that their benchmark evaluation results are subject to significant fluctuations caused by various factors. Subtle differences in evaluation conditions can lead to substantial variations in results. Similar phenomena are observed in other open-source inference models fine-tuned based on the Deepseek-R1-Distill series, as well as in the QwQ-32B model, making their claimed performance improvements difficult to reproduce reliably. Therefore, we advocate for the establishment of a more rigorous paradigm for model performance evaluation and present our empirical assessments of the Deepseek-R1-Distill series models.
TinyR1-32B-Preview: Boosting Accuracy with Branch-Merge Distillation
Mar 06, 2025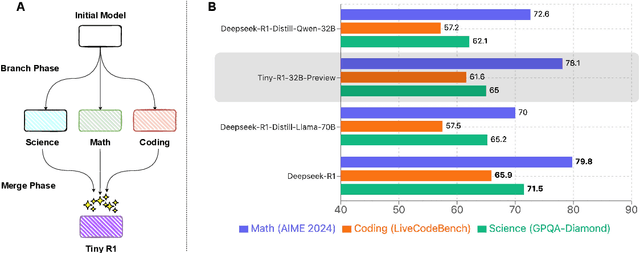
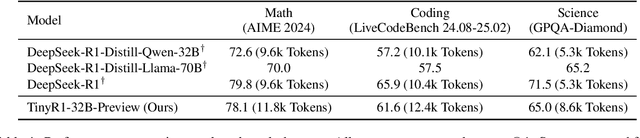
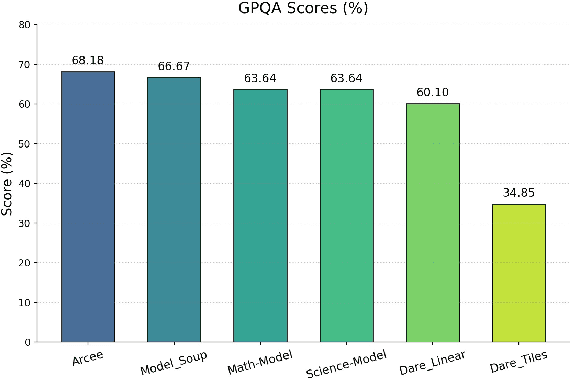
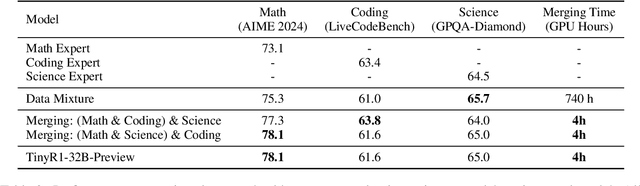
The challenge of reducing the size of Large Language Models (LLMs) while maintaining their performance has gained significant attention. However, existing methods, such as model distillation and transfer learning, often fail to achieve high accuracy. To address this limitation, we introduce the Branch-Merge distillation approach, which enhances model compression through two phases: (1) the Branch Phase, where knowledge from a large teacher model is \textit{selectively distilled} into specialized student models via domain-specific supervised fine-tuning (SFT); And (2) the Merge Phase, where these student models are merged to enable cross-domain knowledge transfer and improve generalization. We validate our distillation approach using DeepSeek-R1 as the teacher and DeepSeek-R1-Distill-Qwen-32B as the student. The resulting merged model, TinyR1-32B-Preview, outperforms its counterpart DeepSeek-R1-Distill-Qwen-32B across multiple benchmarks, including Mathematics (+5.5 points), Coding (+4.4 points) and Science (+2.9 points), while achieving near-equal performance to DeepSeek-R1 on AIME 2024. The Branch-Merge distillation approach provides a scalable solution for creating smaller, high-performing LLMs with reduced computational cost and time.
Stress Testing Generalization: How Minor Modifications Undermine Large Language Model Performance
Feb 18, 2025This paper investigates the fragility of Large Language Models (LLMs) in generalizing to novel inputs, specifically focusing on minor perturbations in well-established benchmarks (e.g., slight changes in question format or distractor length). Despite high benchmark scores, LLMs exhibit significant accuracy drops and unexpected biases (e.g., preference for longer distractors) when faced with these minor but content-preserving modifications. For example, Qwen 2.5 1.5B's MMLU score rises from 60 to 89 and drops from 89 to 36 when option lengths are changed without altering the question. Even GPT-4 experiences a 25-point accuracy loss when question types are changed, with a 6-point drop across all three modification categories. These analyses suggest that LLMs rely heavily on superficial cues rather than forming robust, abstract representations that generalize across formats, lexical variations, and irrelevant content shifts. This work aligns with the ACL 2025 theme track on the Generalization of NLP models, proposing a "Generalization Stress Test" to assess performance shifts under controlled perturbations. The study calls for reevaluating benchmarks and developing more reliable evaluation methodologies to capture LLM generalization abilities better.