 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Privacy: Inference-Time Privacy through Certified Robustness
Jan 24, 2026Machine learning systems can produce personalized outputs that allow an adversary to infer sensitive input attributes at inference time. We introduce Robust Privacy (RP), an inference-time privacy notion inspired by certified robustness: if a model's prediction is provably invariant within a radius-$R$ neighborhood around an input $x$ (e.g., under the $\ell_2$ norm), then $x$ enjoys $R$-Robust Privacy, i.e., observing the prediction cannot distinguish $x$ from any input within distance $R$ of $x$. We further develop Attribute Privacy Enhancement (APE) to translate input-level invariance into an attribute-level privacy effect. In a controlled recommendation task where the decision depends primarily on a sensitive attribute, we show that RP expands the set of sensitive-attribute values compatible with a positive recommendation, expanding the inference interval accordingly. Finally, we empirically demonstrate that RP also mitigates model inversion attacks (MIAs) by masking fine-grained input-output dependence. Even at small noise levels ($σ=0.1$), RP reduces the attack success rate (ASR) from 73% to 4% with partial model performance degradation. RP can also partially mitigate MIAs (e.g., ASR drops to 44%) with no model performance degradation.
DIVER: Dynamic Iterative Visual Evidence Reasoning for Multimodal Fake News Detection
Jan 12, 2026Multimodal fake news detection is crucial for mitigating adversarial misinformation. Existing methods, relying on static fusion or LLMs, face computational redundancy and hallucination risks due to weak visual foundations. To address this, we propose DIVER (Dynamic Iterative Visual Evidence Reasoning), a framework grounded in a progressive, evidence-driven reasoning paradigm. DIVER first establishes a strong text-based baseline through language analysis, leveraging intra-modal consistency to filter unreliable or hallucinated claims. Only when textual evidence is insufficient does the framework introduce visual information, where inter-modal alignment verification adaptively determines whether deeper visual inspection is necessary. For samples exhibiting significant cross-modal semantic discrepancies, DIVER selectively invokes fine-grained visual tools (e.g., OCR and dense captioning) to extract task-relevant evidence, which is iteratively aggregated via uncertainty-aware fusion to refine multimodal reasoning. Experiments on Weibo, Weibo21, and GossipCop demonstrate that DIVER outperforms state-of-the-art baselines by an average of 2.72\%, while optimizing inference efficiency with a reduced latency of 4.12 s.
SAPL: Semantic-Agnostic Prompt Learning in CLIP for Weakly Supervised Image Manipulation Localization
Jan 09, 2026Malicious image manipulation threatens public safety and requires efficient localization methods. Existing approaches depend on costly pixel-level annotations which make training expensive. Existing weakly supervised methods rely only on image-level binary labels and focus on global classification, often overlooking local edge cues that are critical for precise localization. We observe that feature variations at manipulated boundaries are substantially larger than in interior regions. To address this gap, we propose Semantic-Agnostic Prompt Learning (SAPL) in CLIP, which learns text prompts that intentionally encode non-semantic, boundary-centric cues so that CLIPs multimodal similarity highlights manipulation edges rather than high-level object semantics. SAPL combines two complementary modules Edge-aware Contextual Prompt Learning (ECPL) and Hierarchical Edge Contrastive Learning (HECL) to exploit edge information in both textual and visual spaces. The proposed ECPL leverages edge-enhanced image features to generate learnable textual prompts via an attention mechanism, embedding semantic-irrelevant information into text features, to guide CLIP focusing on manipulation edges. The proposed HECL extract genuine and manipulated edge patches, and utilize contrastive learning to boost the discrimination between genuine edge patches and manipulated edge patches. Finally, we predict the manipulated regions from the similarity map after processing. Extensive experiments on multiple public benchmarks demonstrate that SAPL significantly outperforms existing approaches, achieving state-of-the-art localization performance.
Disentangling Fact from Sentiment: A Dynamic Conflict-Consensus Framework for Multimodal Fake News Detection
Dec 19, 2025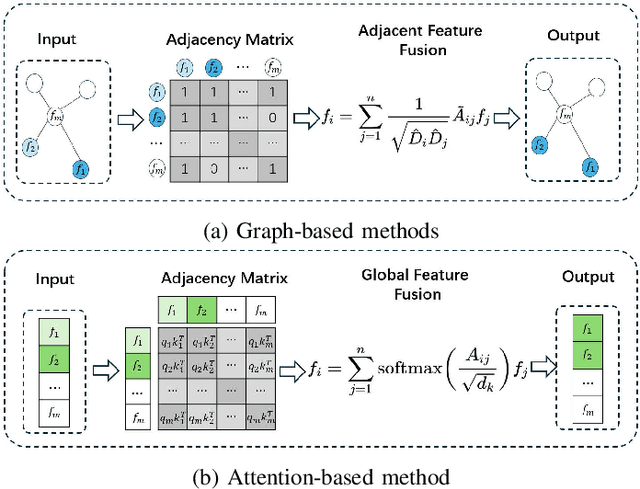
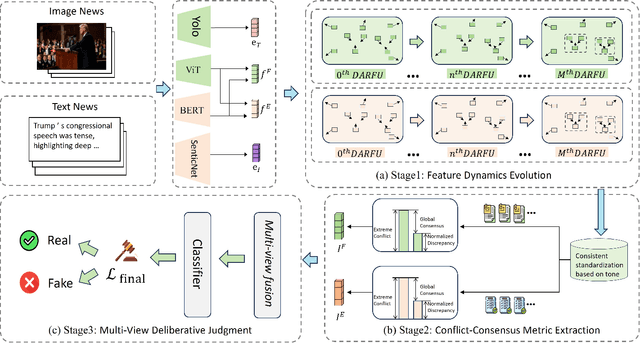
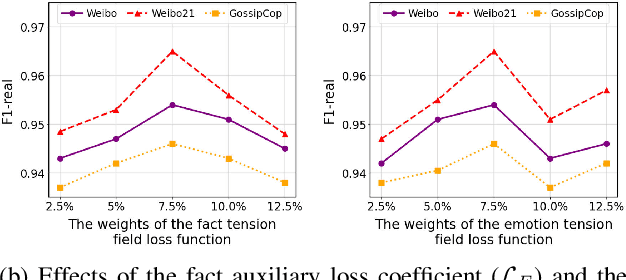
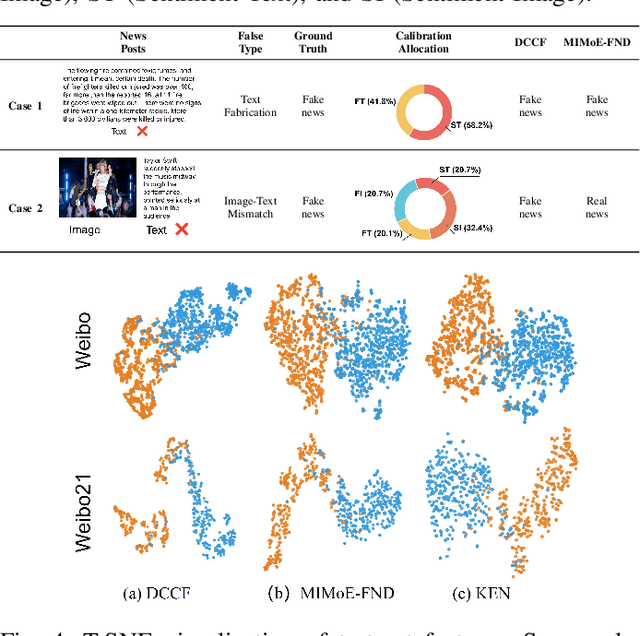
Prevalent multimodal fake news detection relies on consistency-based fusion, yet this paradigm fundamentally misinterprets critical cross-modal discrepancies as noise, leading to over-smoothing, which dilutes critical evidence of fabrication. Mainstream consistency-based fusion inherently minimizes feature discrepancies to align modalities, yet this approach fundamentally fails because it inadvertently smoothes out the subtle cross-modal contradictions that serve as the primary evidence of fabrication. To address this, we propose the Dynamic Conflict-Consensus Framework (DCCF), an inconsistency-seeking paradigm designed to amplify rather than suppress contradictions. First, DCCF decouples inputs into independent Fact and Sentiment spaces to distinguish objective mismatches from emotional dissonance. Second, we employ physics-inspired feature dynamics to iteratively polarize these representations, actively extracting maximally informative conflicts. Finally, a conflict-consensus mechanism standardizes these local discrepancies against the global context for robust deliberative judgment.Extensive experiments conducted on three real world datasets demonstrate that DCCF consistently outperforms state-of-the-art baselines, achieving an average accuracy improvement of 3.52\%.
Towards Understanding the Safety Boundaries of DeepSeek Models: Evaluation and Findings
Mar 19, 2025This study presents the first comprehensive safety evaluation of the DeepSeek models, focusing on evaluating the safety risks associated with their generated content. Our evaluation encompasses DeepSeek's latest generation of large language models, multimodal large language models, and text-to-image models, systematically examining their performance regarding unsafe content generation. Notably, we developed a bilingual (Chinese-English) safety evaluation dataset tailored to Chinese sociocultural contexts, enabling a more thorough evaluation of the safety capabilities of Chinese-developed models. Experimental results indicate that despite their strong general capabilities, DeepSeek models exhibit significant safety vulnerabilities across multiple risk dimensions, including algorithmic discrimination and sexual content. These findings provide crucial insights for understanding and improving the safety of large foundation models. Our code is available at https://github.com/NY1024/DeepSeek-Safety-Eval.
Utilizing Jailbreak Probability to Attack and Safeguard Multimodal LLMs
Mar 10, 2025Recently, Multimodal Large Language Models (MLLMs) have demonstrated their superior ability in understanding multimodal contents. However, they remain vulnerable to jailbreak attacks, which exploit weaknesses in their safety alignment to generate harmful responses. Previous studies categorize jailbreaks as successful or failed based on whether responses contain malicious content. However, given the stochastic nature of MLLM responses, this binary classification of an input's ability to jailbreak MLLMs is inappropriate. Derived from this viewpoint, we introduce jailbreak probability to quantify the jailbreak potential of an input, which represents the likelihood that MLLMs generated a malicious response when prompted with this input. We approximate this probability through multiple queries to MLLMs. After modeling the relationship between input hidden states and their corresponding jailbreak probability using Jailbreak Probability Prediction Network (JPPN), we use continuous jailbreak probability for optimization. Specifically, we propose Jailbreak-Probability-based Attack (JPA) that optimizes adversarial perturbations on inputs to maximize jailbreak probability. To counteract attacks, we also propose two defensive methods: Jailbreak-Probability-based Finetuning (JPF) and Jailbreak-Probability-based Defensive Noise (JPDN), which minimizes jailbreak probability in the MLLM parameters and input space, respectively. Extensive experiments show that (1) JPA yields improvements (up to 28.38\%) under both white and black box settings compared to previous methods with small perturbation bounds and few iterations. (2) JPF and JPDN significantly reduce jailbreaks by at most over 60\%. Both of the above results demonstrate the significance of introducing jailbreak probability to make nuanced distinctions among input jailbreak abilities.
Multi-Turn Context Jailbreak Attack on Large Language Models From First Principles
Aug 08, 2024Large language models (LLMs) have significantly enhanced the performance of numerous applications, from intelligent conversations to text generation. However, their inherent security vulnerabilities have become an increasingly significant challenge, especially with respect to jailbreak attacks. Attackers can circumvent the security mechanisms of these LLMs, breaching security constraints and causing harmful outputs. Focusing on multi-turn semantic jailbreak attacks, we observe that existing methods lack specific considerations for the role of multiturn dialogues in attack strategies, leading to semantic deviations during continuous interactions. Therefore, in this paper, we establish a theoretical foundation for multi-turn attacks by considering their support in jailbreak attacks, and based on this, propose a context-based contextual fusion black-box jailbreak attack method, named Context Fusion Attack (CFA). This method approach involves filtering and extracting key terms from the target, constructing contextual scenarios around these terms, dynamically integrating the target into the scenarios, replacing malicious key terms within the target, and thereby concealing the direct malicious intent. Through comparisons on various mainstream LLMs and red team datasets, we have demonstrated CFA's superior success rate, divergence, and harmfulness compared to other multi-turn attack strategies, particularly showcasing significant advantages on Llama3 and GPT-4.
ConFL: Constraint-guided Fuzzing for Machine Learning Framework
Jul 11, 2023As machine learning gains prominence in various sectors of society for automated decision-making, concerns have risen regarding potential vulnerabilities in machine learning (ML) frameworks. Nevertheless, testing these frameworks is a daunting task due to their intricate implementation. Previous research on fuzzing ML frameworks has struggled to effectively extract input constraints and generate valid inputs, leading to extended fuzzing durations for deep execution or revealing the target crash. In this paper, we propose ConFL, a constraint-guided fuzzer for ML frameworks. ConFL automatically extracting constraints from kernel codes without the need for any prior knowledge. Guided by the constraints, ConFL is able to generate valid inputs that can pass the verification and explore deeper paths of kernel codes. In addition, we design a grouping technique to boost the fuzzing efficiency. To demonstrate the effectiveness of ConFL, we evaluated its performance mainly on Tensorflow. We find that ConFL is able to cover more code lines, and generate more valid inputs than state-of-the-art (SOTA) fuzzers. More importantly, ConFL found 84 previously unknown vulnerabilities in different versions of Tensorflow, all of which were assigned with new CVE ids, of which 3 were critical-severity and 13 were high-severity. We also extended ConFL to test PyTorch and Paddle, 7 vulnerabilities are found to date.
Wolf in Sheep's Clothing - The Downscaling Attack Against Deep Learning Applications
Dec 21, 2017



This paper considers security risks buried in the data processing pipeline in common deep learning applications. Deep learning models usually assume a fixed scale for their training and input data. To allow deep learning applications to handle a wide range of input data, popular frameworks, such as Caffe, TensorFlow, and Torch, all provide data scaling functions to resize input to the dimensions used by deep learning models. Image scaling algorithms are intended to preserve the visual features of an image after scaling. However, common image scaling algorithms are not designed to handle human crafted images. Attackers can make the scaling outputs look dramatically different from the corresponding input images. This paper presents a downscaling attack that targets the data scaling process in deep learning applications. By carefully crafting input data that mismatches with the dimension used by deep learning models, attackers can create deceiving effects. A deep learning application effectively consumes data that are not the same as those presented to users. The visual inconsistency enables practical evasion and data poisoning attacks to deep learning applications. This paper presents proof-of-concept attack samples to popular deep-learning-based image classification applications. To address the downscaling attacks, the paper also suggests multiple potential mitigation strategies.