 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards the Holographic Characteristic of LLMs for Efficient Short-text Generation
Jan 30, 2026The recent advancements in Large Language Models (LLMs) have attracted interest in exploring their in-context learning abilities and chain-of-thought capabilities. However, there are few studies investigating the specific traits related to the powerful generation capacity of LLMs. This paper aims to delve into the generation characteristics exhibited by LLMs. Through our investigation, we have discovered that language models tend to capture target-side keywords at the beginning of the generation process. We name this phenomenon the Holographic Characteristic of language models. For the purpose of exploring this characteristic and further improving the inference efficiency of language models, we propose a plugin called HOLO, which leverages the Holographic Characteristic to extract target-side keywords from language models within a limited number of generation steps and complements the sentence with a parallel lexically constrained text generation method. To verify the effectiveness of HOLO, we conduct massive experiments on language models of varying architectures and scales in the short-text generation scenario. The results demonstrate that HOLO achieves comparable performance to the baselines in terms of both automatic and human-like evaluation metrics and highlight the potential of the Holographic Characteristic.
TextlessRAG: End-to-End Visual Document RAG by Speech Without Text
Sep 10, 2025Document images encapsulate a wealth of knowledge, while the portability of spoken queries enables broader and flexible application scenarios. Yet, no prior work has explored knowledge base question answering over visual document images with queries provided directly in speech. We propose TextlessRAG, the first end-to-end framework for speech-based question answering over large-scale document images. Unlike prior methods, TextlessRAG eliminates ASR, TTS and OCR, directly interpreting speech, retrieving relevant visual knowledge, and generating answers in a fully textless pipeline. To further boost performance, we integrate a layout-aware reranking mechanism to refine retrieval. Experiments demonstrate substantial improvements in both efficiency and accuracy. To advance research in this direction, we also release the first bilingual speech--document RAG dataset, featuring Chinese and English voice queries paired with multimodal document content. Both the dataset and our pipeline will be made available at repository:https://github.com/xiepeijinhit-hue/textlessrag
BeMERC: Behavior-Aware MLLM-based Framework for Multimodal Emotion Recognition in Conversation
Mar 31, 2025Multimodal emotion recognition in conversation (MERC), the task of identifying the emotion label for each utterance in a conversation, is vital for developing empathetic machines. Current MLLM-based MERC studies focus mainly on capturing the speaker's textual or vocal characteristics, but ignore the significance of video-derived behavior information. Different from text and audio inputs, learning videos with rich facial expression, body language and posture, provides emotion trigger signals to the models for more accurate emotion predictions. In this paper, we propose a novel behavior-aware MLLM-based framework (BeMERC) to incorporate speaker's behaviors, including subtle facial micro-expression, body language and posture, into a vanilla MLLM-based MERC model, thereby facilitating the modeling of emotional dynamics during a conversation. Furthermore, BeMERC adopts a two-stage instruction tuning strategy to extend the model to the conversations scenario for end-to-end training of a MERC predictor. Experiments demonstrate that BeMERC achieves superior performance than the state-of-the-art methods on two benchmark datasets, and also provides a detailed discussion on the significance of video-derived behavior information in MERC.
Expand VSR Benchmark for VLLM to Expertize in Spatial Rules
Dec 24, 2024



Distinguishing spatial relations is a basic part of human cognition which requires fine-grained perception on cross-instance. Although benchmarks like MME, MMBench and SEED comprehensively have evaluated various capabilities which already include visual spatial reasoning(VSR). There is still a lack of sufficient quantity and quality evaluation and optimization datasets for Vision Large Language Models(VLLMs) specifically targeting visual positional reasoning. To handle this, we first diagnosed current VLLMs with the VSR dataset and proposed a unified test set. We found current VLLMs to exhibit a contradiction of over-sensitivity to language instructions and under-sensitivity to visual positional information. By expanding the original benchmark from two aspects of tunning data and model structure, we mitigated this phenomenon. To our knowledge, we expanded spatially positioned image data controllably using diffusion models for the first time and integrated original visual encoding(CLIP) with other 3 powerful visual encoders(SigLIP, SAM and DINO). After conducting combination experiments on scaling data and models, we obtained a VLLM VSR Expert(VSRE) that not only generalizes better to different instructions but also accurately distinguishes differences in visual positional information. VSRE achieved over a 27\% increase in accuracy on the VSR test set. It becomes a performant VLLM on the position reasoning of both the VSR dataset and relevant subsets of other evaluation benchmarks. We open-sourced the expanded model with data and Appendix at \url{https://github.com/peijin360/vsre} and hope it will accelerate advancements in VLLM on VSR learning.
Spatial-Aware Efficient Projector for MLLMs via Multi-Layer Feature Aggregation
Oct 14, 2024The projector plays a crucial role in multi-modal language models (MLLMs). The number of visual tokens it outputs affects the efficiency of the MLLM, while the quality of the visual tokens influences the visual understanding capabilities of the MLLM. Current explorations on the projector focus on reducing the number of visual tokens to improve efficiency, often overlooking the inherent spatial discrepancy between the serialized 2-dimensional visual token sequences and natural language token sequences. A Spatial-Aware Efficient Projector (SAEP) is proposed to address this issue. In detail, our SAEP method employs an modified separable depthwise convolution module on multi-layer visual features to enhance the spatial information of visual tokens. As a result, our SAEP method can not only largely reduce the number of visual tokens by 75\%, but also significantly improve the multimodal spatial understanding capability of MLLMs. Moreover, compared to existing projectors, our SAEP gets best performances on massive multimodal evaluation benchmarks, which denotes its effectiveness on bridging the modality gap.
Faithful Knowledge Graph Explanations for Commonsense Reasoning
Oct 07, 2023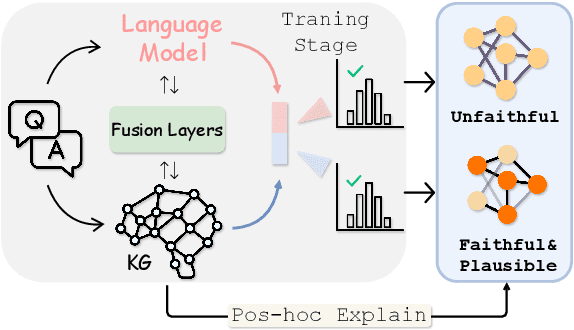


While fusing language models (LMs) and knowledge graphs (KGs) has become common in commonsense question answering research, enabling faithful chain-of-thought explanations in these models remains an open problem. One major weakness of current KG-based explanation techniques is that they overlook the faithfulness of generated explanations during evaluation. To address this gap, we make two main contributions: (1) We propose and validate two quantitative metrics - graph consistency and graph fidelity - to measure the faithfulness of KG-based explanations. (2) We introduce Consistent GNN (CGNN), a novel training method that adds a consistency regularization term to improve explanation faithfulness. Our analysis shows that predictions from KG often diverge from original model predictions. The proposed CGNN approach boosts consistency and fidelity, demonstrating its potential for producing more faithful explanations. Our work emphasises the importance of explicitly evaluating suggest a path forward for developing architectures for faithful graph-based explanations.
Pre-training Language Models with Deterministic Factual Knowledge
Oct 20, 2022
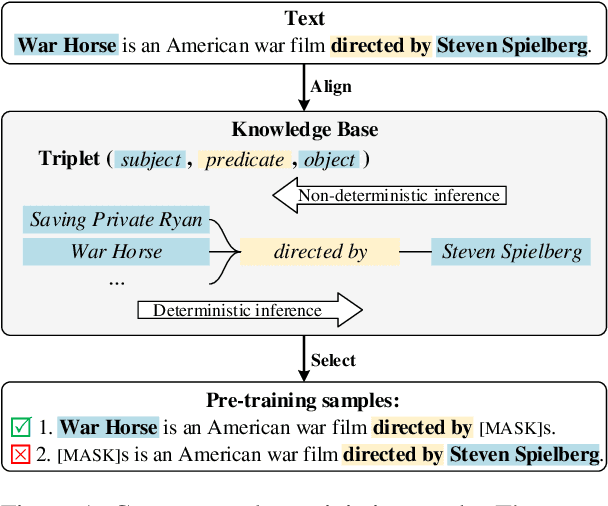

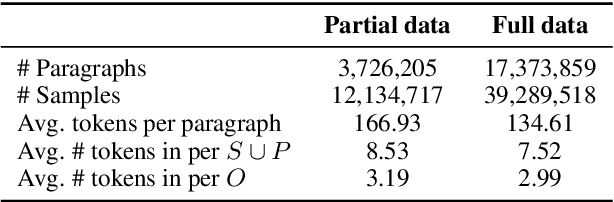
Previous works show that Pre-trained Language Models (PLMs) can capture factual knowledge. However, some analyses reveal that PLMs fail to perform it robustly, e.g., being sensitive to the changes of prompts when extracting factual knowledge. To mitigate this issue, we propose to let PLMs learn the deterministic relationship between the remaining context and the masked content. The deterministic relationship ensures that the masked factual content can be deterministically inferable based on the existing clues in the context. That would provide more stable patterns for PLMs to capture factual knowledge than randomly masking. Two pre-training tasks are further introduced to motivate PLMs to rely on the deterministic relationship when filling masks. Specifically, we use an external Knowledge Base (KB) to identify deterministic relationships and continuously pre-train PLMs with the proposed methods. The factual knowledge probing experiments indicate that the continuously pre-trained PLMs achieve better robustness in factual knowledge capturing. Further experiments on question-answering datasets show that trying to learn a deterministic relationship with the proposed methods can also help other knowledge-intensive tasks.
How Pre-trained Language Models Capture Factual Knowledge? A Causal-Inspired Analysis
Mar 31, 2022
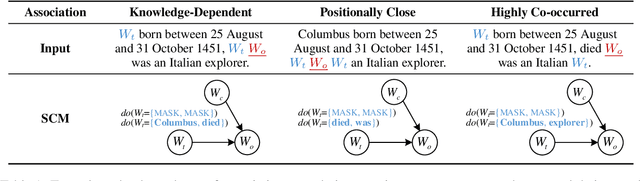
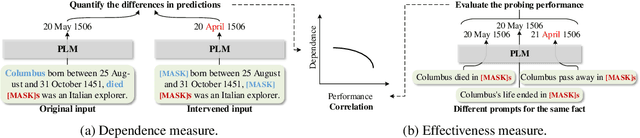
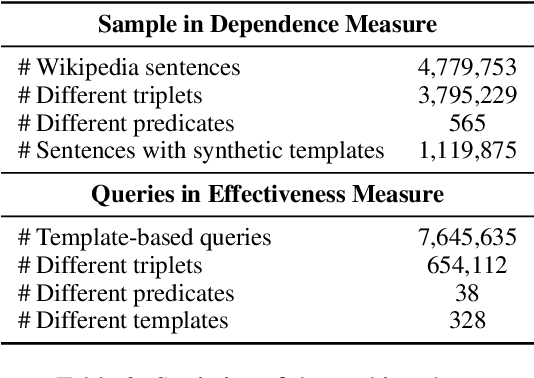
Recently, there has been a trend to investigate the factual knowledge captured by Pre-trained Language Models (PLMs). Many works show the PLMs' ability to fill in the missing factual words in cloze-style prompts such as "Dante was born in [MASK]." However, it is still a mystery how PLMs generate the results correctly: relying on effective clues or shortcut patterns? We try to answer this question by a causal-inspired analysis that quantitatively measures and evaluates the word-level patterns that PLMs depend on to generate the missing words. We check the words that have three typical associations with the missing words: knowledge-dependent, positionally close, and highly co-occurred. Our analysis shows: (1) PLMs generate the missing factual words more by the positionally close and highly co-occurred words than the knowledge-dependent words; (2) the dependence on the knowledge-dependent words is more effective than the positionally close and highly co-occurred words. Accordingly, we conclude that the PLMs capture the factual knowledge ineffectively because of depending on the inadequate associations.
Integrating Regular Expressions with Neural Networks via DFA
Sep 07, 2021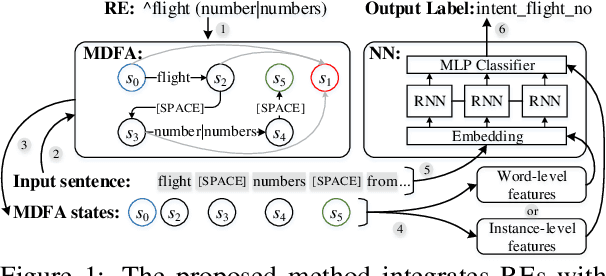
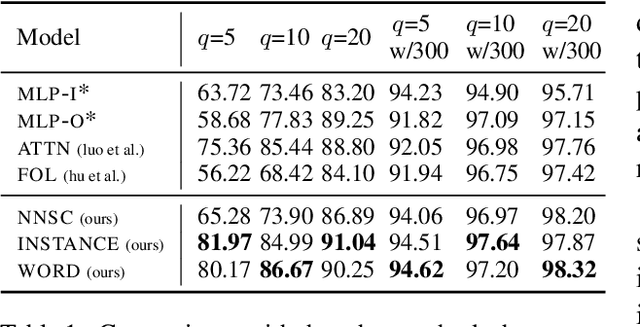
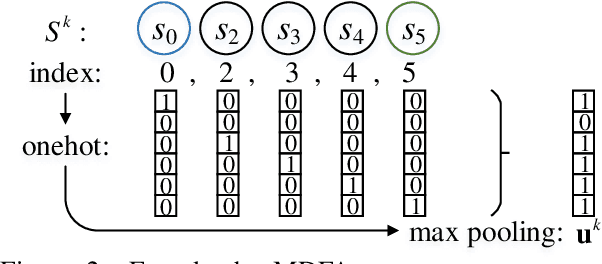
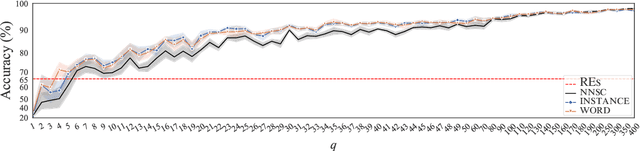
Human-designed rules are widely used to build industry applications. However, it is infeasible to maintain thousands of such hand-crafted rules. So it is very important to integrate the rule knowledge into neural networks to build a hybrid model that achieves better performance. Specifically, the human-designed rules are formulated as Regular Expressions (REs), from which the equivalent Minimal Deterministic Finite Automatons (MDFAs) are constructed. We propose to use the MDFA as an intermediate model to capture the matched RE patterns as rule-based features for each input sentence and introduce these additional features into neural networks. We evaluate the proposed method on the ATIS intent classification task. The experiment results show that the proposed method achieves the best performance compared to neural networks and four other methods that combine REs and neural networks when the training dataset is relatively small.
HopRetriever: Retrieve Hops over Wikipedia to Answer Complex Questions
Dec 31, 2020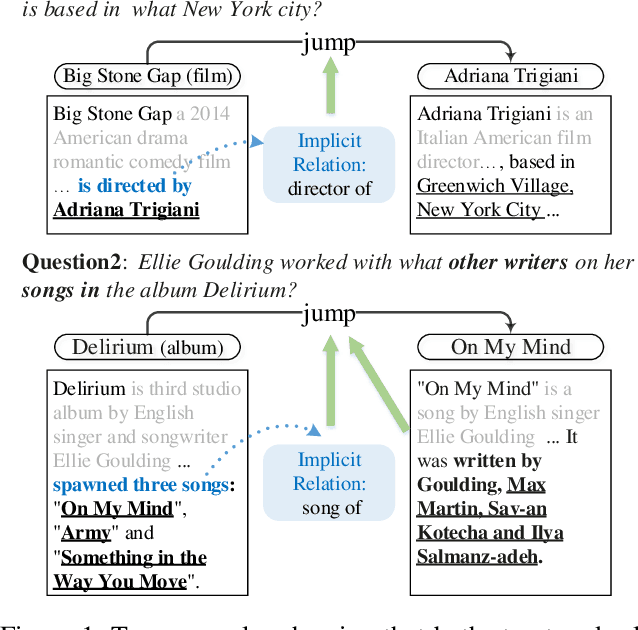

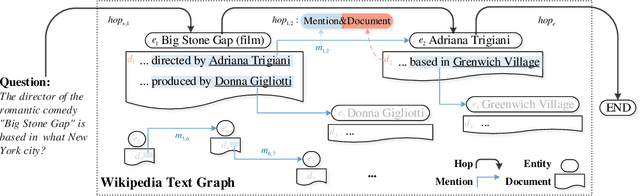

Collecting supporting evidence from large corpora of text (e.g., Wikipedia) is of great challenge for open-domain Question Answering (QA). Especially, for multi-hop open-domain QA, scattered evidence pieces are required to be gathered together to support the answer extraction. In this paper, we propose a new retrieval target, hop, to collect the hidden reasoning evidence from Wikipedia for complex question answering. Specifically, the hop in this paper is defined as the combination of a hyperlink and the corresponding outbound link document. The hyperlink is encoded as the mention embedding which models the structured knowledge of how the outbound link entity is mentioned in the textual context, and the corresponding outbound link document is encoded as the document embedding representing the unstructured knowledge within it. Accordingly, we build HopRetriever which retrieves hops over Wikipedia to answer complex questions. Experiments on the HotpotQA dataset demonstrate that HopRetriever outperforms previously published evidence retrieval methods by large margins. Moreover, our approach also yields quantifiable interpretations of the evidence collection process.