 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-Slow Efficient Training for Multimodal Large Language Models via Visual Token Pruning
Feb 03, 2026Multimodal Large Language Models (MLLMs) suffer from severe training inefficiency issue, which is associated with their massive model sizes and visual token numbers. Existing efforts in efficient training focus on reducing model sizes or trainable parameters. Inspired by the success of Visual Token Pruning (VTP) in improving inference efficiency, we are exploring another substantial research direction for efficient training by reducing visual tokens. However, applying VTP at the training stage results in a training-inference mismatch: pruning-trained models perform poorly when inferring on non-pruned full visual token sequences. To close this gap, we propose DualSpeed, a fast-slow framework for efficient training of MLLMs. The fast-mode is the primary mode, which incorporates existing VTP methods as plugins to reduce visual tokens, along with a mode isolator to isolate the model's behaviors. The slow-mode is the auxiliary mode, where the model is trained on full visual sequences to retain training-inference consistency. To boost its training, it further leverages self-distillation to learn from the sufficiently trained fast-mode. Together, DualSpeed can achieve both training efficiency and non-degraded performance. Experiments show DualSpeed accelerates the training of LLaVA-1.5 by 2.1$\times$ and LLaVA-NeXT by 4.0$\times$, retaining over 99% performance. Code: https://github.com/dingkun-zhang/DualSpeed
Merge then Realign: Simple and Effective Modality-Incremental Continual Learning for Multimodal LLMs
Mar 08, 2025Recent advances in Multimodal Large Language Models (MLLMs) have enhanced their versatility as they integrate a growing number of modalities. Considering the heavy cost of training MLLMs, it is necessary to reuse the existing ones and further extend them to more modalities through Modality-incremental Continual Learning (MCL). However, this often comes with a performance degradation in the previously learned modalities. In this work, we revisit the MCL and investigate a more severe issue it faces in contrast to traditional continual learning, that its degradation comes not only from catastrophic forgetting but also from the misalignment between the modality-agnostic and modality-specific components. To address this problem, we propose an elegantly simple MCL paradigm called "MErge then ReAlign" (MERA). Our method avoids introducing heavy training overhead or modifying the model architecture, hence is easy to deploy and highly reusable in the MLLM community. Extensive experiments demonstrate that, despite the simplicity of MERA, it shows impressive performance, holding up to a 99.84% Backward Relative Gain when extending to four modalities, achieving a nearly lossless MCL performance.
LAPTOP-Diff: Layer Pruning and Normalized Distillation for Compressing Diffusion Models
Apr 19, 2024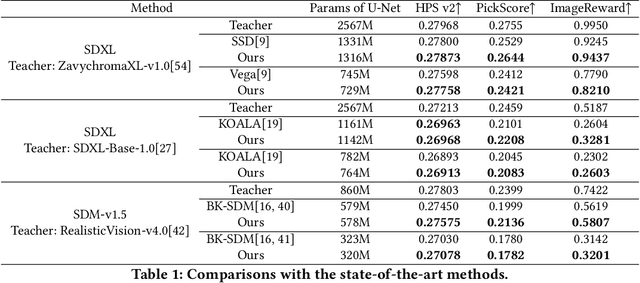
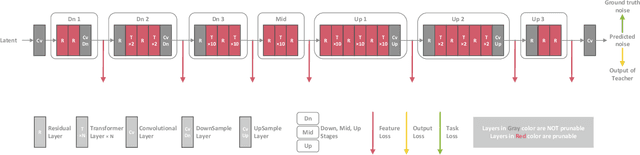
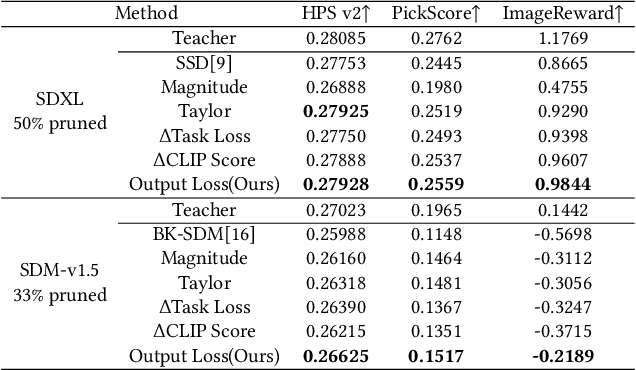
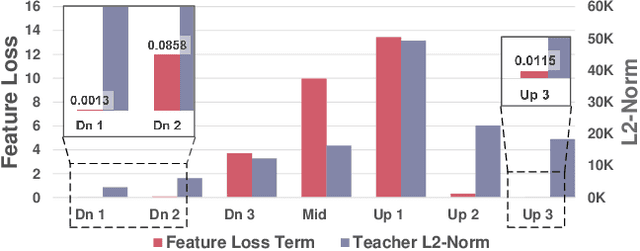
In the era of AIGC, the demand for low-budget or even on-device applications of diffusion models emerged. In terms of compressing the Stable Diffusion models (SDMs), several approaches have been proposed, and most of them leveraged the handcrafted layer removal methods to obtain smaller U-Nets, along with knowledge distillation to recover the network performance. However, such a handcrafting manner of layer removal is inefficient and lacks scalability and generalization, and the feature distillation employed in the retraining phase faces an imbalance issue that a few numerically significant feature loss terms dominate over others throughout the retraining process. To this end, we proposed the layer pruning and normalized distillation for compressing diffusion models (LAPTOP-Diff). We, 1) introduced the layer pruning method to compress SDM's U-Net automatically and proposed an effective one-shot pruning criterion whose one-shot performance is guaranteed by its good additivity property, surpassing other layer pruning and handcrafted layer removal methods, 2) proposed the normalized feature distillation for retraining, alleviated the imbalance issue. Using the proposed LAPTOP-Diff, we compressed the U-Nets of SDXL and SDM-v1.5 for the most advanced performance, achieving a minimal 4.0% decline in PickScore at a pruning ratio of 50% while the comparative methods' minimal PickScore decline is 8.2%. We will release our code.