 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFG-CLTP: Fine-Grained Contrastive Language Tactile Pretraining for Robotic Manipulation
Mar 11, 2026Recent advancements in integrating tactile sensing into vision-language-action (VLA) models have demonstrated transformative potential for robotic perception. However, existing tactile representations predominantly rely on qualitative descriptors (e.g., texture), neglecting quantitative contact states such as force magnitude, contact geometry, and principal axis orientation, which are indispensable for fine-grained manipulation. To bridge this gap, we propose FG-CLTP, a fine-grained contrastive language tactile pretraining framework. We first introduce a novel dataset comprising over 100k tactile 3D point cloud-language pairs that explicitly capture multidimensional contact states from the sensor's perspective. We then implement a discretized numerical tokenization mechanism to achieve quantitative-semantic alignment, effectively injecting explicit physical metrics into the multimodal feature space. The proposed FG-CLTP model yields a 95.9% classification accuracy and reduces the regression error (MAE) by 52.6% compared to state-of-the-art methods. Furthermore, the integration of 3D point cloud representations establishes a sensor-agnostic foundation with a minimal sim-to-real gap of 3.5%. Building upon this fine-grained representation, we develop a 3D tactile-language-action (3D-TLA) architecture driven by a flow matching policy to enable multimodal reasoning and control. Extensive experiments demonstrate that our framework significantly outperforms strong baselines in contact-rich manipulation tasks, providing a robust and generalizable foundation for tactile-language-action models.
Emu3.5: Native Multimodal Models are World Learners
Oct 30, 2025We introduce Emu3.5, a large-scale multimodal world model that natively predicts the next state across vision and language. Emu3.5 is pre-trained end-to-end with a unified next-token prediction objective on a corpus of vision-language interleaved data containing over 10 trillion tokens, primarily derived from sequential frames and transcripts of internet videos. The model naturally accepts interleaved vision-language inputs and generates interleaved vision-language outputs. Emu3.5 is further post-trained with large-scale reinforcement learning to enhance multimodal reasoning and generation. To improve inference efficiency, we propose Discrete Diffusion Adaptation (DiDA), which converts token-by-token decoding into bidirectional parallel prediction, accelerating per-image inference by about 20x without sacrificing performance. Emu3.5 exhibits strong native multimodal capabilities, including long-horizon vision-language generation, any-to-image (X2I) generation, and complex text-rich image generation. It also exhibits generalizable world-modeling abilities, enabling spatiotemporally consistent world exploration and open-world embodied manipulation across diverse scenarios and tasks. For comparison, Emu3.5 achieves performance comparable to Gemini 2.5 Flash Image (Nano Banana) on image generation and editing tasks and demonstrates superior results on a suite of interleaved generation tasks. We open-source Emu3.5 at https://github.com/baaivision/Emu3.5 to support community research.
From Local Details to Global Context: Advancing Vision-Language Models with Attention-Based Selection
May 19, 2025Pretrained vision-language models (VLMs), e.g., CLIP, demonstrate impressive zero-shot capabilities on downstream tasks. Prior research highlights the crucial role of visual augmentation techniques, like random cropping, in alignment with fine-grained class descriptions generated by large language models (LLMs), significantly enhancing zero-shot performance by incorporating multi-view information. However, the inherent randomness of these augmentations can inevitably introduce background artifacts and cause models to overly focus on local details, compromising global semantic understanding. To address these issues, we propose an \textbf{A}ttention-\textbf{B}ased \textbf{S}election (\textbf{ABS}) method from local details to global context, which applies attention-guided cropping in both raw images and feature space, supplement global semantic information through strategic feature selection. Additionally, we introduce a soft matching technique to effectively filter LLM descriptions for better alignment. \textbf{ABS} achieves state-of-the-art performance on out-of-distribution generalization and zero-shot classification tasks. Notably, \textbf{ABS} is training-free and even rivals few-shot and test-time adaptation methods. Our code is available at \href{https://github.com/BIT-DA/ABS}{\textcolor{darkgreen}{https://github.com/BIT-DA/ABS}}.
CLTP: Contrastive Language-Tactile Pre-training for 3D Contact Geometry Understanding
May 13, 2025Recent advancements in integrating tactile sensing with vision-language models (VLMs) have demonstrated remarkable potential for robotic multimodal perception. However, existing tactile descriptions remain limited to superficial attributes like texture, neglecting critical contact states essential for robotic manipulation. To bridge this gap, we propose CLTP, an intuitive and effective language tactile pretraining framework that aligns tactile 3D point clouds with natural language in various contact scenarios, thus enabling contact-state-aware tactile language understanding for contact-rich manipulation tasks. We first collect a novel dataset of 50k+ tactile 3D point cloud-language pairs, where descriptions explicitly capture multidimensional contact states (e.g., contact location, shape, and force) from the tactile sensor's perspective. CLTP leverages a pre-aligned and frozen vision-language feature space to bridge holistic textual and tactile modalities. Experiments validate its superiority in three downstream tasks: zero-shot 3D classification, contact state classification, and tactile 3D large language model (LLM) interaction. To the best of our knowledge, this is the first study to align tactile and language representations from the contact state perspective for manipulation tasks, providing great potential for tactile-language-action model learning. Code and datasets are open-sourced at https://sites.google.com/view/cltp/.
Consensus-based Distributed Quantum Kernel Learning for Speech Recognition
Sep 09, 2024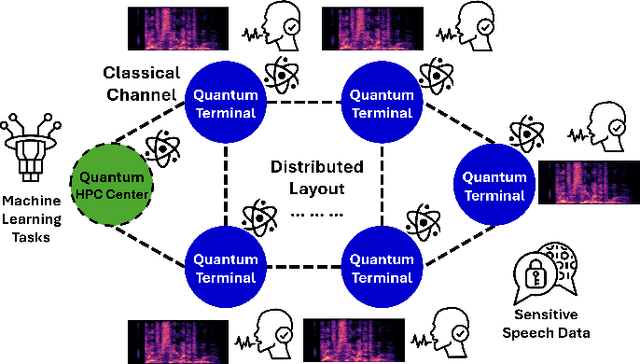
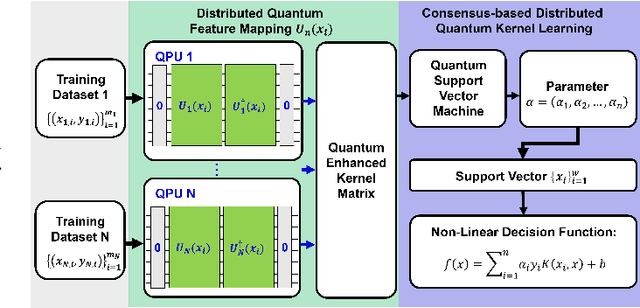
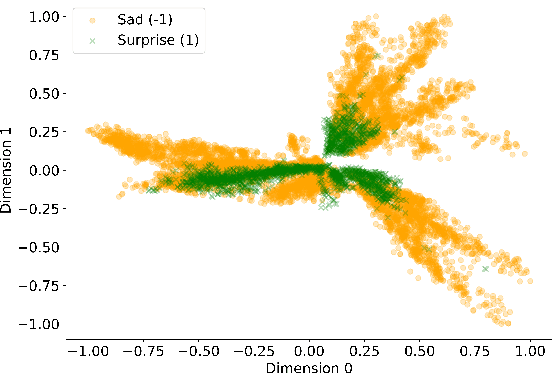
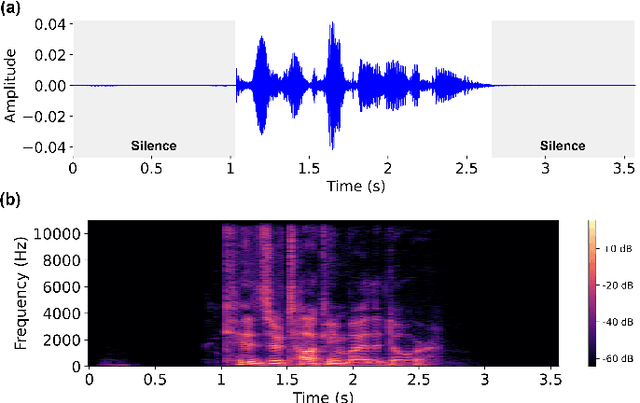
This paper presents a Consensus-based Distributed Quantum Kernel Learning (CDQKL) framework aimed at improving speech recognition through distributed quantum computing.CDQKL addresses the challenges of scalability and data privacy in centralized quantum kernel learning. It does this by distributing computational tasks across quantum terminals, which are connected through classical channels. This approach enables the exchange of model parameters without sharing local training data, thereby maintaining data privacy and enhancing computational efficiency. Experimental evaluations on benchmark speech emotion recognition datasets demonstrate that CDQKL achieves competitive classification accuracy and scalability compared to centralized and local quantum kernel learning models. The distributed nature of CDQKL offers advantages in privacy preservation and computational efficiency, making it suitable for data-sensitive fields such as telecommunications, automotive, and finance. The findings suggest that CDQKL can effectively leverage distributed quantum computing for large-scale machine-learning tasks.
Learning Modality Knowledge Alignment for Cross-Modality Transfer
Jun 27, 2024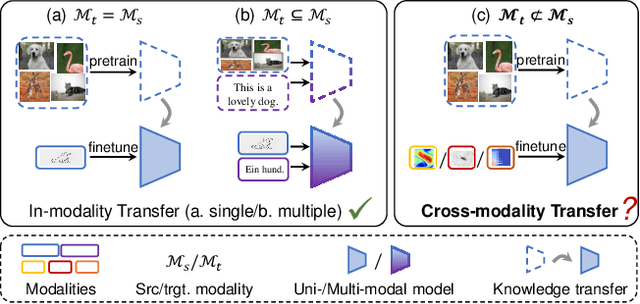
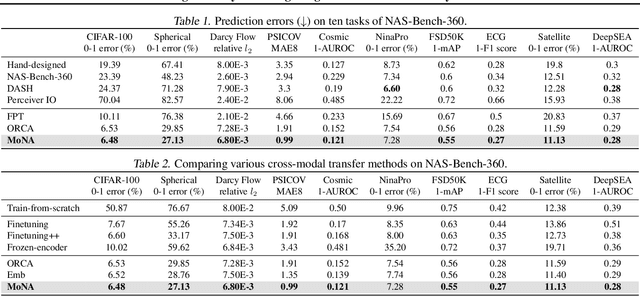
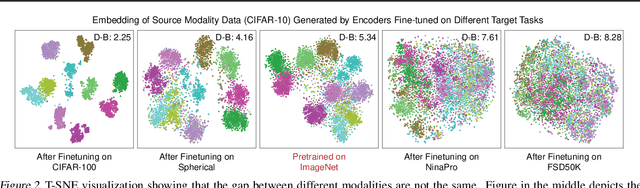
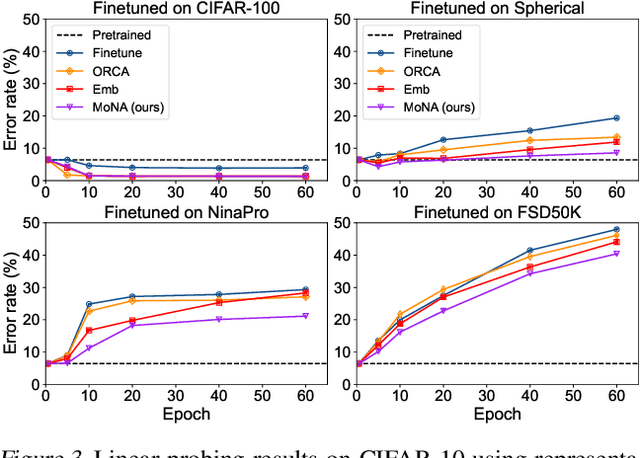
Cross-modality transfer aims to leverage large pretrained models to complete tasks that may not belong to the modality of pretraining data. Existing works achieve certain success in extending classical finetuning to cross-modal scenarios, yet we still lack understanding about the influence of modality gap on the transfer. In this work, a series of experiments focusing on the source representation quality during transfer are conducted, revealing the connection between larger modality gap and lesser knowledge reuse which means ineffective transfer. We then formalize the gap as the knowledge misalignment between modalities using conditional distribution P(Y|X). Towards this problem, we present Modality kNowledge Alignment (MoNA), a meta-learning approach that learns target data transformation to reduce the modality knowledge discrepancy ahead of the transfer. Experiments show that out method enables better reuse of source modality knowledge in cross-modality transfer, which leads to improvements upon existing finetuning methods.
Enhancing Cross-Modal Fine-Tuning with Gradually Intermediate Modality Generation
Jun 13, 2024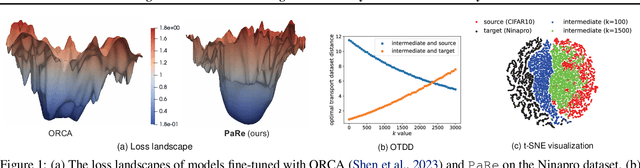
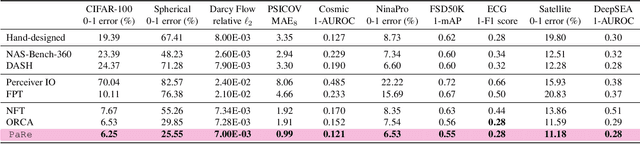
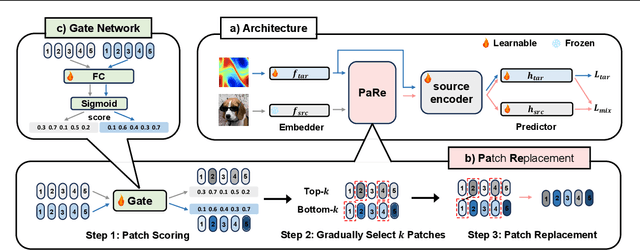

Large-scale pretrained models have proven immensely valuable in handling data-intensive modalities like text and image. However, fine-tuning these models for certain specialized modalities, such as protein sequence and cosmic ray, poses challenges due to the significant modality discrepancy and scarcity of labeled data. In this paper, we propose an end-to-end method, PaRe, to enhance cross-modal fine-tuning, aiming to transfer a large-scale pretrained model to various target modalities. PaRe employs a gating mechanism to select key patches from both source and target data. Through a modality-agnostic Patch Replacement scheme, these patches are preserved and combined to construct data-rich intermediate modalities ranging from easy to hard. By gradually intermediate modality generation, we can not only effectively bridge the modality gap to enhance stability and transferability of cross-modal fine-tuning, but also address the challenge of limited data in the target modality by leveraging enriched intermediate modality data. Compared with hand-designed, general-purpose, task-specific, and state-of-the-art cross-modal fine-tuning approaches, PaRe demonstrates superior performance across three challenging benchmarks, encompassing more than ten modalities.
Language Semantic Graph Guided Data-Efficient Learning
Nov 15, 2023



Developing generalizable models that can effectively learn from limited data and with minimal reliance on human supervision is a significant objective within the machine learning community, particularly in the era of deep neural networks. Therefore, to achieve data-efficient learning, researchers typically explore approaches that can leverage more related or unlabeled data without necessitating additional manual labeling efforts, such as Semi-Supervised Learning (SSL), Transfer Learning (TL), and Data Augmentation (DA). SSL leverages unlabeled data in the training process, while TL enables the transfer of expertise from related data distributions. DA broadens the dataset by synthesizing new data from existing examples. However, the significance of additional knowledge contained within labels has been largely overlooked in research. In this paper, we propose a novel perspective on data efficiency that involves exploiting the semantic information contained in the labels of the available data. Specifically, we introduce a Language Semantic Graph (LSG) which is constructed from labels manifest as natural language descriptions. Upon this graph, an auxiliary graph neural network is trained to extract high-level semantic relations and then used to guide the training of the primary model, enabling more adequate utilization of label knowledge. Across image, video, and audio modalities, we utilize the LSG method in both TL and SSL scenarios and illustrate its versatility in significantly enhancing performance compared to other data-efficient learning approaches. Additionally, our in-depth analysis shows that the LSG method also expedites the training process.
Improving Uncertainty Quantification of Variance Networks by Tree-Structured Learning
Dec 24, 2022



To improve uncertainty quantification of variance networks, we propose a novel tree-structured local neural network model that partitions the feature space into multiple regions based on uncertainty heterogeneity. A tree is built upon giving the training data, whose leaf nodes represent different regions where region-specific neural networks are trained to predict both the mean and the variance for quantifying uncertainty. The proposed Uncertainty-Splitting Neural Regression Tree (USNRT) employs novel splitting criteria. At each node, a neural network is trained on the full data first, and a statistical test for the residuals is conducted to find the best split, corresponding to the two sub-regions with the most significant uncertainty heterogeneity. USNRT is computationally friendly because very few leaf nodes are sufficient and pruning is unnecessary. On extensive UCI datasets, in terms of both calibration and sharpness, USNRT shows superior performance compared to some recent popular methods for variance prediction, including vanilla variance network, deep ensemble, dropout-based methods, tree-based models, etc. Through comprehensive visualization and analysis, we uncover how USNRT works and show its merits.
Ensemble Multi-Quantile: Adaptively Flexible Distribution Prediction for Uncertainty Quantification
Nov 26, 2022



We propose a novel, succinct, and effective approach to quantify uncertainty in machine learning. It incorporates adaptively flexible distribution prediction for $\mathbb{P}(\mathbf{y}|\mathbf{X}=x)$ in regression tasks. For predicting this conditional distribution, its quantiles of probability levels spreading the interval $(0,1)$ are boosted by additive models which are designed by us with intuitions and interpretability. We seek an adaptive balance between the structural integrity and the flexibility for $\mathbb{P}(\mathbf{y}|\mathbf{X}=x)$, while Gaussian assumption results in a lack of flexibility for real data and highly flexible approaches (e.g., estimating the quantiles separately without a distribution structure) inevitably have drawbacks and may not lead to good generalization. This ensemble multi-quantiles approach called EMQ proposed by us is totally data-driven, and can gradually depart from Gaussian and discover the optimal conditional distribution in the boosting. On extensive regression tasks from UCI datasets, we show that EMQ achieves state-of-the-art performance comparing to many recent uncertainty quantification methods including Gaussian assumption-based, Bayesian methods, quantile regression-based, and traditional tree models, under the metrics of calibration, sharpness, and tail-side calibration. Visualization results show what we actually learn from the real data and how, illustrating the necessity and the merits of such an ensemble model.