 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Noisy Prompts: Saliency-Guided Prompt Distillation for Robust Segmentation with SAM
Apr 25, 2026Segmentation is central to clinical diagnosis and monitoring, yet the reliability of modern foundation models in medical imaging still depends on the availability of precise prompts. The Segment Anything Model (SAM) offers powerful zero-shot capabilities, although it collapses under the weak, generic, and noisy prompts that dominate real clinical workflows. In practice, annotations such as centerline points are coarse and ambiguous, often drifting across neighboring anatomy and misguiding SAM toward inconsistent or incomplete masks. We introduce SPD, a Saliency-Guided Prompt Distillation framework that converts these unreliable cues into robust guidance. SPD first learns data-driven anatomical priors through a lightweight saliency head to obtain confident localization maps. These priors then drive Contextual Prompt Distillation, which validates and enriches noisy prompts using cues from anatomically adjacent slices, producing a consensus prompt set that matches the behavior of expert reasoning. A Pairwise Slice Consistency objective further enforces local anatomical coherence during segmentation. Experiments on four challenging MRI and CT benchmarks demonstrate that SPD consistently outperforms existing SAM adaptations and supervised baselines, delivering large gains in both region-based and boundary-based metrics. SPD provides a practical and principled path toward reliable foundation model deployment in clinical environments where only imperfect prompts are available.
From Local Details to Global Context: Advancing Vision-Language Models with Attention-Based Selection
May 19, 2025Pretrained vision-language models (VLMs), e.g., CLIP, demonstrate impressive zero-shot capabilities on downstream tasks. Prior research highlights the crucial role of visual augmentation techniques, like random cropping, in alignment with fine-grained class descriptions generated by large language models (LLMs), significantly enhancing zero-shot performance by incorporating multi-view information. However, the inherent randomness of these augmentations can inevitably introduce background artifacts and cause models to overly focus on local details, compromising global semantic understanding. To address these issues, we propose an \textbf{A}ttention-\textbf{B}ased \textbf{S}election (\textbf{ABS}) method from local details to global context, which applies attention-guided cropping in both raw images and feature space, supplement global semantic information through strategic feature selection. Additionally, we introduce a soft matching technique to effectively filter LLM descriptions for better alignment. \textbf{ABS} achieves state-of-the-art performance on out-of-distribution generalization and zero-shot classification tasks. Notably, \textbf{ABS} is training-free and even rivals few-shot and test-time adaptation methods. Our code is available at \href{https://github.com/BIT-DA/ABS}{\textcolor{darkgreen}{https://github.com/BIT-DA/ABS}}.
Learning Modality Knowledge Alignment for Cross-Modality Transfer
Jun 27, 2024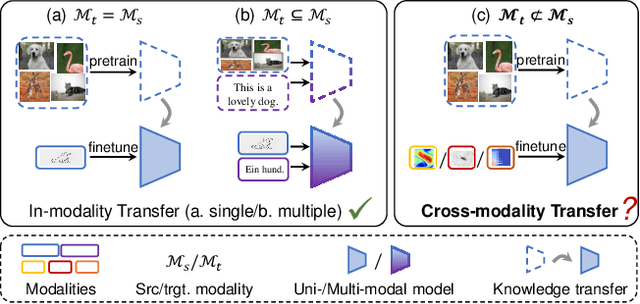
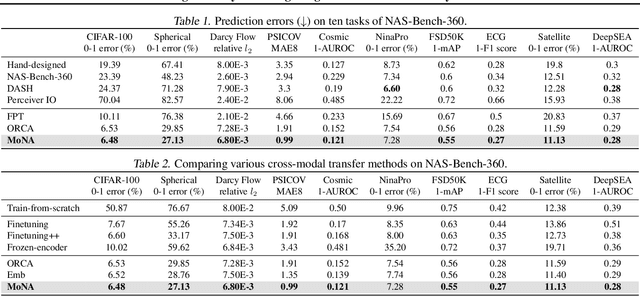
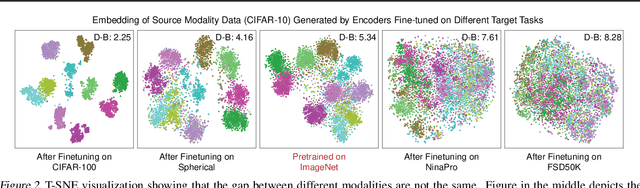
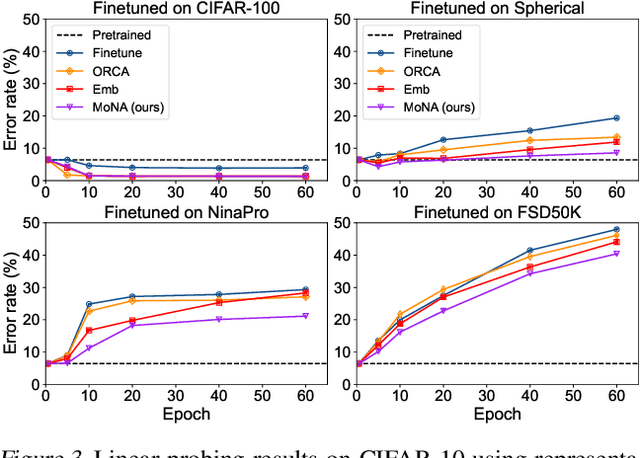
Cross-modality transfer aims to leverage large pretrained models to complete tasks that may not belong to the modality of pretraining data. Existing works achieve certain success in extending classical finetuning to cross-modal scenarios, yet we still lack understanding about the influence of modality gap on the transfer. In this work, a series of experiments focusing on the source representation quality during transfer are conducted, revealing the connection between larger modality gap and lesser knowledge reuse which means ineffective transfer. We then formalize the gap as the knowledge misalignment between modalities using conditional distribution P(Y|X). Towards this problem, we present Modality kNowledge Alignment (MoNA), a meta-learning approach that learns target data transformation to reduce the modality knowledge discrepancy ahead of the transfer. Experiments show that out method enables better reuse of source modality knowledge in cross-modality transfer, which leads to improvements upon existing finetuning methods.
Enhancing Cross-Modal Fine-Tuning with Gradually Intermediate Modality Generation
Jun 13, 2024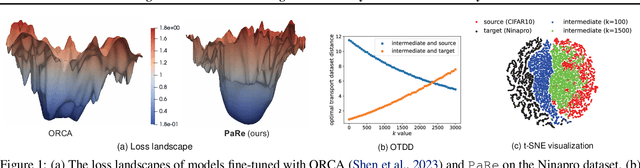
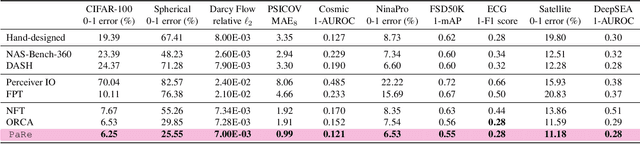
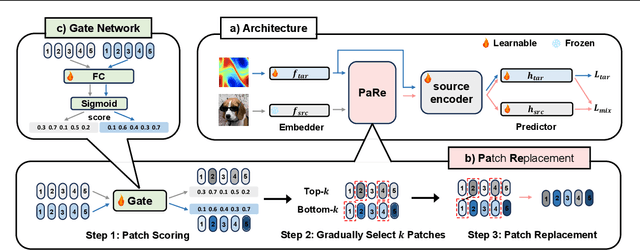

Large-scale pretrained models have proven immensely valuable in handling data-intensive modalities like text and image. However, fine-tuning these models for certain specialized modalities, such as protein sequence and cosmic ray, poses challenges due to the significant modality discrepancy and scarcity of labeled data. In this paper, we propose an end-to-end method, PaRe, to enhance cross-modal fine-tuning, aiming to transfer a large-scale pretrained model to various target modalities. PaRe employs a gating mechanism to select key patches from both source and target data. Through a modality-agnostic Patch Replacement scheme, these patches are preserved and combined to construct data-rich intermediate modalities ranging from easy to hard. By gradually intermediate modality generation, we can not only effectively bridge the modality gap to enhance stability and transferability of cross-modal fine-tuning, but also address the challenge of limited data in the target modality by leveraging enriched intermediate modality data. Compared with hand-designed, general-purpose, task-specific, and state-of-the-art cross-modal fine-tuning approaches, PaRe demonstrates superior performance across three challenging benchmarks, encompassing more than ten modalities.
Autonomous Catheterization with Open-source Simulator and Expert Trajectory
Jan 20, 2024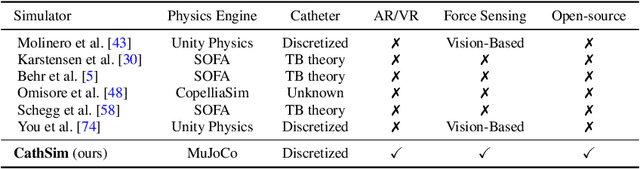
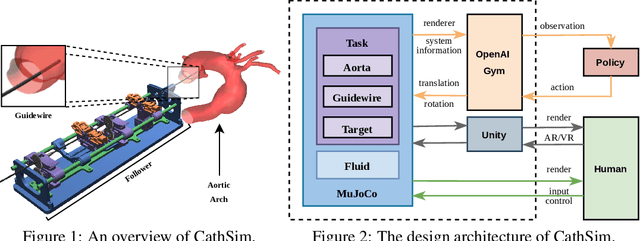
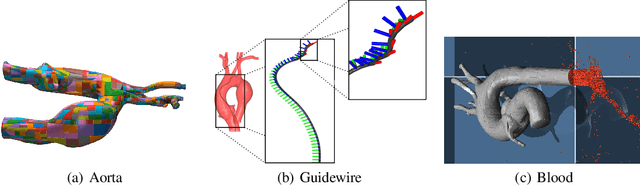
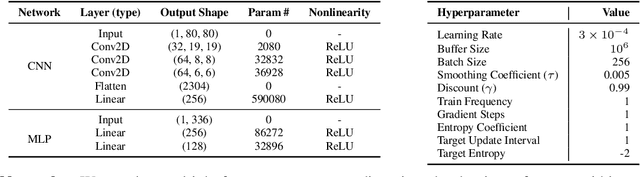
Endovascular robots have been actively developed in both academia and industry. However, progress toward autonomous catheterization is often hampered by the widespread use of closed-source simulators and physical phantoms. Additionally, the acquisition of large-scale datasets for training machine learning algorithms with endovascular robots is usually infeasible due to expensive medical procedures. In this chapter, we introduce CathSim, the first open-source simulator for endovascular intervention to address these limitations. CathSim emphasizes real-time performance to enable rapid development and testing of learning algorithms. We validate CathSim against the real robot and show that our simulator can successfully mimic the behavior of the real robot. Based on CathSim, we develop a multimodal expert navigation network and demonstrate its effectiveness in downstream endovascular navigation tasks. The intensive experimental results suggest that CathSim has the potential to significantly accelerate research in the autonomous catheterization field. Our project is publicly available at https://github.com/airvlab/cathsim.
Shape-Sensitive Loss for Catheter and Guidewire Segmentation
Nov 19, 2023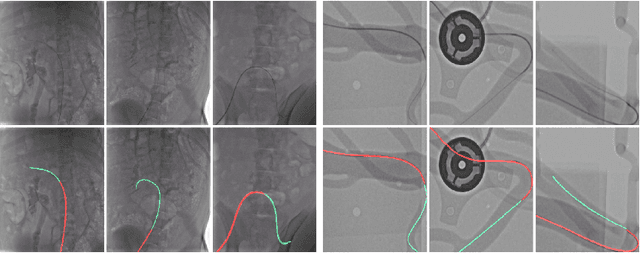
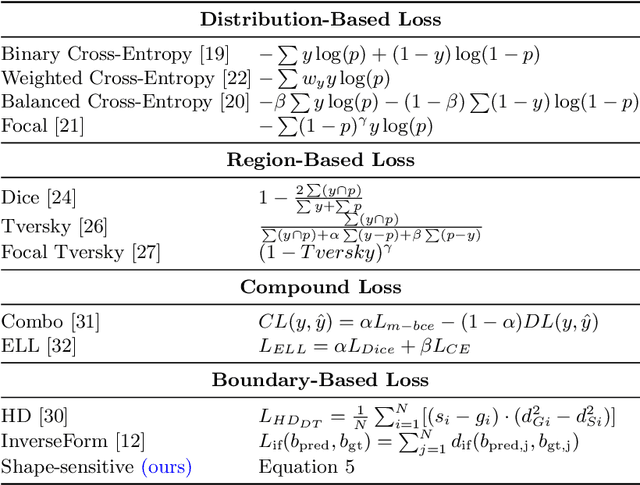
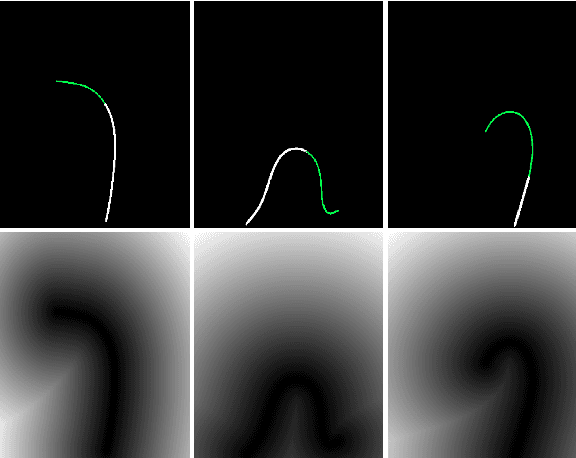
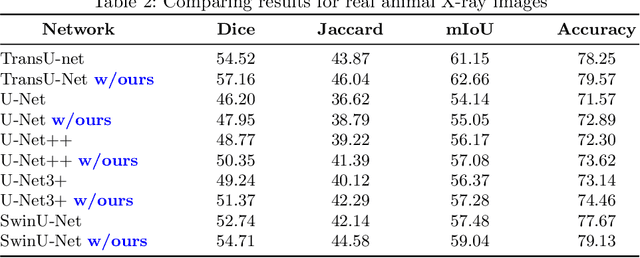
We introduce a shape-sensitive loss function for catheter and guidewire segmentation and utilize it in a vision transformer network to establish a new state-of-the-art result on a large-scale X-ray images dataset. We transform network-derived predictions and their corresponding ground truths into signed distance maps, thereby enabling any networks to concentrate on the essential boundaries rather than merely the overall contours. These SDMs are subjected to the vision transformer, efficiently producing high-dimensional feature vectors encapsulating critical image attributes. By computing the cosine similarity between these feature vectors, we gain a nuanced understanding of image similarity that goes beyond the limitations of traditional overlap-based measures. The advantages of our approach are manifold, ranging from scale and translation invariance to superior detection of subtle differences, thus ensuring precise localization and delineation of the medical instruments within the images. Comprehensive quantitative and qualitative analyses substantiate the significant enhancement in performance over existing baselines, demonstrating the promise held by our new shape-sensitive loss function for improving catheter and guidewire segmentation.
Language Semantic Graph Guided Data-Efficient Learning
Nov 15, 2023



Developing generalizable models that can effectively learn from limited data and with minimal reliance on human supervision is a significant objective within the machine learning community, particularly in the era of deep neural networks. Therefore, to achieve data-efficient learning, researchers typically explore approaches that can leverage more related or unlabeled data without necessitating additional manual labeling efforts, such as Semi-Supervised Learning (SSL), Transfer Learning (TL), and Data Augmentation (DA). SSL leverages unlabeled data in the training process, while TL enables the transfer of expertise from related data distributions. DA broadens the dataset by synthesizing new data from existing examples. However, the significance of additional knowledge contained within labels has been largely overlooked in research. In this paper, we propose a novel perspective on data efficiency that involves exploiting the semantic information contained in the labels of the available data. Specifically, we introduce a Language Semantic Graph (LSG) which is constructed from labels manifest as natural language descriptions. Upon this graph, an auxiliary graph neural network is trained to extract high-level semantic relations and then used to guide the training of the primary model, enabling more adequate utilization of label knowledge. Across image, video, and audio modalities, we utilize the LSG method in both TL and SSL scenarios and illustrate its versatility in significantly enhancing performance compared to other data-efficient learning approaches. Additionally, our in-depth analysis shows that the LSG method also expedites the training process.
Translating Simulation Images to X-ray Images via Multi-Scale Semantic Matching
Apr 16, 2023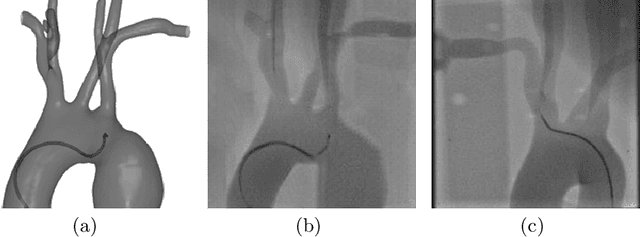
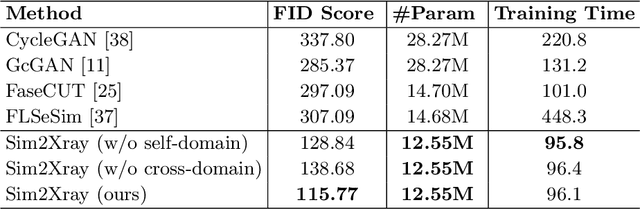
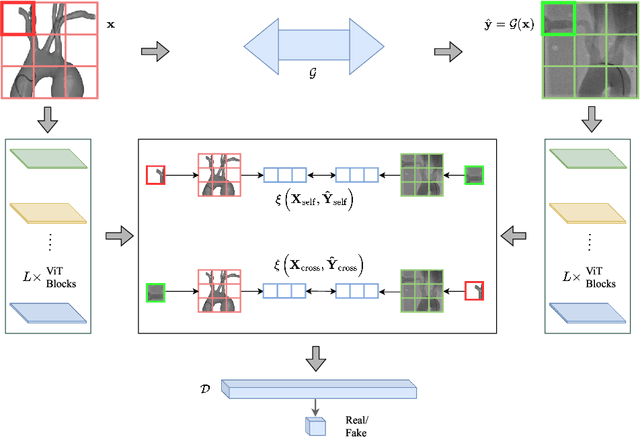
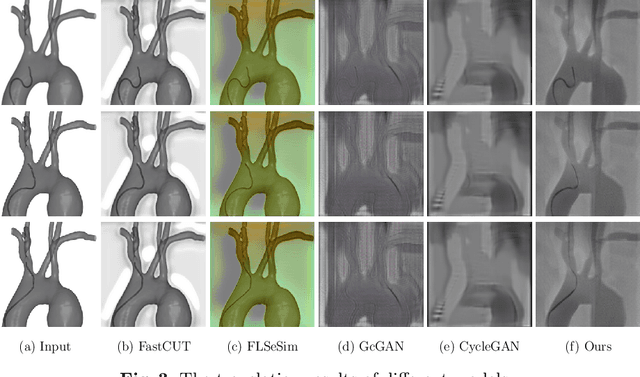
Endovascular intervention training is increasingly being conducted in virtual simulators. However, transferring the experience from endovascular simulators to the real world remains an open problem. The key challenge is the virtual environments are usually not realistically simulated, especially the simulation images. In this paper, we propose a new method to translate simulation images from an endovascular simulator to X-ray images. Previous image-to-image translation methods often focus on visual effects and neglect structure information, which is critical for medical images. To address this gap, we propose a new method that utilizes multi-scale semantic matching. We apply self-domain semantic matching to ensure that the input image and the generated image have the same positional semantic relationships. We further apply cross-domain matching to eliminate the effects of different styles. The intensive experiment shows that our method generates realistic X-ray images and outperforms other state-of-the-art approaches by a large margin. We also collect a new large-scale dataset to serve as the new benchmark for this task. Our source code and dataset will be made publicly available.