 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating Simulation Images to X-ray Images via Multi-Scale Semantic Matching
Apr 16, 2023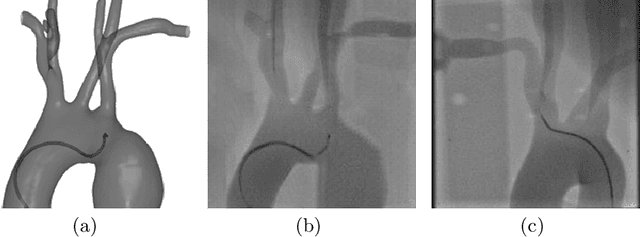
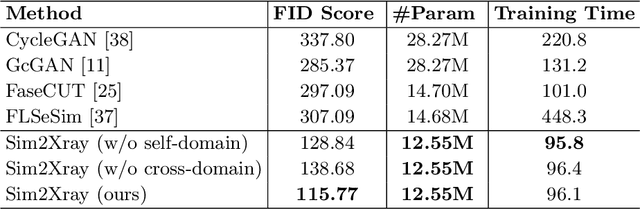
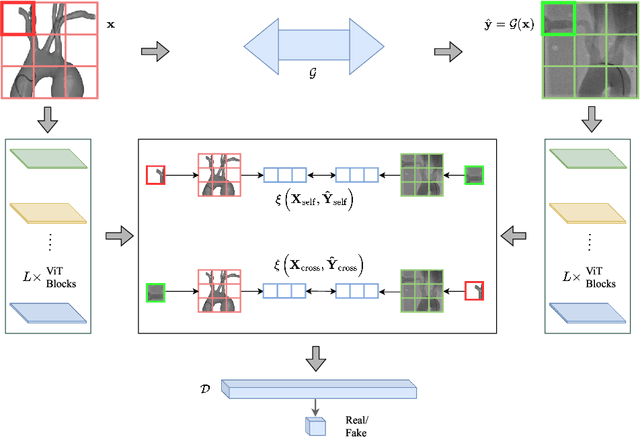
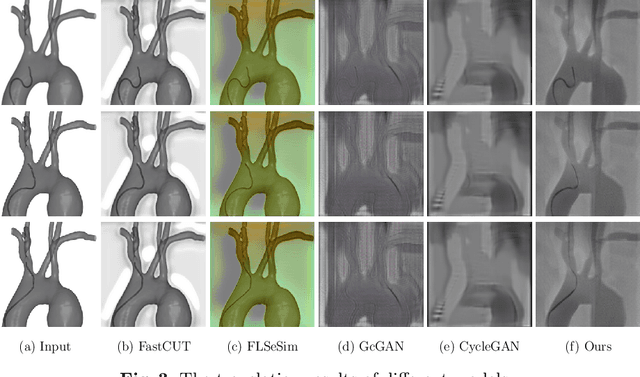
Endovascular intervention training is increasingly being conducted in virtual simulators. However, transferring the experience from endovascular simulators to the real world remains an open problem. The key challenge is the virtual environments are usually not realistically simulated, especially the simulation images. In this paper, we propose a new method to translate simulation images from an endovascular simulator to X-ray images. Previous image-to-image translation methods often focus on visual effects and neglect structure information, which is critical for medical images. To address this gap, we propose a new method that utilizes multi-scale semantic matching. We apply self-domain semantic matching to ensure that the input image and the generated image have the same positional semantic relationships. We further apply cross-domain matching to eliminate the effects of different styles. The intensive experiment shows that our method generates realistic X-ray images and outperforms other state-of-the-art approaches by a large margin. We also collect a new large-scale dataset to serve as the new benchmark for this task. Our source code and dataset will be made publicly available.
KIDS: kinematics-based (in)activity detection and segmentation in a sleep case study
Jan 04, 2023



Sleep behaviour and in-bed movements contain rich information on the neurophysiological health of people, and have a direct link to the general well-being and quality of life. Standard clinical practices rely on polysomnography for sleep assessment; however, it is intrusive, performed in unfamiliar environments and requires trained personnel. Progress has been made on less invasive sensor technologies, such as actigraphy, but clinical validation raises concerns over their reliability and precision. Additionally, the field lacks a widely acceptable algorithm, with proposed approaches ranging from raw signal or feature thresholding to data-hungry classification models, many of which are unfamiliar to medical staff. This paper proposes an online Bayesian probabilistic framework for objective (in)activity detection and segmentation based on clinically meaningful joint kinematics, measured by a custom-made wearable sensor. Intuitive three-dimensional visualisations of kinematic timeseries were accomplished through dimension reduction based preprocessing, offering out-of-the-box framework explainability potentially useful for clinical monitoring and diagnosis. The proposed framework attained up to 99.2\% $F_1$-score and 0.96 Pearson's correlation coefficient in, respectively, the posture change detection and inactivity segmentation tasks. The work paves the way for a reliable home-based analysis of movements during sleep which would serve patient-centred longitudinal care plans.
CNN-based Classification Framework for Lung Tissues with Auxiliary Information
Jun 18, 2022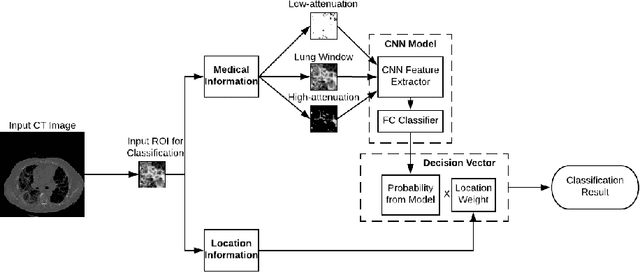
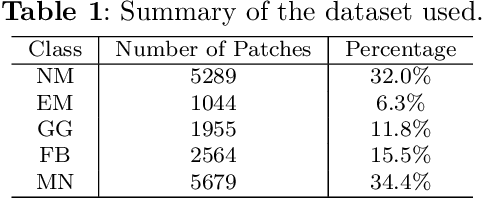
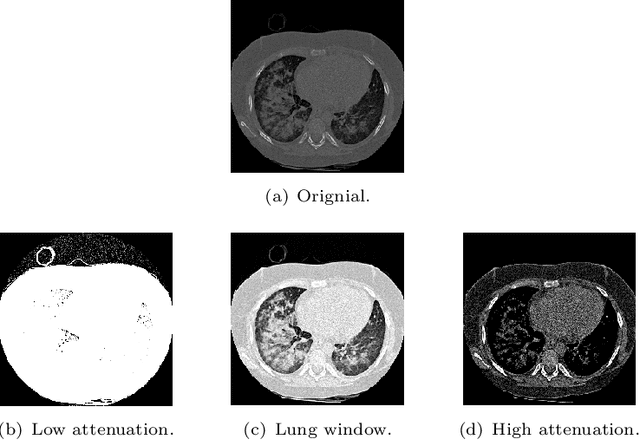

Interstitial lung diseases are a large group of heterogeneous diseases characterized by different degrees of alveolitis and pulmonary fibrosis. Accurately diagnosing these diseases has significant guiding value for formulating treatment plans. Although previous work has produced impressive results in classifying interstitial lung diseases, there is still room for improving the accuracy of these techniques, mainly to enhance automated decision-making. In order to improve the classification precision, our study proposes a convolutional neural networks-based framework with auxiliary information. Firstly, ILD images are added with their medical information by re-scaling the original image in Hounsfield Units. Secondly, a modified CNN model is used to produce a vector of classification probability for each tissue. Thirdly, location information of the input image, consisting of the occurrence frequencies of different diseases in the CT scans on certain locations, is used to calculate a location weight vector. Finally, the Hadamard product between two vectors is used to produce a decision vector for the prediction. Compared to the state-of-the-art methods, the results using a publicly available ILD database show the potential of predicting these using different auxiliary information.
Sleep Posture One-Shot Learning Framework Using Kinematic Data Augmentation: In-Silico and In-Vivo Case Studies
May 22, 2022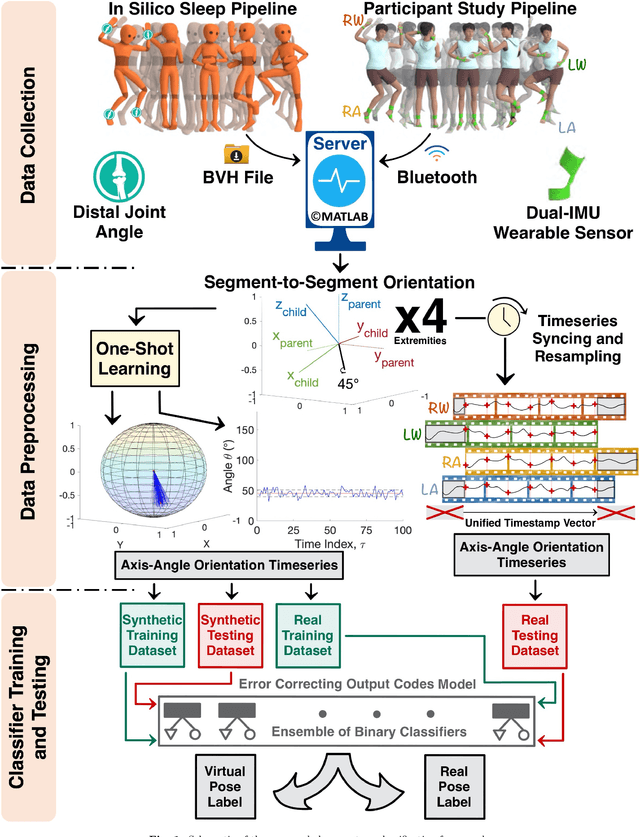
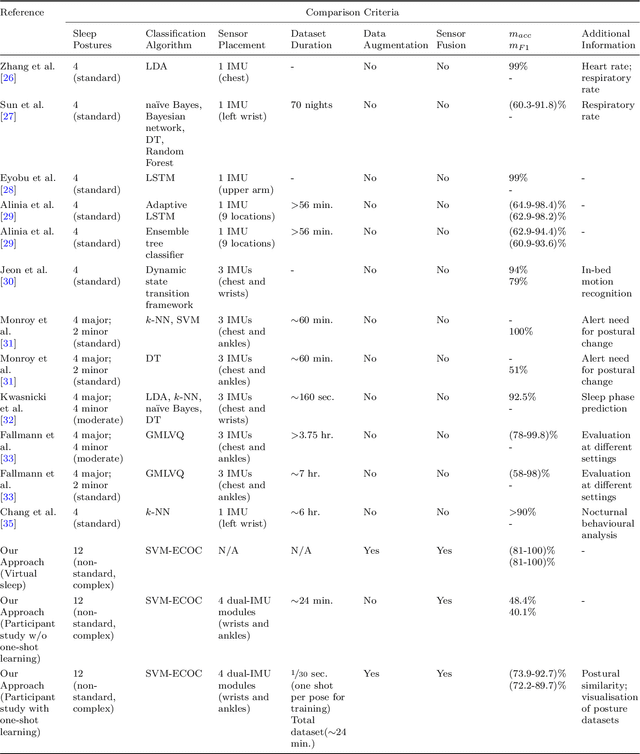
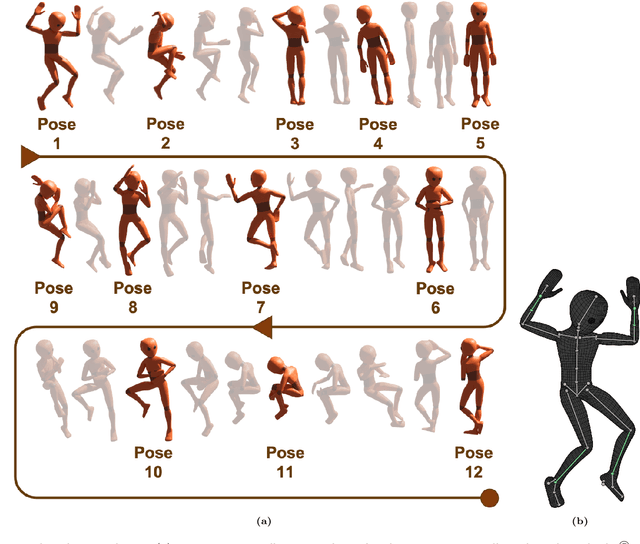
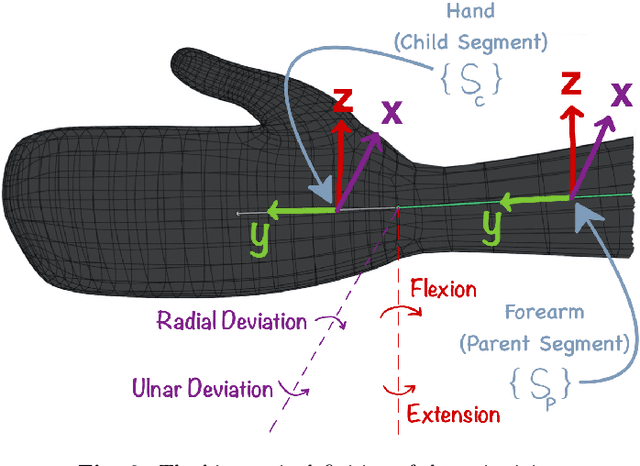
Sleep posture is linked to several health conditions such as nocturnal cramps and more serious musculoskeletal issues. However, in-clinic sleep assessments are often limited to vital signs (e.g. brain waves). Wearable sensors with embedded inertial measurement units have been used for sleep posture classification; nonetheless, previous works consider only few (commonly four) postures, which are inadequate for advanced clinical assessments. Moreover, posture learning algorithms typically require longitudinal data collection to function reliably, and often operate on raw inertial sensor readings unfamiliar to clinicians. This paper proposes a new framework for sleep posture classification based on a minimal set of joint angle measurements. The proposed framework is validated on a rich set of twelve postures in two experimental pipelines: computer animation to obtain synthetic postural data, and human participant pilot study using custom-made miniature wearable sensors. Through fusing raw geo-inertial sensor measurements to compute a filtered estimate of relative segment orientations across the wrist and ankle joints, the body posture can be characterised in a way comprehensible to medical experts. The proposed sleep posture learning framework offers plug-and-play posture classification by capitalising on a novel kinematic data augmentation method that requires only one training example per posture. Additionally, a new metric together with data visualisations are employed to extract meaningful insights from the postures dataset, demonstrate the added value of the data augmentation method, and explain the classification performance. The proposed framework attained promising overall accuracy as high as 100% on synthetic data and 92.7% on real data, on par with state of the art data-hungry algorithms available in the literature.
A Robust Framework of Chromosome Straightening with ViT-Patch GAN
Mar 06, 2022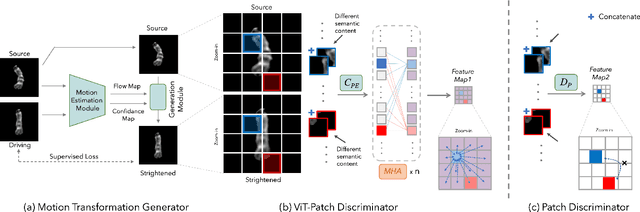

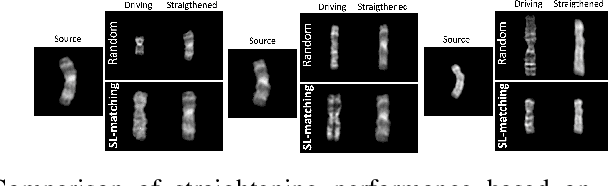
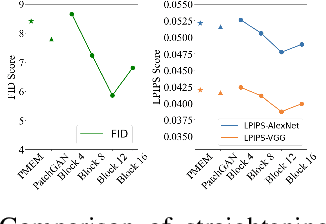
Chromosomes exhibit non-rigid and non-articulated nature with varying degrees of curvature. Chromosome straightening is an essential step for subsequent karyotype construction, pathological diagnosis and cytogenetic map development. However, robust chromosome straightening remains challenging, due to the unavailability of training images, distorted chromosome details and shapes after straightening, as well as poor generalization capability. We propose a novel architecture, ViT-Patch GAN, consisting of a motion transformation generator and a Vision Transformer-based patch (ViT-Patch) discriminator. The generator learns the motion representation of chromosomes for straightening. With the help of the ViT-Patch discriminator, the straightened chromosomes retain more shape and banding pattern details. The proposed framework is trained on a small dataset and is able to straighten chromosome images with state-of-the-art performance for two large datasets.
Bilateral-ViT for Robust Fovea Localization
Oct 19, 2021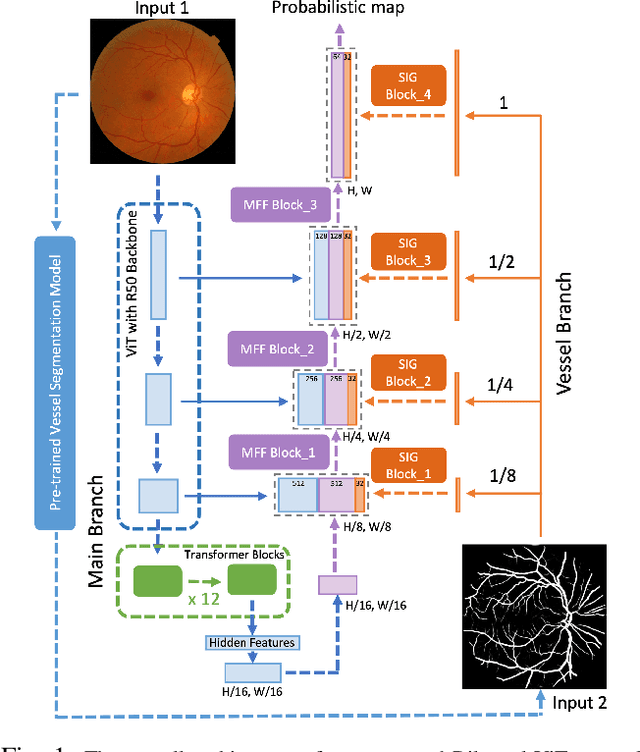
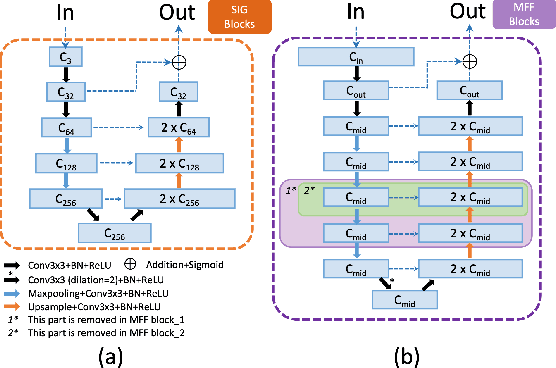
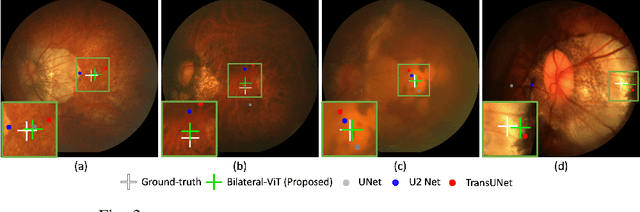
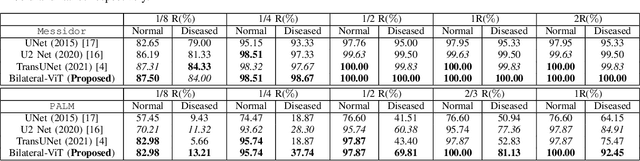
The fovea is an important anatomical landmark of the retina. Detecting the location of the fovea is essential for the analysis of many retinal diseases. However, robust fovea localization remains a challenging problem, as the fovea region often appears fuzzy, and retina diseases may further obscure its appearance. This paper proposes a novel vision transformer (ViT) approach that integrates information both inside and outside the fovea region to achieve robust fovea localization. Our proposed network named Bilateral-Vision-Transformer (Bilateral-ViT) consists of two network branches: a transformer-based main network branch for integrating global context across the entire fundus image and a vessel branch for explicitly incorporating the structure of blood vessels. The encoded features from both network branches are subsequently merged with a customized multi-scale feature fusion (MFF) module. Our comprehensive experiments demonstrate that the proposed approach is significantly more robust for diseased images and establishes the new state of the arts on both Messidor and PALM datasets.
Do not let the history haunt you -- Mitigating Compounding Errors in Conversational Question Answering
May 12, 2020
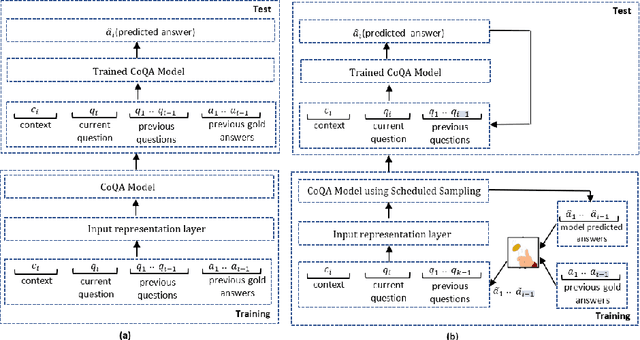

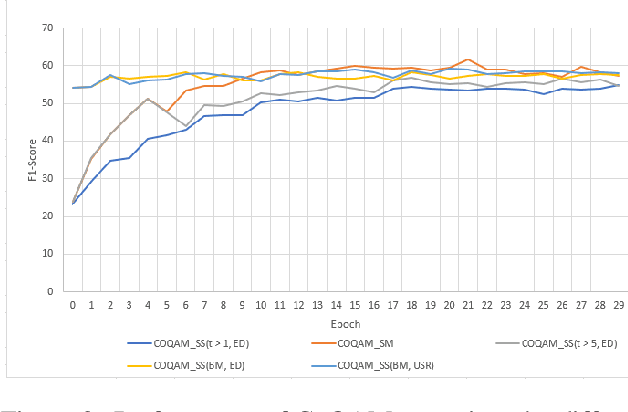
The Conversational Question Answering (CoQA) task involves answering a sequence of inter-related conversational questions about a contextual paragraph. Although existing approaches employ human-written ground-truth answers for answering conversational questions at test time, in a realistic scenario, the CoQA model will not have any access to ground-truth answers for the previous questions, compelling the model to rely upon its own previously predicted answers for answering the subsequent questions. In this paper, we find that compounding errors occur when using previously predicted answers at test time, significantly lowering the performance of CoQA systems. To solve this problem, we propose a sampling strategy that dynamically selects between target answers and model predictions during training, thereby closely simulating the situation at test time. Further, we analyse the severity of this phenomena as a function of the question type, conversation length and domain type.
Contextualised Graph Attention for Improved Relation Extraction
Apr 22, 2020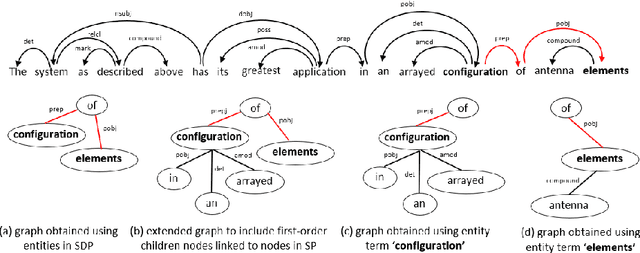

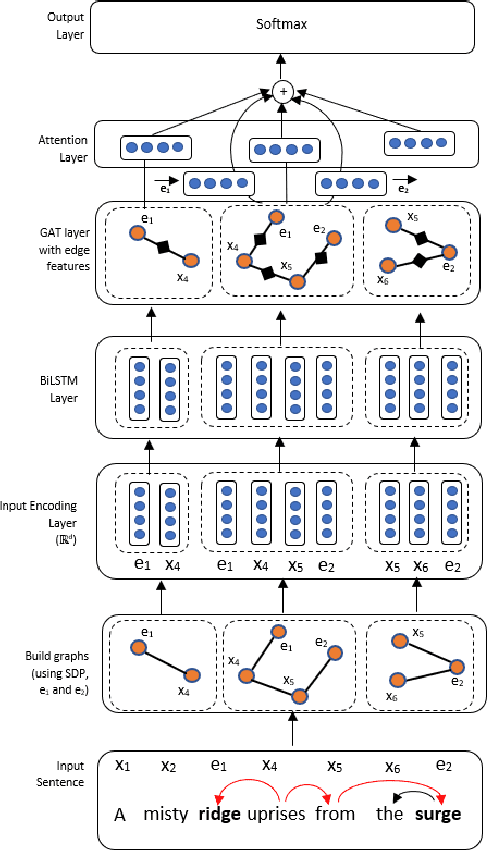
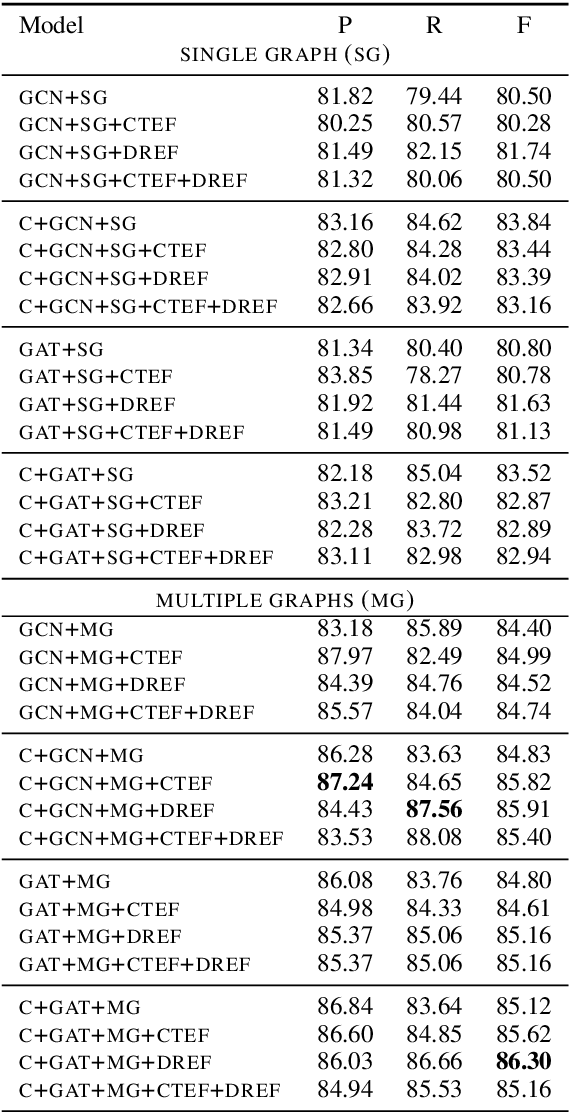
This paper presents a contextualized graph attention network that combines edge features and multiple sub-graphs for improving relation extraction. A novel method is proposed to use multiple sub-graphs to learn rich node representations in graph-based networks. To this end multiple sub-graphs are obtained from a single dependency tree. Two types of edge features are proposed, which are effectively combined with GAT and GCN models to apply for relation extraction. The proposed model achieves state-of-the-art performance on Semeval 2010 Task 8 dataset, achieving an F1-score of 86.3.
Combining Long Short Term Memory and Convolutional Neural Network for Cross-Sentence n-ary Relation Extraction
Nov 02, 2018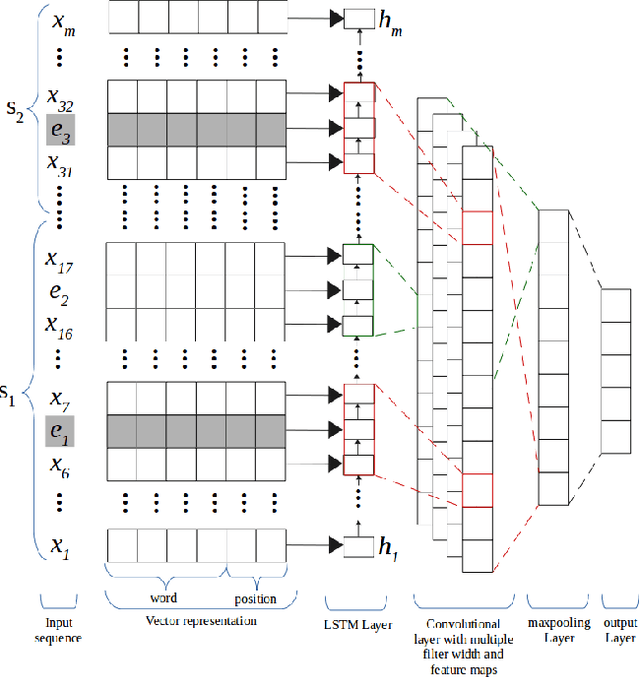
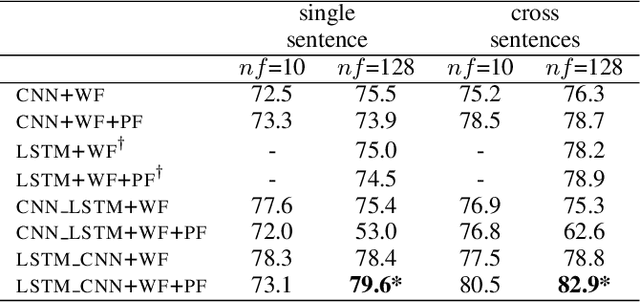
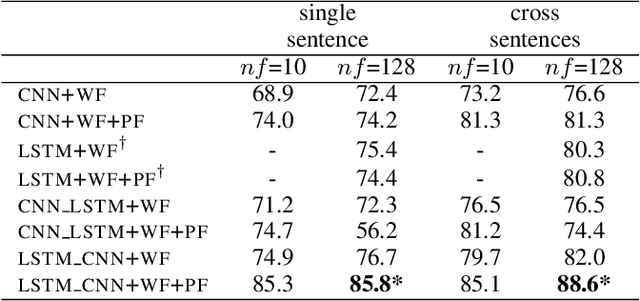
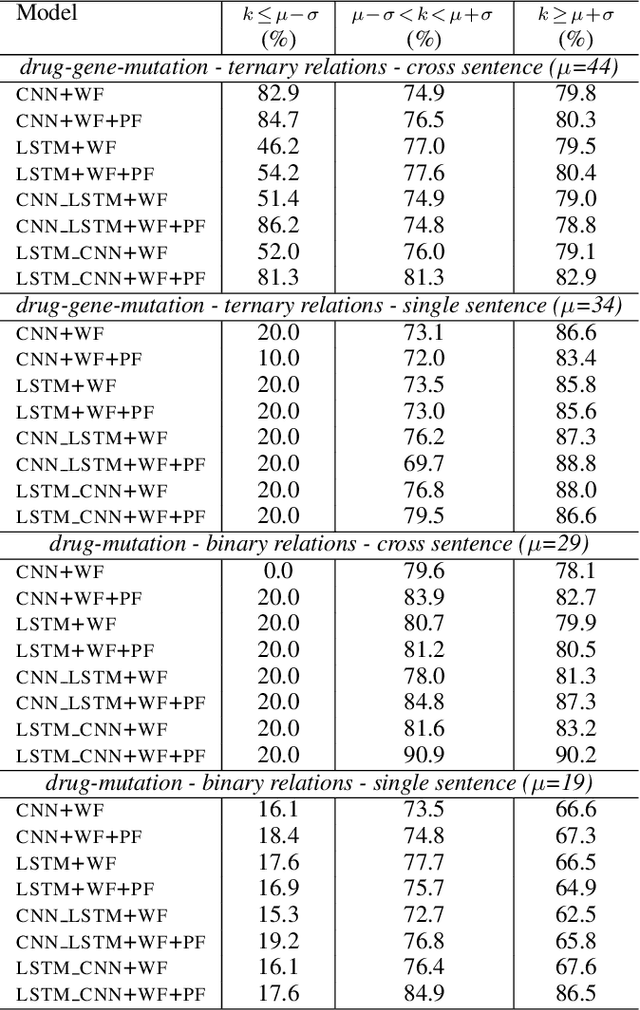
We propose in this paper a combined model of Long Short Term Memory and Convolutional Neural Networks (LSTM-CNN) that exploits word embeddings and positional embeddings for cross-sentence n-ary relation extraction. The proposed model brings together the properties of both LSTMs and CNNs, to simultaneously exploit long-range sequential information and capture most informative features, essential for cross-sentence n-ary relation extraction. The LSTM-CNN model is evaluated on standard dataset on cross-sentence n-ary relation extraction, where it significantly outperforms baselines such as CNNs, LSTMs and also a combined CNN-LSTM model. The paper also shows that the LSTM-CNN model outperforms the current state-of-the-art methods on cross-sentence n-ary relation extraction.