 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Borrow -- Relation Representation for Without-Mention Entity-Pairs for Knowledge Graph Completion
Apr 28, 2022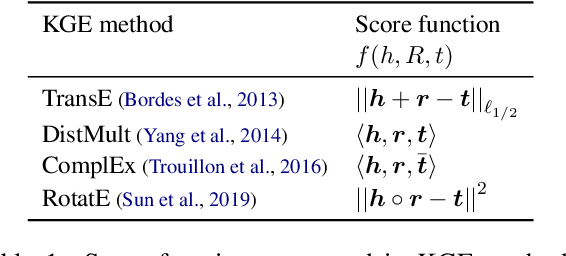
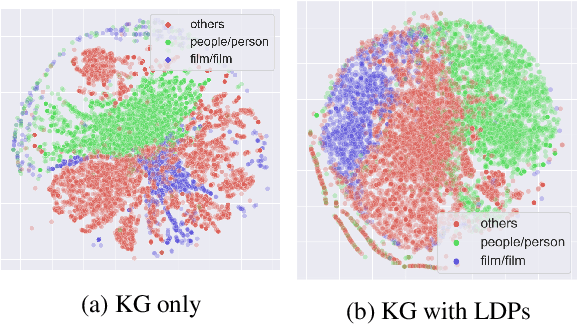
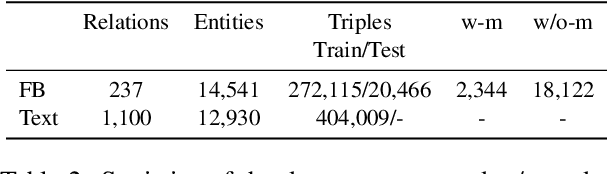
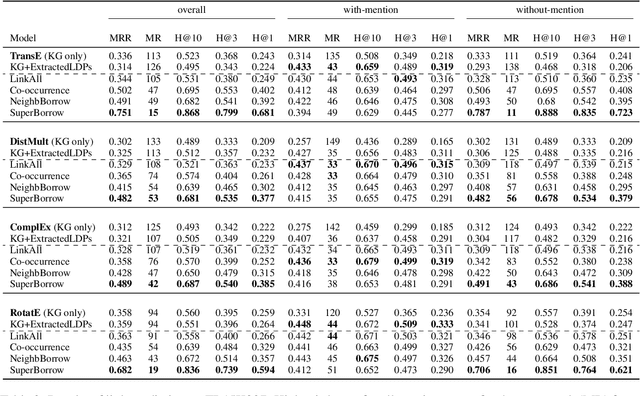
Prior work on integrating text corpora with knowledge graphs (KGs) to improve Knowledge Graph Embedding (KGE) have obtained good performance for entities that co-occur in sentences in text corpora. Such sentences (textual mentions of entity-pairs) are represented as Lexicalised Dependency Paths (LDPs) between two entities. However, it is not possible to represent relations between entities that do not co-occur in a single sentence using LDPs. In this paper, we propose and evaluate several methods to address this problem, where we borrow LDPs from the entity pairs that co-occur in sentences in the corpus (i.e. with mention entity pairs) to represent entity pairs that do not co-occur in any sentence in the corpus (i.e. without mention entity pairs). We propose a supervised borrowing method, SuperBorrow, that learns to score the suitability of an LDP to represent a without-mention entity pair using pre-trained entity embeddings and contextualised LDP representations. Experimental results show that SuperBorrow improves the link prediction performance of multiple widely-used prior KGE methods such as TransE, DistMult, ComplEx and RotatE.
Do not let the history haunt you -- Mitigating Compounding Errors in Conversational Question Answering
May 12, 2020
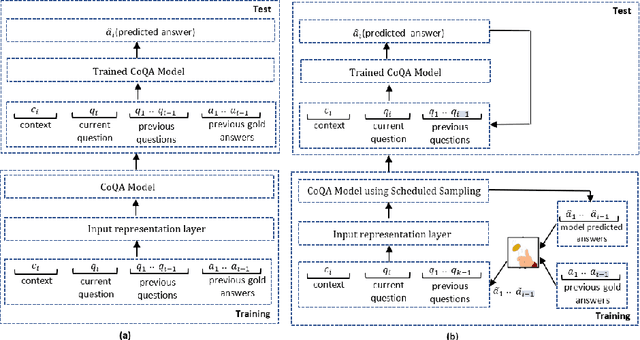

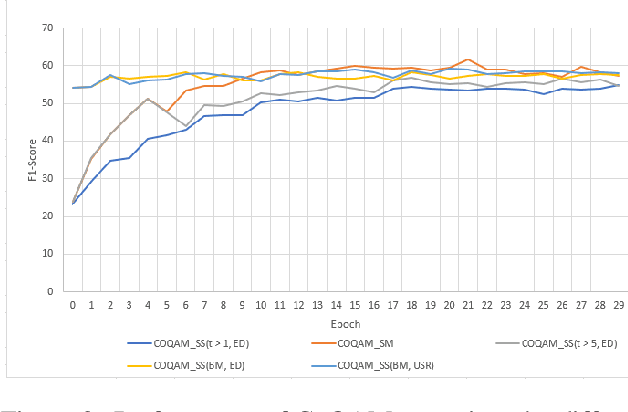
The Conversational Question Answering (CoQA) task involves answering a sequence of inter-related conversational questions about a contextual paragraph. Although existing approaches employ human-written ground-truth answers for answering conversational questions at test time, in a realistic scenario, the CoQA model will not have any access to ground-truth answers for the previous questions, compelling the model to rely upon its own previously predicted answers for answering the subsequent questions. In this paper, we find that compounding errors occur when using previously predicted answers at test time, significantly lowering the performance of CoQA systems. To solve this problem, we propose a sampling strategy that dynamically selects between target answers and model predictions during training, thereby closely simulating the situation at test time. Further, we analyse the severity of this phenomena as a function of the question type, conversation length and domain type.
Contextualised Graph Attention for Improved Relation Extraction
Apr 22, 2020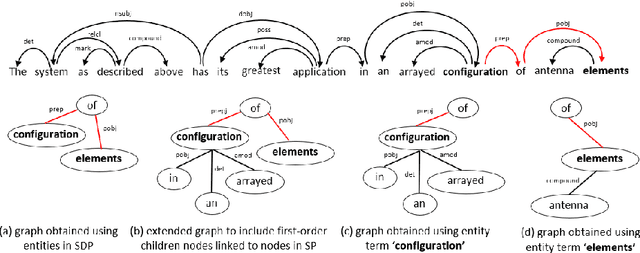

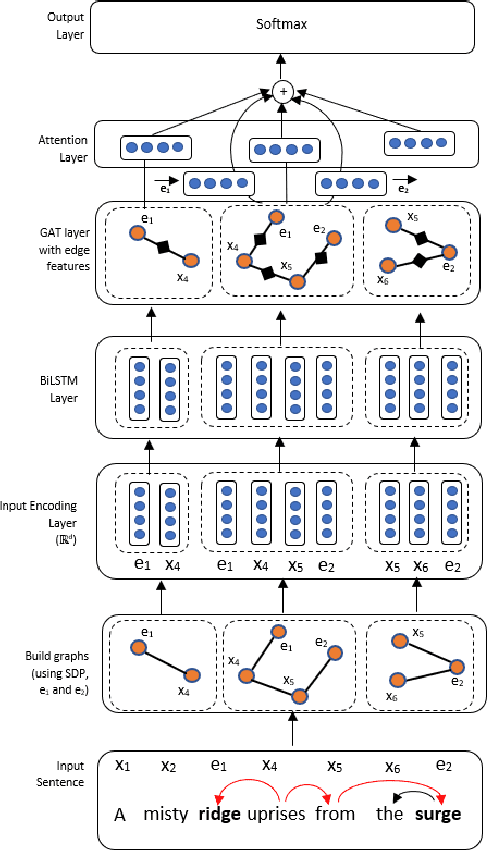
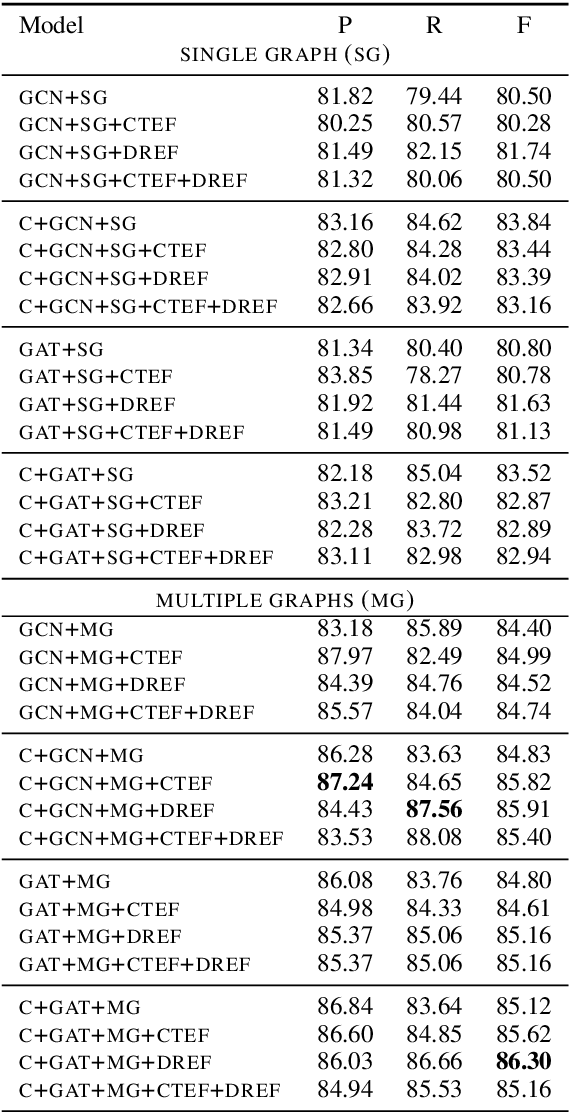
This paper presents a contextualized graph attention network that combines edge features and multiple sub-graphs for improving relation extraction. A novel method is proposed to use multiple sub-graphs to learn rich node representations in graph-based networks. To this end multiple sub-graphs are obtained from a single dependency tree. Two types of edge features are proposed, which are effectively combined with GAT and GCN models to apply for relation extraction. The proposed model achieves state-of-the-art performance on Semeval 2010 Task 8 dataset, achieving an F1-score of 86.3.
Combining Long Short Term Memory and Convolutional Neural Network for Cross-Sentence n-ary Relation Extraction
Nov 02, 2018
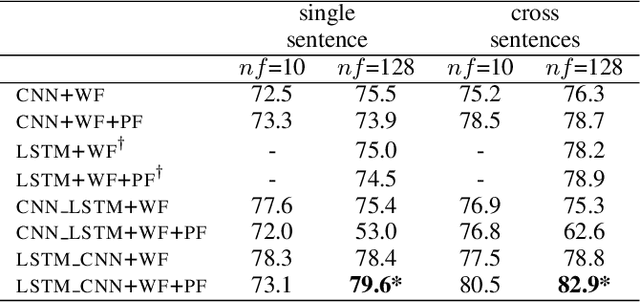
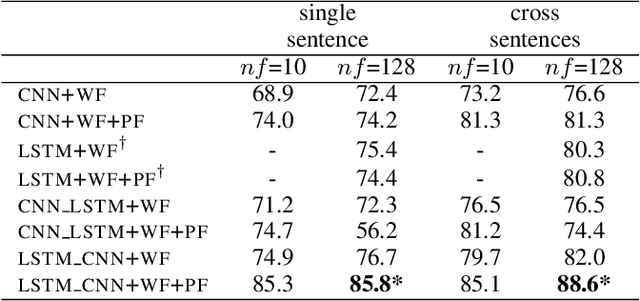
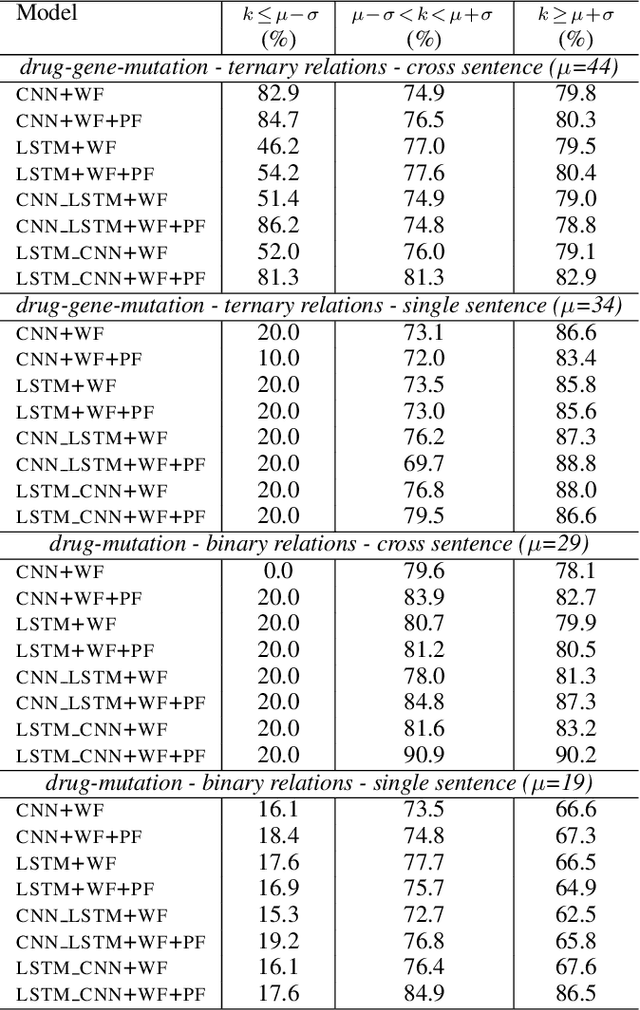
We propose in this paper a combined model of Long Short Term Memory and Convolutional Neural Networks (LSTM-CNN) that exploits word embeddings and positional embeddings for cross-sentence n-ary relation extraction. The proposed model brings together the properties of both LSTMs and CNNs, to simultaneously exploit long-range sequential information and capture most informative features, essential for cross-sentence n-ary relation extraction. The LSTM-CNN model is evaluated on standard dataset on cross-sentence n-ary relation extraction, where it significantly outperforms baselines such as CNNs, LSTMs and also a combined CNN-LSTM model. The paper also shows that the LSTM-CNN model outperforms the current state-of-the-art methods on cross-sentence n-ary relation extraction.