 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemEval-2026 Task 7: Everyday Knowledge Across Diverse Languages and Cultures
May 04, 2026We present our shared task on evaluating the adaptability of LLMs and NLP systems across multiple languages and cultures. The task data consist of an extended version of our manually constructed BLEnD benchmark (Myung et al. 2024), covering more than 30 language-culture pairs, predominantly representing low-resource languages spoken across multiple continents. As the task is designed strictly for evaluation, participants were not permitted to use the data for training, fine-tuning, few-shot learning, or any other form of model modification. Our task includes two tracks: (a) Short-Answer Questions (SAQ) and (b) Multiple-Choice Questions (MCQ). Participants were required to predict labels and were allowed to submit any NLP system and adopt diverse modelling strategies, provided that the benchmark was used solely for evaluation. The task attracted more than 140 registered participants, and we received final submissions from 62 teams, along with 19 system description papers. We report the results and present an analysis of the best-performing systems and the most commonly adopted approaches. Furthermore, we discuss shared insights into open questions and challenges related to evaluation, misalignment, and methodological perspectives on model behaviour in low-resource languages and for under-represented cultures.
Learning to Borrow -- Relation Representation for Without-Mention Entity-Pairs for Knowledge Graph Completion
Apr 28, 2022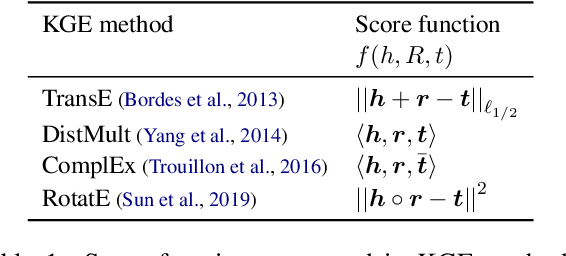
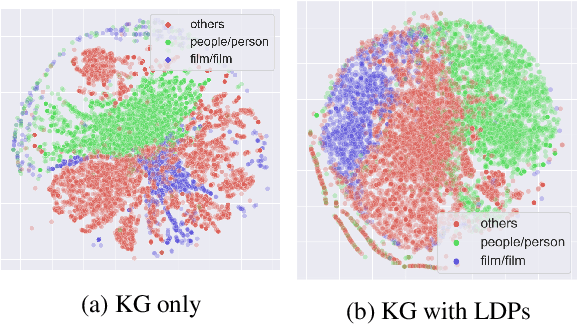
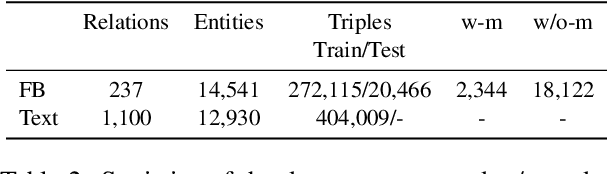
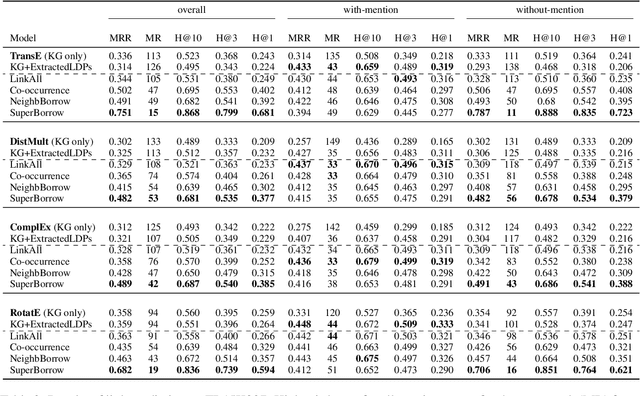
Prior work on integrating text corpora with knowledge graphs (KGs) to improve Knowledge Graph Embedding (KGE) have obtained good performance for entities that co-occur in sentences in text corpora. Such sentences (textual mentions of entity-pairs) are represented as Lexicalised Dependency Paths (LDPs) between two entities. However, it is not possible to represent relations between entities that do not co-occur in a single sentence using LDPs. In this paper, we propose and evaluate several methods to address this problem, where we borrow LDPs from the entity pairs that co-occur in sentences in the corpus (i.e. with mention entity pairs) to represent entity pairs that do not co-occur in any sentence in the corpus (i.e. without mention entity pairs). We propose a supervised borrowing method, SuperBorrow, that learns to score the suitability of an LDP to represent a without-mention entity pair using pre-trained entity embeddings and contextualised LDP representations. Experimental results show that SuperBorrow improves the link prediction performance of multiple widely-used prior KGE methods such as TransE, DistMult, ComplEx and RotatE.
RelWalk A Latent Variable Model Approach to Knowledge Graph Embedding
Jan 25, 2021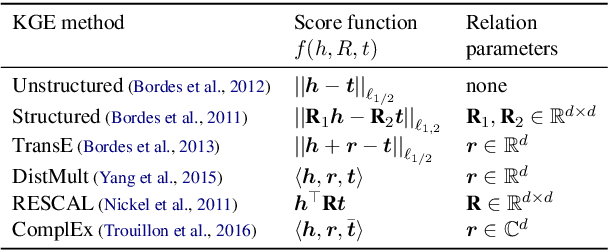
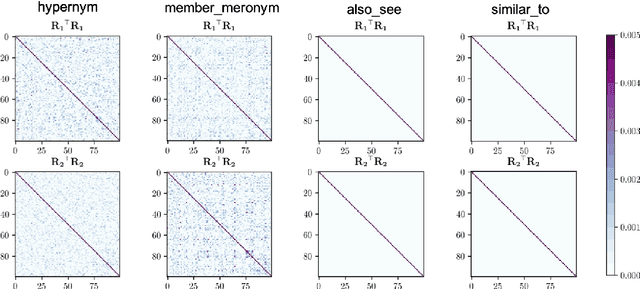
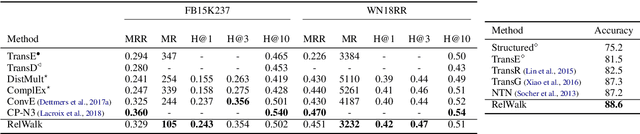
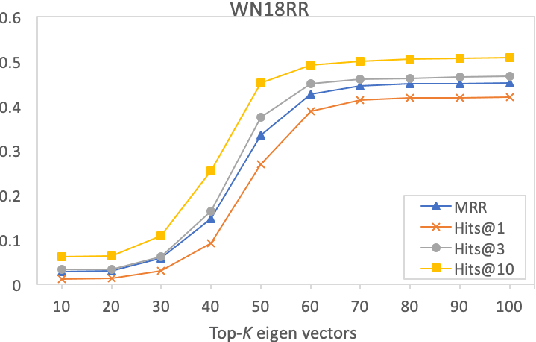
Embedding entities and relations of a knowledge graph in a low-dimensional space has shown impressive performance in predicting missing links between entities. Although progresses have been achieved, existing methods are heuristically motivated and theoretical understanding of such embeddings is comparatively underdeveloped. This paper extends the random walk model (Arora et al., 2016a) of word embeddings to Knowledge Graph Embeddings (KGEs) to derive a scoring function that evaluates the strength of a relation R between two entities h (head) and t (tail). Moreover, we show that marginal loss minimisation, a popular objective used in much prior work in KGE, follows naturally from the log-likelihood ratio maximisation under the probabilities estimated from the KGEs according to our theoretical relationship. We propose a learning objective motivated by the theoretical analysis to learn KGEs from a given knowledge graph. Using the derived objective, accurate KGEs are learnt from FB15K237 and WN18RR benchmark datasets, providing empirical evidence in support of the theory.
Why PairDiff works? -- A Mathematical Analysis of Bilinear Relational Compositional Operators for Analogy Detection
Dec 15, 2017
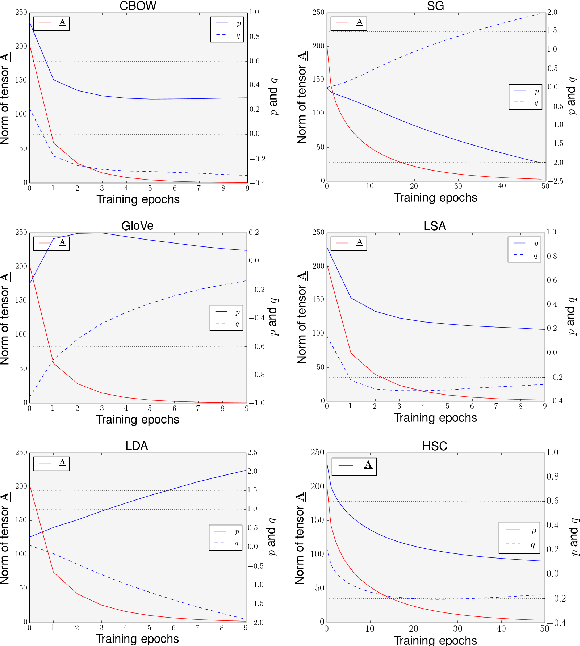
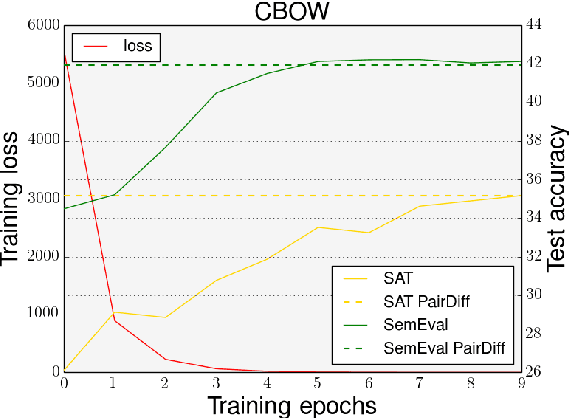
Representing the semantic relations that exist between two given words (or entities) is an important first step in a wide-range of NLP applications such as analogical reasoning, knowledge base completion and relational information retrieval. A simple, yet surprisingly accurate method for representing a relation between two words is to compute the vector offset (\PairDiff) between their corresponding word embeddings. Despite the empirical success, it remains unclear as to whether \PairDiff is the best operator for obtaining a relational representation from word embeddings. We conduct a theoretical analysis of generalised bilinear operators that can be used to measure the $\ell_{2}$ relational distance between two word-pairs. We show that, if the word embeddings are standardised and uncorrelated, such an operator will be independent of bilinear terms, and can be simplified to a linear form, where \PairDiff is a special case. For numerous word embedding types, we empirically verify the uncorrelation assumption, demonstrating the general applicability of our theoretical result. Moreover, we experimentally discover \PairDiff from the bilinear relation composition operator on several benchmark analogy datasets.
Compositional Approaches for Representing Relations Between Words: A Comparative Study
Sep 04, 2017
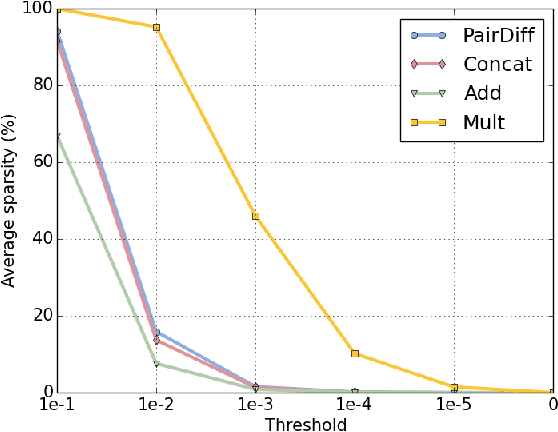


Identifying the relations that exist between words (or entities) is important for various natural language processing tasks such as, relational search, noun-modifier classification and analogy detection. A popular approach to represent the relations between a pair of words is to extract the patterns in which the words co-occur with from a corpus, and assign each word-pair a vector of pattern frequencies. Despite the simplicity of this approach, it suffers from data sparseness, information scalability and linguistic creativity as the model is unable to handle previously unseen word pairs in a corpus. In contrast, a compositional approach for representing relations between words overcomes these issues by using the attributes of each individual word to indirectly compose a representation for the common relations that hold between the two words. This study aims to compare different operations for creating relation representations from word-level representations. We investigate the performance of the compositional methods by measuring the relational similarities using several benchmark datasets for word analogy. Moreover, we evaluate the different relation representations in a knowledge base completion task.