 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Approaches for Representing Relations Between Words: A Comparative Study
Paper and Code

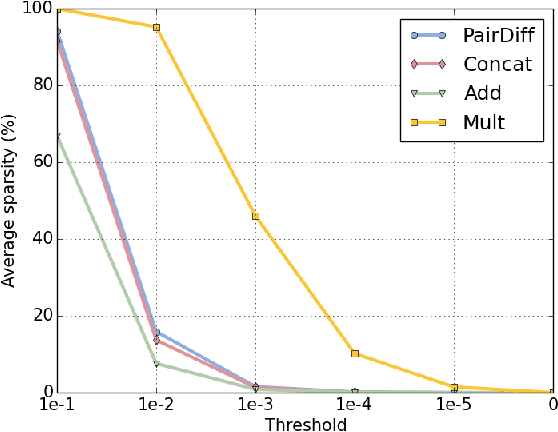


Identifying the relations that exist between words (or entities) is important for various natural language processing tasks such as, relational search, noun-modifier classification and analogy detection. A popular approach to represent the relations between a pair of words is to extract the patterns in which the words co-occur with from a corpus, and assign each word-pair a vector of pattern frequencies. Despite the simplicity of this approach, it suffers from data sparseness, information scalability and linguistic creativity as the model is unable to handle previously unseen word pairs in a corpus. In contrast, a compositional approach for representing relations between words overcomes these issues by using the attributes of each individual word to indirectly compose a representation for the common relations that hold between the two words. This study aims to compare different operations for creating relation representations from word-level representations. We investigate the performance of the compositional methods by measuring the relational similarities using several benchmark datasets for word analogy. Moreover, we evaluate the different relation representations in a knowledge base completion task.