 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating Simulation Images to X-ray Images via Multi-Scale Semantic Matching
Paper and Code
Apr 16, 2023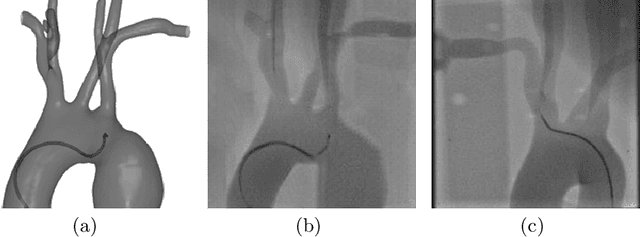
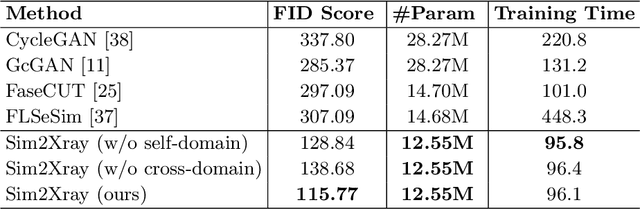
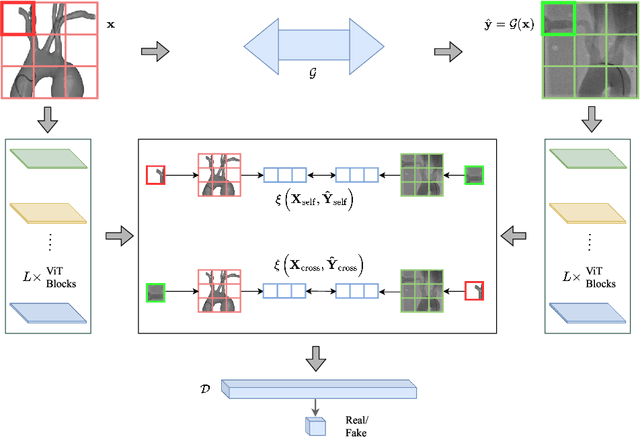
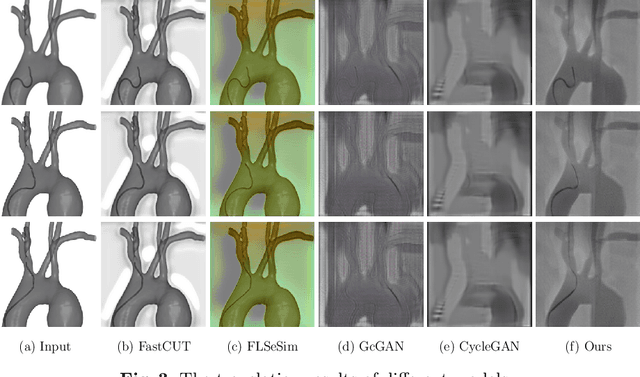
Endovascular intervention training is increasingly being conducted in virtual simulators. However, transferring the experience from endovascular simulators to the real world remains an open problem. The key challenge is the virtual environments are usually not realistically simulated, especially the simulation images. In this paper, we propose a new method to translate simulation images from an endovascular simulator to X-ray images. Previous image-to-image translation methods often focus on visual effects and neglect structure information, which is critical for medical images. To address this gap, we propose a new method that utilizes multi-scale semantic matching. We apply self-domain semantic matching to ensure that the input image and the generated image have the same positional semantic relationships. We further apply cross-domain matching to eliminate the effects of different styles. The intensive experiment shows that our method generates realistic X-ray images and outperforms other state-of-the-art approaches by a large margin. We also collect a new large-scale dataset to serve as the new benchmark for this task. Our source code and dataset will be made publicly available.