 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-modal Detection System for Infrastructure-based Freight Signal Priority
Feb 19, 2026Freight vehicles approaching signalized intersections require reliable detection and motion estimation to support infrastructure-based Freight Signal Priority (FSP). Accurate and timely perception of vehicle type, position, and speed is essential for enabling effective priority control strategies. This paper presents the design, deployment, and evaluation of an infrastructure-based multi-modal freight vehicle detection system integrating LiDAR and camera sensors. A hybrid sensing architecture is adopted, consisting of an intersection-mounted subsystem and a midblock subsystem, connected via wireless communication for synchronized data transmission. The perception pipeline incorporates both clustering-based and deep learning-based detection methods with Kalman filter tracking to achieve stable real-time performance. LiDAR measurements are registered into geodetic reference frames to support lane-level localization and consistent vehicle tracking. Field evaluations demonstrate that the system can reliably monitor freight vehicle movements at high spatio-temporal resolution. The design and deployment provide practical insights for developing infrastructure-based sensing systems to support FSP applications.
What Really Matters for Robust Multi-Sensor HD Map Construction?
Jul 02, 2025High-definition (HD) map construction methods are crucial for providing precise and comprehensive static environmental information, which is essential for autonomous driving systems. While Camera-LiDAR fusion techniques have shown promising results by integrating data from both modalities, existing approaches primarily focus on improving model accuracy and often neglect the robustness of perception models, which is a critical aspect for real-world applications. In this paper, we explore strategies to enhance the robustness of multi-modal fusion methods for HD map construction while maintaining high accuracy. We propose three key components: data augmentation, a novel multi-modal fusion module, and a modality dropout training strategy. These components are evaluated on a challenging dataset containing 10 days of NuScenes data. Our experimental results demonstrate that our proposed methods significantly enhance the robustness of baseline methods. Furthermore, our approach achieves state-of-the-art performance on the clean validation set of the NuScenes dataset. Our findings provide valuable insights for developing more robust and reliable HD map construction models, advancing their applicability in real-world autonomous driving scenarios. Project website: https://robomap-123.github.io.
VTLA: Vision-Tactile-Language-Action Model with Preference Learning for Insertion Manipulation
May 14, 2025
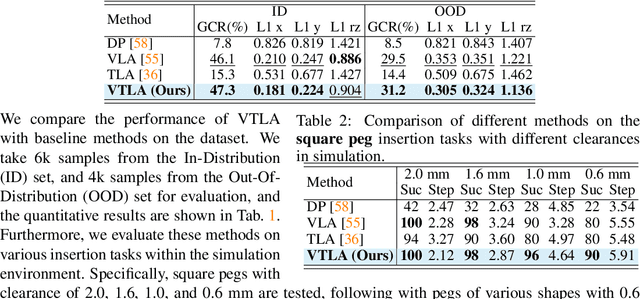


While vision-language models have advanced significantly, their application in language-conditioned robotic manipulation is still underexplored, especially for contact-rich tasks that extend beyond visually dominant pick-and-place scenarios. To bridge this gap, we introduce Vision-Tactile-Language-Action model, a novel framework that enables robust policy generation in contact-intensive scenarios by effectively integrating visual and tactile inputs through cross-modal language grounding. A low-cost, multi-modal dataset has been constructed in a simulation environment, containing vision-tactile-action-instruction pairs specifically designed for the fingertip insertion task. Furthermore, we introduce Direct Preference Optimization (DPO) to offer regression-like supervision for the VTLA model, effectively bridging the gap between classification-based next token prediction loss and continuous robotic tasks. Experimental results show that the VTLA model outperforms traditional imitation learning methods (e.g., diffusion policies) and existing multi-modal baselines (TLA/VLA), achieving over 90% success rates on unseen peg shapes. Finally, we conduct real-world peg-in-hole experiments to demonstrate the exceptional Sim2Real performance of the proposed VTLA model. For supplementary videos and results, please visit our project website: https://sites.google.com/view/vtla
CLTP: Contrastive Language-Tactile Pre-training for 3D Contact Geometry Understanding
May 13, 2025Recent advancements in integrating tactile sensing with vision-language models (VLMs) have demonstrated remarkable potential for robotic multimodal perception. However, existing tactile descriptions remain limited to superficial attributes like texture, neglecting critical contact states essential for robotic manipulation. To bridge this gap, we propose CLTP, an intuitive and effective language tactile pretraining framework that aligns tactile 3D point clouds with natural language in various contact scenarios, thus enabling contact-state-aware tactile language understanding for contact-rich manipulation tasks. We first collect a novel dataset of 50k+ tactile 3D point cloud-language pairs, where descriptions explicitly capture multidimensional contact states (e.g., contact location, shape, and force) from the tactile sensor's perspective. CLTP leverages a pre-aligned and frozen vision-language feature space to bridge holistic textual and tactile modalities. Experiments validate its superiority in three downstream tasks: zero-shot 3D classification, contact state classification, and tactile 3D large language model (LLM) interaction. To the best of our knowledge, this is the first study to align tactile and language representations from the contact state perspective for manipulation tasks, providing great potential for tactile-language-action model learning. Code and datasets are open-sourced at https://sites.google.com/view/cltp/.
TLA: Tactile-Language-Action Model for Contact-Rich Manipulation
Mar 11, 2025Significant progress has been made in vision-language models. However, language-conditioned robotic manipulation for contact-rich tasks remains underexplored, particularly in terms of tactile sensing. To address this gap, we introduce the Tactile-Language-Action (TLA) model, which effectively processes sequential tactile feedback via cross-modal language grounding to enable robust policy generation in contact-intensive scenarios. In addition, we construct a comprehensive dataset that contains 24k pairs of tactile action instruction data, customized for fingertip peg-in-hole assembly, providing essential resources for TLA training and evaluation. Our results show that TLA significantly outperforms traditional imitation learning methods (e.g., diffusion policy) in terms of effective action generation and action accuracy, while demonstrating strong generalization capabilities by achieving over 85\% success rate on previously unseen assembly clearances and peg shapes. We publicly release all data and code in the hope of advancing research in language-conditioned tactile manipulation skill learning. Project website: https://sites.google.com/view/tactile-language-action/
MapFusion: A Novel BEV Feature Fusion Network for Multi-modal Map Construction
Feb 05, 2025Map construction task plays a vital role in providing precise and comprehensive static environmental information essential for autonomous driving systems. Primary sensors include cameras and LiDAR, with configurations varying between camera-only, LiDAR-only, or camera-LiDAR fusion, based on cost-performance considerations. While fusion-based methods typically perform best, existing approaches often neglect modality interaction and rely on simple fusion strategies, which suffer from the problems of misalignment and information loss. To address these issues, we propose MapFusion, a novel multi-modal Bird's-Eye View (BEV) feature fusion method for map construction. Specifically, to solve the semantic misalignment problem between camera and LiDAR BEV features, we introduce the Cross-modal Interaction Transform (CIT) module, enabling interaction between two BEV feature spaces and enhancing feature representation through a self-attention mechanism. Additionally, we propose an effective Dual Dynamic Fusion (DDF) module to adaptively select valuable information from different modalities, which can take full advantage of the inherent information between different modalities. Moreover, MapFusion is designed to be simple and plug-and-play, easily integrated into existing pipelines. We evaluate MapFusion on two map construction tasks, including High-definition (HD) map and BEV map segmentation, to show its versatility and effectiveness. Compared with the state-of-the-art methods, MapFusion achieves 3.6% and 6.2% absolute improvements on the HD map construction and BEV map segmentation tasks on the nuScenes dataset, respectively, demonstrating the superiority of our approach.
BCTR: Bidirectional Conditioning Transformer for Scene Graph Generation
Jul 26, 2024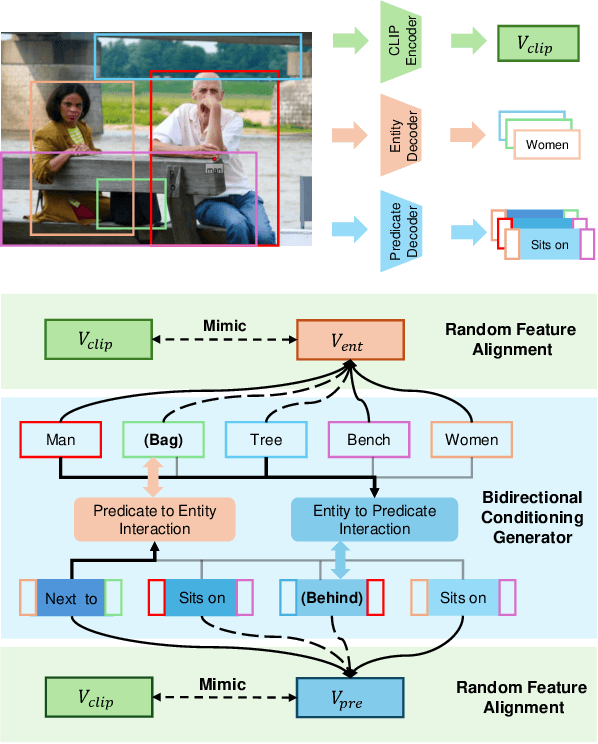
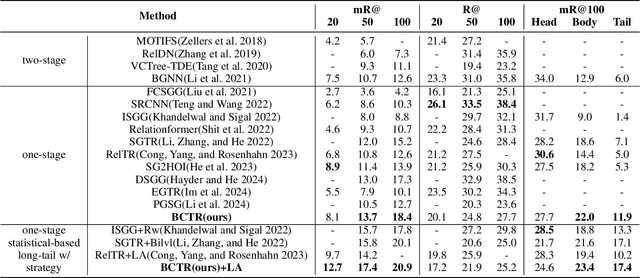
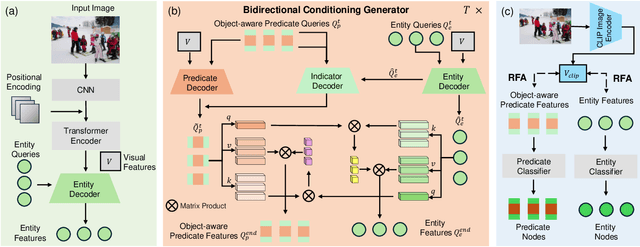
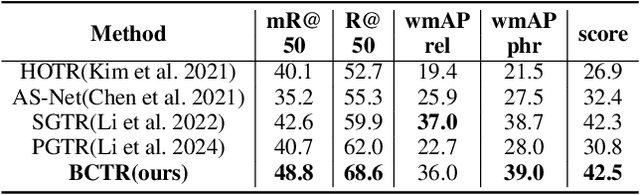
Scene Graph Generation (SGG) remains a challenging task due to its compositional property. Previous approaches improve prediction efficiency by learning in an end-to-end manner. However, these methods exhibit limited performance as they assume unidirectional conditioning between entities and predicates, leading to insufficient information interaction. To address this limitation, we propose a novel bidirectional conditioning factorization for SGG, introducing efficient interaction between entities and predicates. Specifically, we develop an end-to-end scene graph generation model, Bidirectional Conditioning Transformer (BCTR), to implement our factorization. BCTR consists of two key modules. First, the Bidirectional Conditioning Generator (BCG) facilitates multi-stage interactive feature augmentation between entities and predicates, enabling mutual benefits between the two predictions. Second, Random Feature Alignment (RFA) regularizes the feature space by distilling multi-modal knowledge from pre-trained models, enhancing BCTR's ability on tailed categories without relying on statistical priors. We conduct a series of experiments on Visual Genome and Open Image V6, demonstrating that BCTR achieves state-of-the-art performance on both benchmarks. The code will be available upon acceptance of the paper.
HyCIR: Boosting Zero-Shot Composed Image Retrieval with Synthetic Labels
Jul 09, 2024


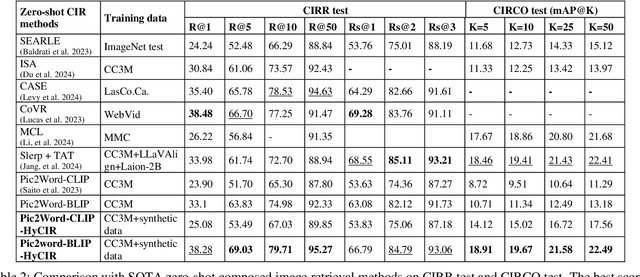
Composed Image Retrieval (CIR) aims to retrieve images based on a query image with text. Current Zero-Shot CIR (ZS-CIR) methods try to solve CIR tasks without using expensive triplet-labeled training datasets. However, the gap between ZS-CIR and triplet-supervised CIR is still large. In this work, we propose Hybrid CIR (HyCIR), which uses synthetic labels to boost the performance of ZS-CIR. A new label Synthesis pipeline for CIR (SynCir) is proposed, in which only unlabeled images are required. First, image pairs are extracted based on visual similarity. Second, query text is generated for each image pair based on vision-language model and LLM. Third, the data is further filtered in language space based on semantic similarity. To improve ZS-CIR performance, we propose a hybrid training strategy to work with both ZS-CIR supervision and synthetic CIR triplets. Two kinds of contrastive learning are adopted. One is to use large-scale unlabeled image dataset to learn an image-to-text mapping with good generalization. The other is to use synthetic CIR triplets to learn a better mapping for CIR tasks. Our approach achieves SOTA zero-shot performance on the common CIR benchmarks: CIRR and CIRCO.
What Foundation Models can Bring for Robot Learning in Manipulation : A Survey
Apr 28, 2024



The realization of universal robots is an ultimate goal of researchers. However, a key hurdle in achieving this goal lies in the robots' ability to manipulate objects in their unstructured surrounding environments according to different tasks. The learning-based approach is considered an effective way to address generalization. The impressive performance of foundation models in the fields of computer vision and natural language suggests the potential of embedding foundation models into manipulation tasks as a viable path toward achieving general manipulation capability. However, we believe achieving general manipulation capability requires an overarching framework akin to auto driving. This framework should encompass multiple functional modules, with different foundation models assuming distinct roles in facilitating general manipulation capability. This survey focuses on the contributions of foundation models to robot learning for manipulation. We propose a comprehensive framework and detail how foundation models can address challenges in each module of the framework. What's more, we examine current approaches, outline challenges, suggest future research directions, and identify potential risks associated with integrating foundation models into this domain.
RobotGPT: Robot Manipulation Learning from ChatGPT
Dec 03, 2023



We present RobotGPT, an innovative decision framework for robotic manipulation that prioritizes stability and safety. The execution code generated by ChatGPT cannot guarantee the stability and safety of the system. ChatGPT may provide different answers for the same task, leading to unpredictability. This instability prevents the direct integration of ChatGPT into the robot manipulation loop. Although setting the temperature to 0 can generate more consistent outputs, it may cause ChatGPT to lose diversity and creativity. Our objective is to leverage ChatGPT's problem-solving capabilities in robot manipulation and train a reliable agent. The framework includes an effective prompt structure and a robust learning model. Additionally, we introduce a metric for measuring task difficulty to evaluate ChatGPT's performance in robot manipulation. Furthermore, we evaluate RobotGPT in both simulation and real-world environments. Compared to directly using ChatGPT to generate code, our framework significantly improves task success rates, with an average increase from 38.5% to 91.5%. Therefore, training a RobotGPT by utilizing ChatGPT as an expert is a more stable approach compared to directly using ChatGPT as a task planner.