 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyCIR: Boosting Zero-Shot Composed Image Retrieval with Synthetic Labels
Paper and Code
Jul 09, 2024


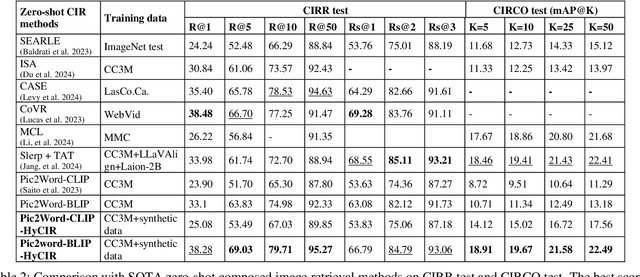
Composed Image Retrieval (CIR) aims to retrieve images based on a query image with text. Current Zero-Shot CIR (ZS-CIR) methods try to solve CIR tasks without using expensive triplet-labeled training datasets. However, the gap between ZS-CIR and triplet-supervised CIR is still large. In this work, we propose Hybrid CIR (HyCIR), which uses synthetic labels to boost the performance of ZS-CIR. A new label Synthesis pipeline for CIR (SynCir) is proposed, in which only unlabeled images are required. First, image pairs are extracted based on visual similarity. Second, query text is generated for each image pair based on vision-language model and LLM. Third, the data is further filtered in language space based on semantic similarity. To improve ZS-CIR performance, we propose a hybrid training strategy to work with both ZS-CIR supervision and synthetic CIR triplets. Two kinds of contrastive learning are adopted. One is to use large-scale unlabeled image dataset to learn an image-to-text mapping with good generalization. The other is to use synthetic CIR triplets to learn a better mapping for CIR tasks. Our approach achieves SOTA zero-shot performance on the common CIR benchmarks: CIRR and CIRCO.