 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBCTR: Bidirectional Conditioning Transformer for Scene Graph Generation
Jul 26, 2024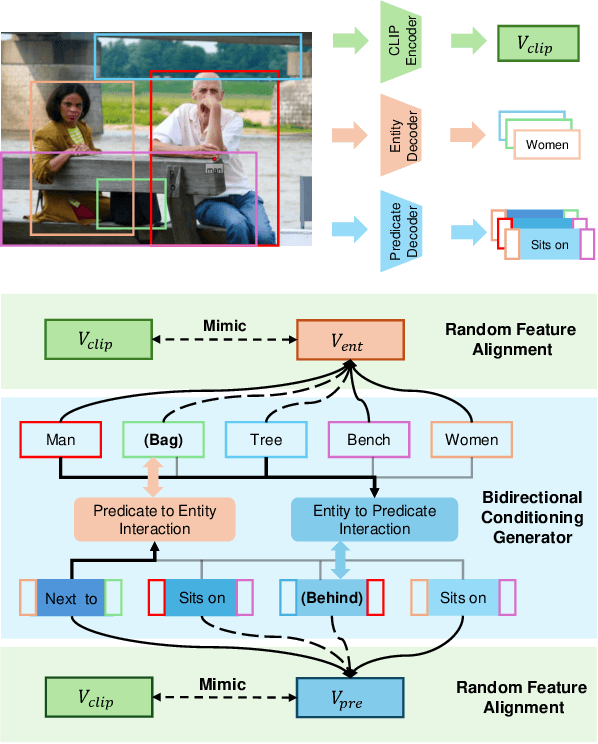
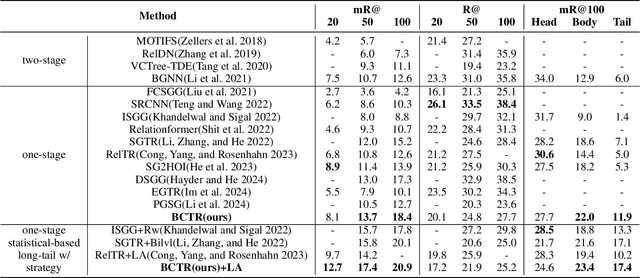
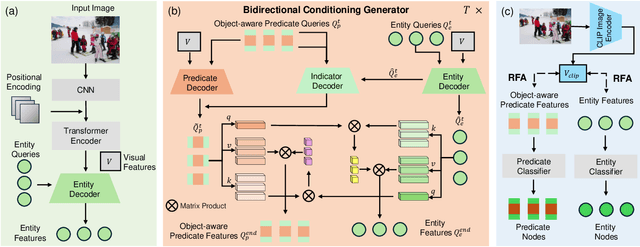
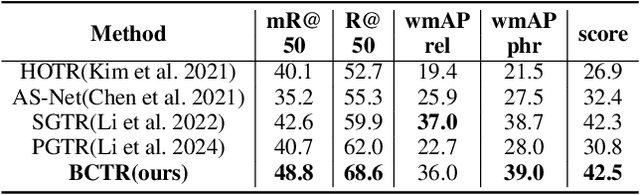
Scene Graph Generation (SGG) remains a challenging task due to its compositional property. Previous approaches improve prediction efficiency by learning in an end-to-end manner. However, these methods exhibit limited performance as they assume unidirectional conditioning between entities and predicates, leading to insufficient information interaction. To address this limitation, we propose a novel bidirectional conditioning factorization for SGG, introducing efficient interaction between entities and predicates. Specifically, we develop an end-to-end scene graph generation model, Bidirectional Conditioning Transformer (BCTR), to implement our factorization. BCTR consists of two key modules. First, the Bidirectional Conditioning Generator (BCG) facilitates multi-stage interactive feature augmentation between entities and predicates, enabling mutual benefits between the two predictions. Second, Random Feature Alignment (RFA) regularizes the feature space by distilling multi-modal knowledge from pre-trained models, enhancing BCTR's ability on tailed categories without relying on statistical priors. We conduct a series of experiments on Visual Genome and Open Image V6, demonstrating that BCTR achieves state-of-the-art performance on both benchmarks. The code will be available upon acceptance of the paper.
HyCIR: Boosting Zero-Shot Composed Image Retrieval with Synthetic Labels
Jul 09, 2024


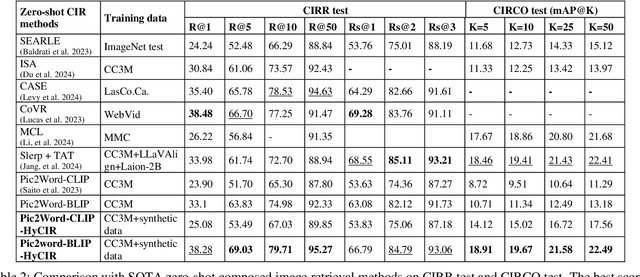
Composed Image Retrieval (CIR) aims to retrieve images based on a query image with text. Current Zero-Shot CIR (ZS-CIR) methods try to solve CIR tasks without using expensive triplet-labeled training datasets. However, the gap between ZS-CIR and triplet-supervised CIR is still large. In this work, we propose Hybrid CIR (HyCIR), which uses synthetic labels to boost the performance of ZS-CIR. A new label Synthesis pipeline for CIR (SynCir) is proposed, in which only unlabeled images are required. First, image pairs are extracted based on visual similarity. Second, query text is generated for each image pair based on vision-language model and LLM. Third, the data is further filtered in language space based on semantic similarity. To improve ZS-CIR performance, we propose a hybrid training strategy to work with both ZS-CIR supervision and synthetic CIR triplets. Two kinds of contrastive learning are adopted. One is to use large-scale unlabeled image dataset to learn an image-to-text mapping with good generalization. The other is to use synthetic CIR triplets to learn a better mapping for CIR tasks. Our approach achieves SOTA zero-shot performance on the common CIR benchmarks: CIRR and CIRCO.
Coordinate Transformer: Achieving Single-stage Multi-person Mesh Recovery from Videos
Aug 20, 2023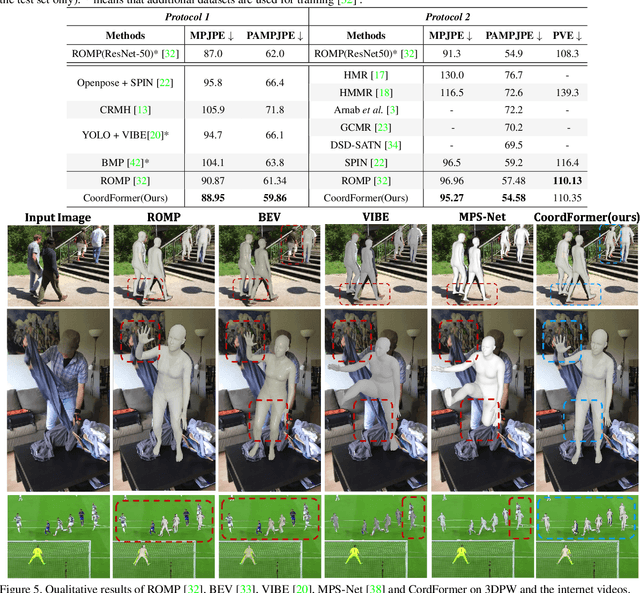
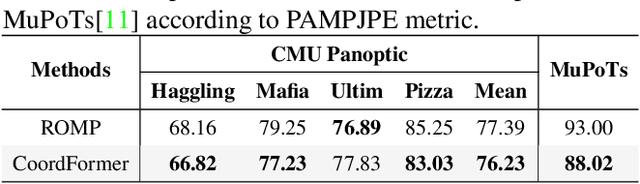

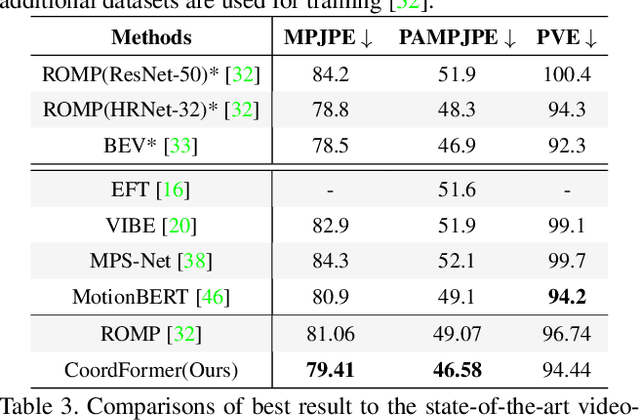
Multi-person 3D mesh recovery from videos is a critical first step towards automatic perception of group behavior in virtual reality, physical therapy and beyond. However, existing approaches rely on multi-stage paradigms, where the person detection and tracking stages are performed in a multi-person setting, while temporal dynamics are only modeled for one person at a time. Consequently, their performance is severely limited by the lack of inter-person interactions in the spatial-temporal mesh recovery, as well as by detection and tracking defects. To address these challenges, we propose the Coordinate transFormer (CoordFormer) that directly models multi-person spatial-temporal relations and simultaneously performs multi-mesh recovery in an end-to-end manner. Instead of partitioning the feature map into coarse-scale patch-wise tokens, CoordFormer leverages a novel Coordinate-Aware Attention to preserve pixel-level spatial-temporal coordinate information. Additionally, we propose a simple, yet effective Body Center Attention mechanism to fuse position information. Extensive experiments on the 3DPW dataset demonstrate that CoordFormer significantly improves the state-of-the-art, outperforming the previously best results by 4.2%, 8.8% and 4.7% according to the MPJPE, PAMPJPE, and PVE metrics, respectively, while being 40% faster than recent video-based approaches. The released code can be found at https://github.com/Li-Hao-yuan/CoordFormer.