 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAM-VLA: A Dynamic Action Model-Based Vision-Language-Action Framework for Robot Manipulation
Mar 01, 2026In dynamic environments such as warehouses, hospitals, and homes, robots must seamlessly transition between gross motion and precise manipulations to complete complex tasks. However, current Vision-Language-Action (VLA) frameworks, largely adapted from pre-trained Vision-Language Models (VLMs), often struggle to reconcile general task adaptability with the specialized precision required for intricate manipulation. To address this challenge, we propose DAM-VLA, a dynamic action model-based VLA framework. DAM-VLA integrates VLM reasoning with diffusion-based action models specialized for arm and gripper control. Specifically, it introduces (i) an action routing mechanism, using task-specific visual and linguistic cues to select appropriate action models (e.g., arm movement or gripper manipulation), (ii) a dynamic action model that fuses high-level VLM cognition with low-level visual features to predict actions, and (iii) a dual-scale action weighting mechanism that enables dynamic coordination between the arm-movement and gripper-manipulation models. Across extensive evaluations, DAM-VLA achieves superior success rates compared to state-of-the-art VLA methods in simulated (SIMPLER, FurnitureBench) and real-world settings, showing robust generalization from standard pick-and-place to demanding long-horizon and contact-rich tasks.
What Really Matters for Robust Multi-Sensor HD Map Construction?
Jul 02, 2025High-definition (HD) map construction methods are crucial for providing precise and comprehensive static environmental information, which is essential for autonomous driving systems. While Camera-LiDAR fusion techniques have shown promising results by integrating data from both modalities, existing approaches primarily focus on improving model accuracy and often neglect the robustness of perception models, which is a critical aspect for real-world applications. In this paper, we explore strategies to enhance the robustness of multi-modal fusion methods for HD map construction while maintaining high accuracy. We propose three key components: data augmentation, a novel multi-modal fusion module, and a modality dropout training strategy. These components are evaluated on a challenging dataset containing 10 days of NuScenes data. Our experimental results demonstrate that our proposed methods significantly enhance the robustness of baseline methods. Furthermore, our approach achieves state-of-the-art performance on the clean validation set of the NuScenes dataset. Our findings provide valuable insights for developing more robust and reliable HD map construction models, advancing their applicability in real-world autonomous driving scenarios. Project website: https://robomap-123.github.io.
NTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
TLA: Tactile-Language-Action Model for Contact-Rich Manipulation
Mar 11, 2025Significant progress has been made in vision-language models. However, language-conditioned robotic manipulation for contact-rich tasks remains underexplored, particularly in terms of tactile sensing. To address this gap, we introduce the Tactile-Language-Action (TLA) model, which effectively processes sequential tactile feedback via cross-modal language grounding to enable robust policy generation in contact-intensive scenarios. In addition, we construct a comprehensive dataset that contains 24k pairs of tactile action instruction data, customized for fingertip peg-in-hole assembly, providing essential resources for TLA training and evaluation. Our results show that TLA significantly outperforms traditional imitation learning methods (e.g., diffusion policy) in terms of effective action generation and action accuracy, while demonstrating strong generalization capabilities by achieving over 85\% success rate on previously unseen assembly clearances and peg shapes. We publicly release all data and code in the hope of advancing research in language-conditioned tactile manipulation skill learning. Project website: https://sites.google.com/view/tactile-language-action/
EHC-MM: Embodied Holistic Control for Mobile Manipulation
Sep 13, 2024



Mobile manipulation typically entails the base for mobility, the arm for accurate manipulation, and the camera for perception. It is necessary to follow the principle of Distant Mobility, Close Grasping(DMCG) in holistic control. We propose Embodied Holistic Control for Mobile Manipulation(EHC-MM) with the embodied function of sig(w): By formulating the DMCG principle as a Quadratic Programming (QP) problem, sig(w) dynamically balances the robot's emphasis between movement and manipulation with the consideration of the robot's state and environment. In addition, we propose the Monitor-Position-Based Servoing (MPBS) with sig(w), enabling the tracking of the target during the operation. This approach allows coordinated control between the robot's base, arm, and camera. Through extensive simulations and real-world experiments, our approach significantly improves both the success rate and efficiency of mobile manipulation tasks, achieving a 95.6% success rate in the real-world scenarios and a 52.8% increase in time efficiency.
MapDistill: Boosting Efficient Camera-based HD Map Construction via Camera-LiDAR Fusion Model Distillation
Jul 16, 2024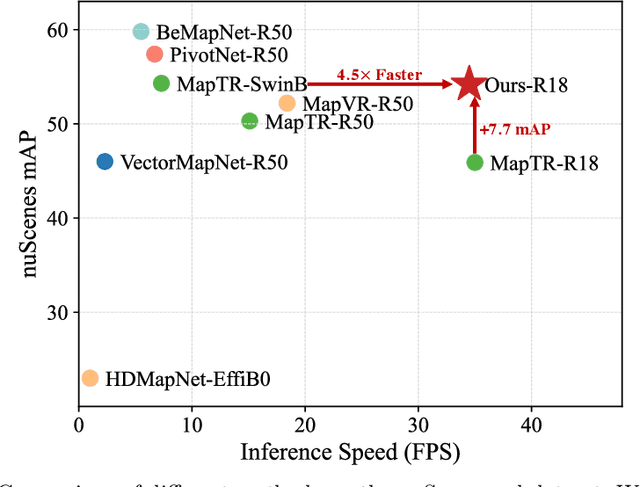
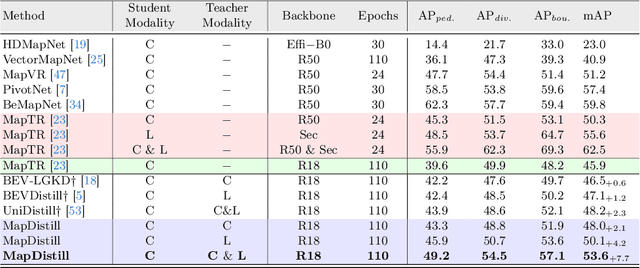
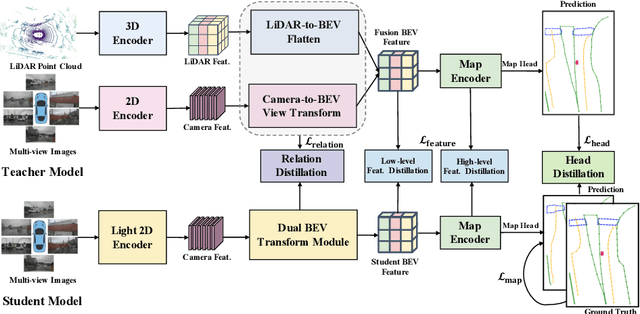
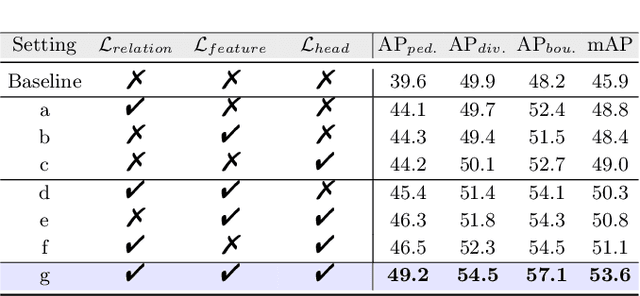
Online high-definition (HD) map construction is an important and challenging task in autonomous driving. Recently, there has been a growing interest in cost-effective multi-view camera-based methods without relying on other sensors like LiDAR. However, these methods suffer from a lack of explicit depth information, necessitating the use of large models to achieve satisfactory performance. To address this, we employ the Knowledge Distillation (KD) idea for efficient HD map construction for the first time and introduce a novel KD-based approach called MapDistill to transfer knowledge from a high-performance camera-LiDAR fusion model to a lightweight camera-only model. Specifically, we adopt the teacher-student architecture, i.e., a camera-LiDAR fusion model as the teacher and a lightweight camera model as the student, and devise a dual BEV transform module to facilitate cross-modal knowledge distillation while maintaining cost-effective camera-only deployment. Additionally, we present a comprehensive distillation scheme encompassing cross-modal relation distillation, dual-level feature distillation, and map head distillation. This approach alleviates knowledge transfer challenges between modalities, enabling the student model to learn improved feature representations for HD map construction. Experimental results on the challenging nuScenes dataset demonstrate the effectiveness of MapDistill, surpassing existing competitors by over 7.7 mAP or 4.5X speedup.
ASGrasp: Generalizable Transparent Object Reconstruction and Grasping from RGB-D Active Stereo Camera
May 09, 2024


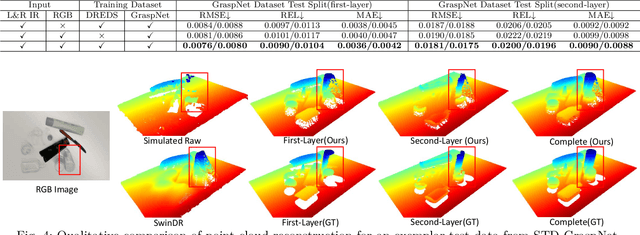
In this paper, we tackle the problem of grasping transparent and specular objects. This issue holds importance, yet it remains unsolved within the field of robotics due to failure of recover their accurate geometry by depth cameras. For the first time, we propose ASGrasp, a 6-DoF grasp detection network that uses an RGB-D active stereo camera. ASGrasp utilizes a two-layer learning-based stereo network for the purpose of transparent object reconstruction, enabling material-agnostic object grasping in cluttered environments. In contrast to existing RGB-D based grasp detection methods, which heavily depend on depth restoration networks and the quality of depth maps generated by depth cameras, our system distinguishes itself by its ability to directly utilize raw IR and RGB images for transparent object geometry reconstruction. We create an extensive synthetic dataset through domain randomization, which is based on GraspNet-1Billion. Our experiments demonstrate that ASGrasp can achieve over 90% success rate for generalizable transparent object grasping in both simulation and the real via seamless sim-to-real transfer. Our method significantly outperforms SOTA networks and even surpasses the performance upper bound set by perfect visible point cloud inputs.Project page: https://pku-epic.github.io/ASGrasp
What Foundation Models can Bring for Robot Learning in Manipulation : A Survey
Apr 28, 2024



The realization of universal robots is an ultimate goal of researchers. However, a key hurdle in achieving this goal lies in the robots' ability to manipulate objects in their unstructured surrounding environments according to different tasks. The learning-based approach is considered an effective way to address generalization. The impressive performance of foundation models in the fields of computer vision and natural language suggests the potential of embedding foundation models into manipulation tasks as a viable path toward achieving general manipulation capability. However, we believe achieving general manipulation capability requires an overarching framework akin to auto driving. This framework should encompass multiple functional modules, with different foundation models assuming distinct roles in facilitating general manipulation capability. This survey focuses on the contributions of foundation models to robot learning for manipulation. We propose a comprehensive framework and detail how foundation models can address challenges in each module of the framework. What's more, we examine current approaches, outline challenges, suggest future research directions, and identify potential risks associated with integrating foundation models into this domain.
RobotGPT: Robot Manipulation Learning from ChatGPT
Dec 03, 2023



We present RobotGPT, an innovative decision framework for robotic manipulation that prioritizes stability and safety. The execution code generated by ChatGPT cannot guarantee the stability and safety of the system. ChatGPT may provide different answers for the same task, leading to unpredictability. This instability prevents the direct integration of ChatGPT into the robot manipulation loop. Although setting the temperature to 0 can generate more consistent outputs, it may cause ChatGPT to lose diversity and creativity. Our objective is to leverage ChatGPT's problem-solving capabilities in robot manipulation and train a reliable agent. The framework includes an effective prompt structure and a robust learning model. Additionally, we introduce a metric for measuring task difficulty to evaluate ChatGPT's performance in robot manipulation. Furthermore, we evaluate RobotGPT in both simulation and real-world environments. Compared to directly using ChatGPT to generate code, our framework significantly improves task success rates, with an average increase from 38.5% to 91.5%. Therefore, training a RobotGPT by utilizing ChatGPT as an expert is a more stable approach compared to directly using ChatGPT as a task planner.