 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseVoxFormer: Sparse Voxel-based Transformer for Multi-modal 3D Object Detection
Mar 11, 2025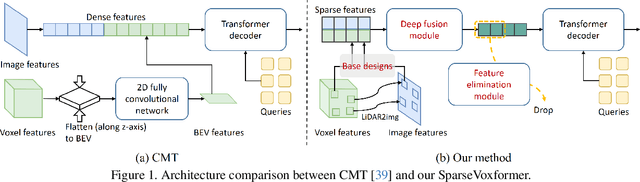

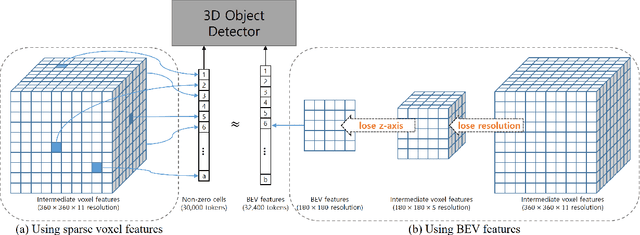
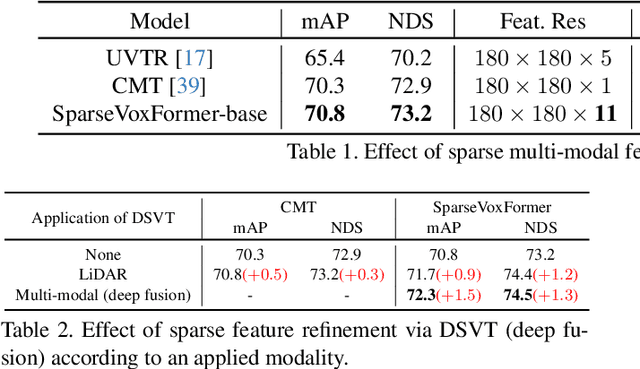
Most previous 3D object detection methods that leverage the multi-modality of LiDAR and cameras utilize the Bird's Eye View (BEV) space for intermediate feature representation. However, this space uses a low x, y-resolution and sacrifices z-axis information to reduce the overall feature resolution, which may result in declined accuracy. To tackle the problem of using low-resolution features, this paper focuses on the sparse nature of LiDAR point cloud data. From our observation, the number of occupied cells in the 3D voxels constructed from a LiDAR data can be even fewer than the number of total cells in the BEV map, despite the voxels' significantly higher resolution. Based on this, we introduce a novel sparse voxel-based transformer network for 3D object detection, dubbed as SparseVoxFormer. Instead of performing BEV feature extraction, we directly leverage sparse voxel features as the input for a transformer-based detector. Moreover, with regard to the camera modality, we introduce an explicit modality fusion approach that involves projecting 3D voxel coordinates onto 2D images and collecting the corresponding image features. Thanks to these components, our approach can leverage geometrically richer multi-modal features while even reducing the computational cost. Beyond the proof-of-concept level, we further focus on facilitating better multi-modal fusion and flexible control over the number of sparse features. Finally, thorough experimental results demonstrate that utilizing a significantly smaller number of sparse features drastically reduces computational costs in a 3D object detector while enhancing both overall and long-range performance.
MapDistill: Boosting Efficient Camera-based HD Map Construction via Camera-LiDAR Fusion Model Distillation
Jul 16, 2024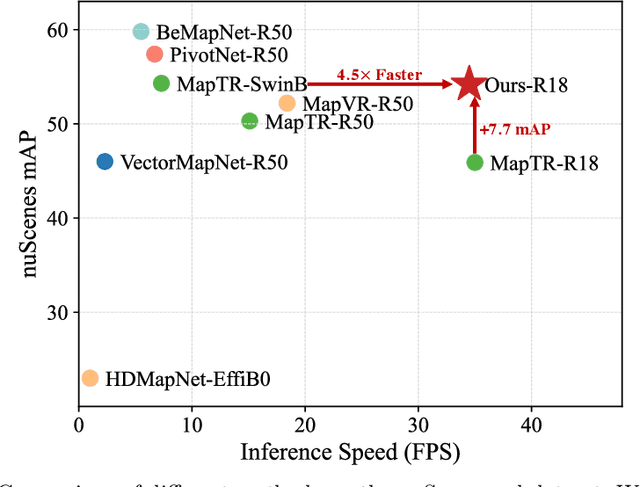
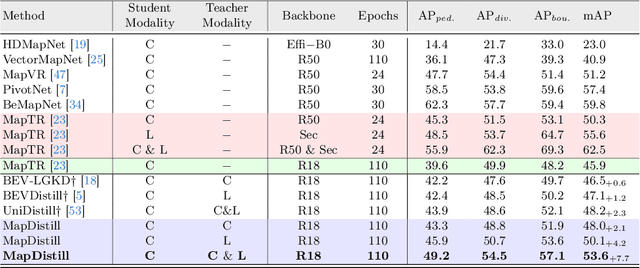
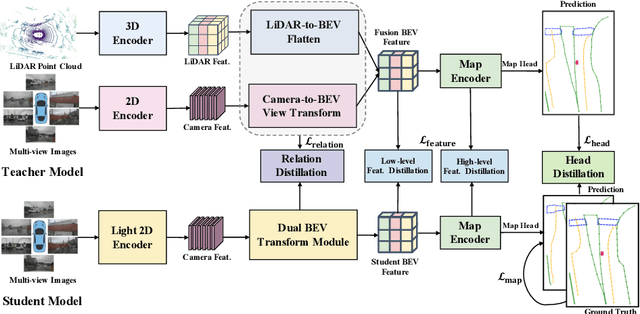
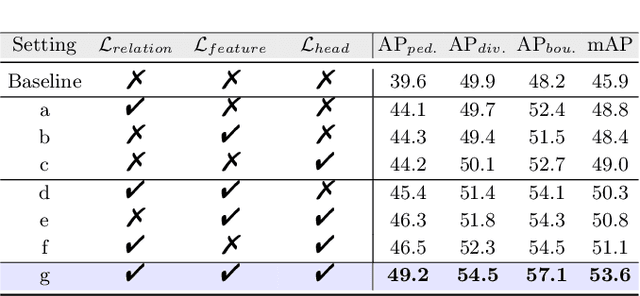
Online high-definition (HD) map construction is an important and challenging task in autonomous driving. Recently, there has been a growing interest in cost-effective multi-view camera-based methods without relying on other sensors like LiDAR. However, these methods suffer from a lack of explicit depth information, necessitating the use of large models to achieve satisfactory performance. To address this, we employ the Knowledge Distillation (KD) idea for efficient HD map construction for the first time and introduce a novel KD-based approach called MapDistill to transfer knowledge from a high-performance camera-LiDAR fusion model to a lightweight camera-only model. Specifically, we adopt the teacher-student architecture, i.e., a camera-LiDAR fusion model as the teacher and a lightweight camera model as the student, and devise a dual BEV transform module to facilitate cross-modal knowledge distillation while maintaining cost-effective camera-only deployment. Additionally, we present a comprehensive distillation scheme encompassing cross-modal relation distillation, dual-level feature distillation, and map head distillation. This approach alleviates knowledge transfer challenges between modalities, enabling the student model to learn improved feature representations for HD map construction. Experimental results on the challenging nuScenes dataset demonstrate the effectiveness of MapDistill, surpassing existing competitors by over 7.7 mAP or 4.5X speedup.
HIMap: HybrId Representation Learning for End-to-end Vectorized HD Map Construction
Mar 26, 2024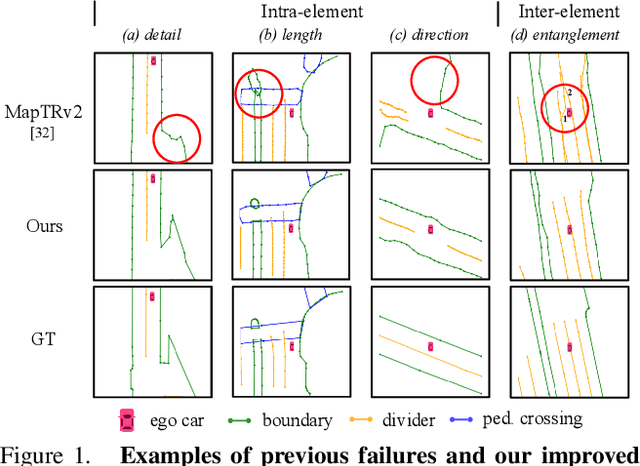
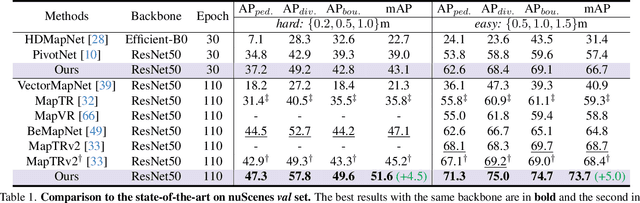

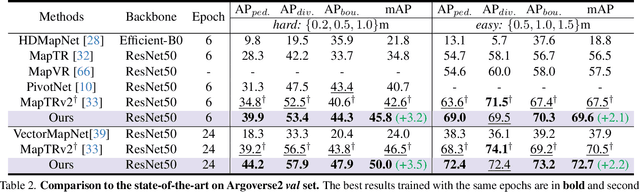
Vectorized High-Definition (HD) map construction requires predictions of the category and point coordinates of map elements (e.g. road boundary, lane divider, pedestrian crossing, etc.). State-of-the-art methods are mainly based on point-level representation learning for regressing accurate point coordinates. However, this pipeline has limitations in obtaining element-level information and handling element-level failures, e.g. erroneous element shape or entanglement between elements. To tackle the above issues, we propose a simple yet effective HybrId framework named HIMap to sufficiently learn and interact both point-level and element-level information. Concretely, we introduce a hybrid representation called HIQuery to represent all map elements, and propose a point-element interactor to interactively extract and encode the hybrid information of elements, e.g. point position and element shape, into the HIQuery. Additionally, we present a point-element consistency constraint to enhance the consistency between the point-level and element-level information. Finally, the output point-element integrated HIQuery can be directly converted into map elements' class, point coordinates, and mask. We conduct extensive experiments and consistently outperform previous methods on both nuScenes and Argoverse2 datasets. Notably, our method achieves $77.8$ mAP on the nuScenes dataset, remarkably superior to previous SOTAs by $8.3$ mAP at least.
Object-Centric Multi-Task Learning for Human Instances
Mar 13, 2023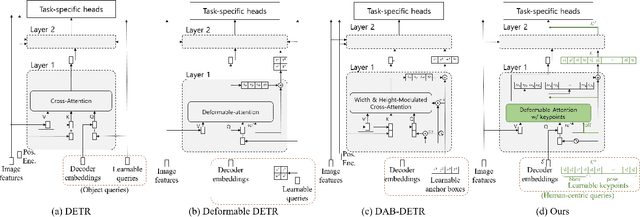

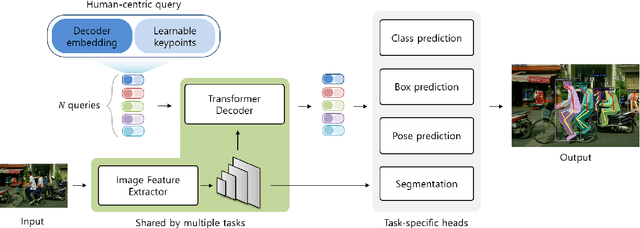
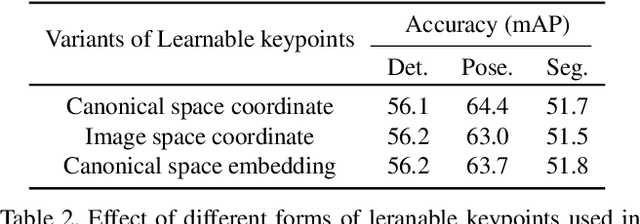
Human is one of the most essential classes in visual recognition tasks such as detection, segmentation, and pose estimation. Although much effort has been put into individual tasks, multi-task learning for these three tasks has been rarely studied. In this paper, we explore a compact multi-task network architecture that maximally shares the parameters of the multiple tasks via object-centric learning. To this end, we propose a novel query design to encode the human instance information effectively, called human-centric query (HCQ). HCQ enables for the query to learn explicit and structural information of human as well such as keypoints. Besides, we utilize HCQ in prediction heads of the target tasks directly and also interweave HCQ with the deformable attention in Transformer decoders to exploit a well-learned object-centric representation. Experimental results show that the proposed multi-task network achieves comparable accuracy to state-of-the-art task-specific models in human detection, segmentation, and pose estimation task, while it consumes less computational costs.