 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseVoxFormer: Sparse Voxel-based Transformer for Multi-modal 3D Object Detection
Mar 11, 2025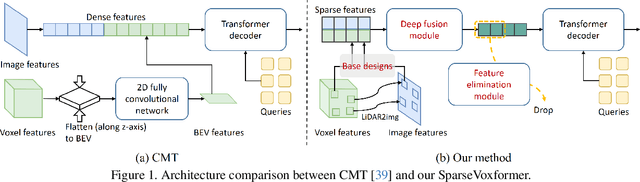

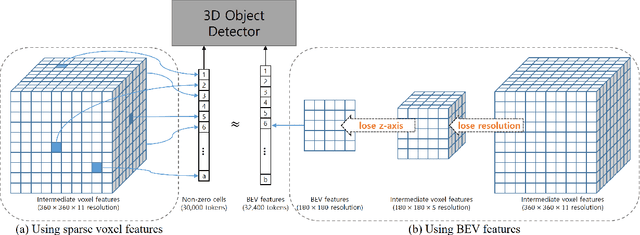
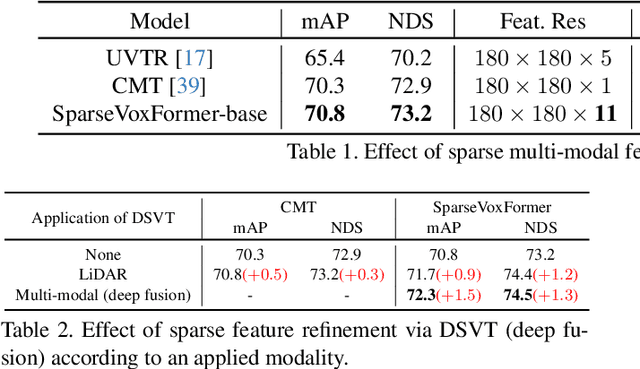
Most previous 3D object detection methods that leverage the multi-modality of LiDAR and cameras utilize the Bird's Eye View (BEV) space for intermediate feature representation. However, this space uses a low x, y-resolution and sacrifices z-axis information to reduce the overall feature resolution, which may result in declined accuracy. To tackle the problem of using low-resolution features, this paper focuses on the sparse nature of LiDAR point cloud data. From our observation, the number of occupied cells in the 3D voxels constructed from a LiDAR data can be even fewer than the number of total cells in the BEV map, despite the voxels' significantly higher resolution. Based on this, we introduce a novel sparse voxel-based transformer network for 3D object detection, dubbed as SparseVoxFormer. Instead of performing BEV feature extraction, we directly leverage sparse voxel features as the input for a transformer-based detector. Moreover, with regard to the camera modality, we introduce an explicit modality fusion approach that involves projecting 3D voxel coordinates onto 2D images and collecting the corresponding image features. Thanks to these components, our approach can leverage geometrically richer multi-modal features while even reducing the computational cost. Beyond the proof-of-concept level, we further focus on facilitating better multi-modal fusion and flexible control over the number of sparse features. Finally, thorough experimental results demonstrate that utilizing a significantly smaller number of sparse features drastically reduces computational costs in a 3D object detector while enhancing both overall and long-range performance.
Object-Centric Multi-Task Learning for Human Instances
Mar 13, 2023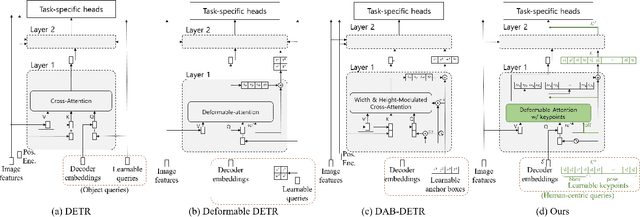

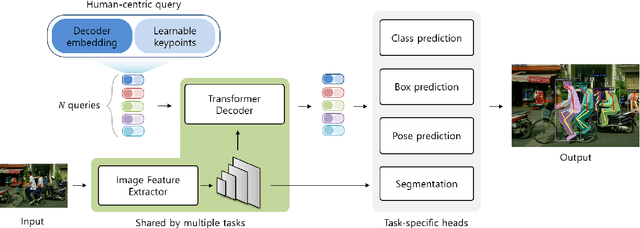
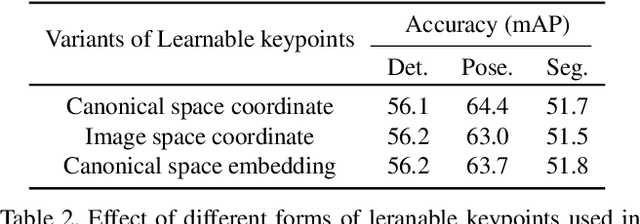
Human is one of the most essential classes in visual recognition tasks such as detection, segmentation, and pose estimation. Although much effort has been put into individual tasks, multi-task learning for these three tasks has been rarely studied. In this paper, we explore a compact multi-task network architecture that maximally shares the parameters of the multiple tasks via object-centric learning. To this end, we propose a novel query design to encode the human instance information effectively, called human-centric query (HCQ). HCQ enables for the query to learn explicit and structural information of human as well such as keypoints. Besides, we utilize HCQ in prediction heads of the target tasks directly and also interweave HCQ with the deformable attention in Transformer decoders to exploit a well-learned object-centric representation. Experimental results show that the proposed multi-task network achieves comparable accuracy to state-of-the-art task-specific models in human detection, segmentation, and pose estimation task, while it consumes less computational costs.
Real-Time Video Deblurring via Lightweight Motion Compensation
Jun 08, 2022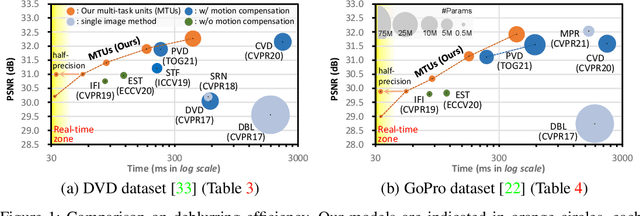

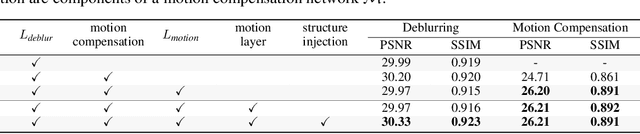
While motion compensation greatly improves video deblurring quality, separately performing motion compensation and video deblurring demands huge computational overhead. This paper proposes a real-time video deblurring framework consisting of a lightweight multi-task unit that supports both video deblurring and motion compensation in an efficient way. The multi-task unit is specifically designed to handle large portions of the two tasks using a single shared network, and consists of a multi-task detail network and simple networks for deblurring and motion compensation. The multi-task unit minimizes the cost of incorporating motion compensation into video deblurring and enables real-time deblurring. Moreover, by stacking multiple multi-task units, our framework provides flexible control between the cost and deblurring quality. We experimentally validate the state-of-the-art deblurring quality of our approach, which runs at a much faster speed compared to previous methods, and show practical real-time performance (30.99dB@30fps measured in the DVD dataset).
Iterative Filter Adaptive Network for Single Image Defocus Deblurring
Aug 31, 2021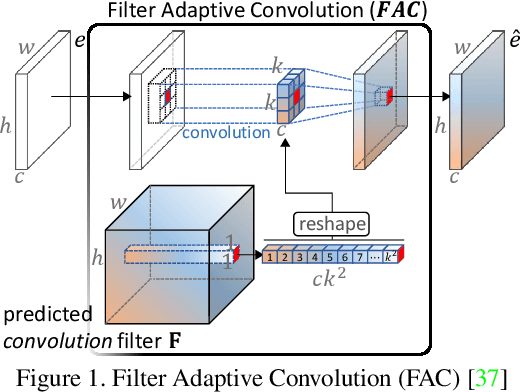
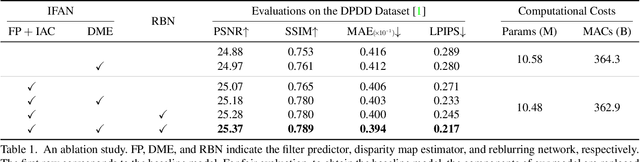
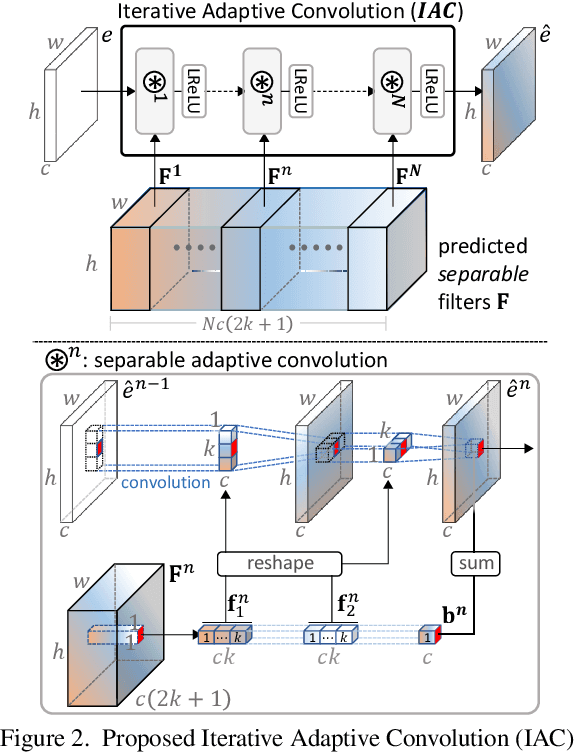
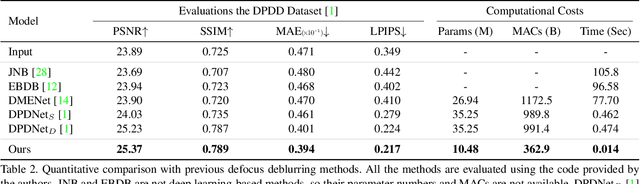
We propose a novel end-to-end learning-based approach for single image defocus deblurring. The proposed approach is equipped with a novel Iterative Filter Adaptive Network (IFAN) that is specifically designed to handle spatially-varying and large defocus blur. For adaptively handling spatially-varying blur, IFAN predicts pixel-wise deblurring filters, which are applied to defocused features of an input image to generate deblurred features. For effectively managing large blur, IFAN models deblurring filters as stacks of small-sized separable filters. Predicted separable deblurring filters are applied to defocused features using a novel Iterative Adaptive Convolution (IAC) layer. We also propose a training scheme based on defocus disparity estimation and reblurring, which significantly boosts the deblurring quality. We demonstrate that our method achieves state-of-the-art performance both quantitatively and qualitatively on real-world images.
* CVPR 2021
Recurrent Video Deblurring with Blur-Invariant Motion Estimation and Pixel Volumes
Aug 23, 2021
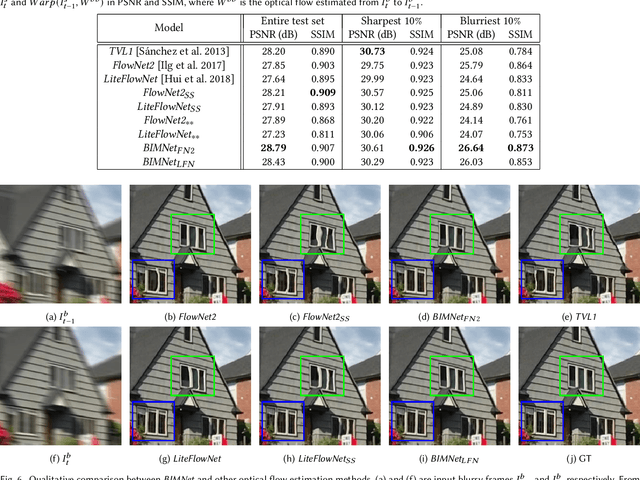
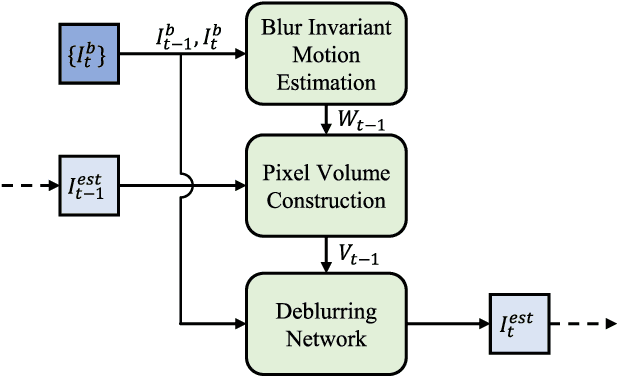
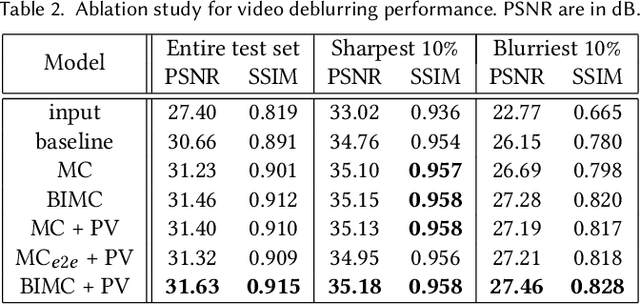
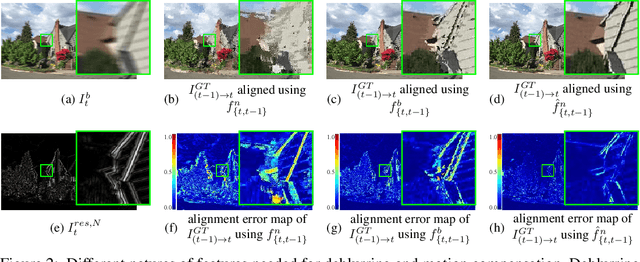
For the success of video deblurring, it is essential to utilize information from neighboring frames. Most state-of-the-art video deblurring methods adopt motion compensation between video frames to aggregate information from multiple frames that can help deblur a target frame. However, the motion compensation methods adopted by previous deblurring methods are not blur-invariant, and consequently, their accuracy is limited for blurry frames with different blur amounts. To alleviate this problem, we propose two novel approaches to deblur videos by effectively aggregating information from multiple video frames. First, we present blur-invariant motion estimation learning to improve motion estimation accuracy between blurry frames. Second, for motion compensation, instead of aligning frames by warping with estimated motions, we use a pixel volume that contains candidate sharp pixels to resolve motion estimation errors. We combine these two processes to propose an effective recurrent video deblurring network that fully exploits deblurred previous frames. Experiments show that our method achieves the state-of-the-art performance both quantitatively and qualitatively compared to recent methods that use deep learning.
Single Image Defocus Deblurring Using Kernel-Sharing Parallel Atrous Convolutions
Aug 20, 2021


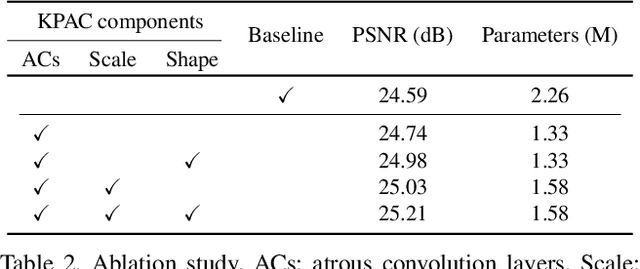
This paper proposes a novel deep learning approach for single image defocus deblurring based on inverse kernels. In a defocused image, the blur shapes are similar among pixels although the blur sizes can spatially vary. To utilize the property with inverse kernels, we exploit the observation that when only the size of a defocus blur changes while keeping the shape, the shape of the corresponding inverse kernel remains the same and only the scale changes. Based on the observation, we propose a kernel-sharing parallel atrous convolutional (KPAC) block specifically designed by incorporating the property of inverse kernels for single image defocus deblurring. To effectively simulate the invariant shapes of inverse kernels with different scales, KPAC shares the same convolutional weights among multiple atrous convolution layers. To efficiently simulate the varying scales of inverse kernels, KPAC consists of only a few atrous convolution layers with different dilations and learns per-pixel scale attentions to aggregate the outputs of the layers. KPAC also utilizes the shape attention to combine the outputs of multiple convolution filters in each atrous convolution layer, to deal with defocus blur with a slightly varying shape. We demonstrate that our approach achieves state-of-the-art performance with a much smaller number of parameters than previous methods.