 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen Set Dandelion Network for IoT Intrusion Detection
Nov 19, 2023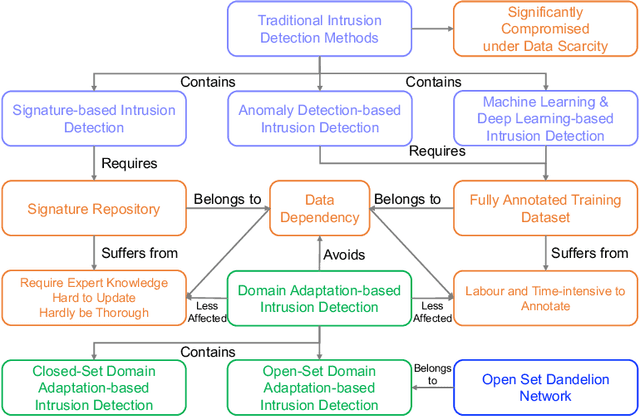
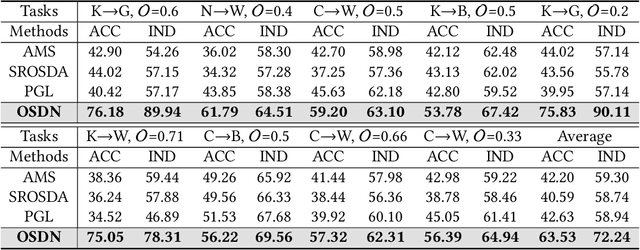
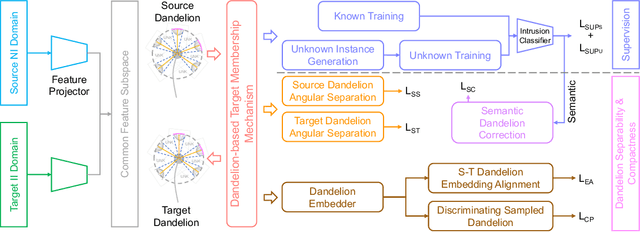
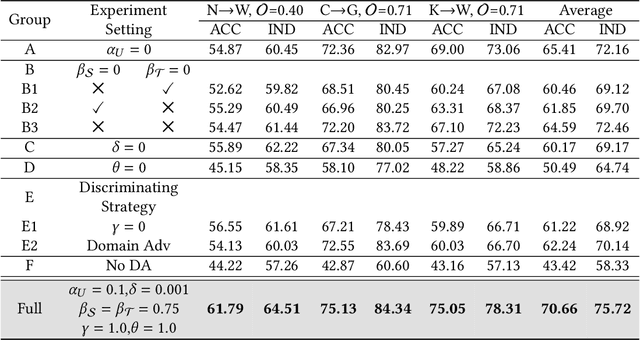
As IoT devices become widely, it is crucial to protect them from malicious intrusions. However, the data scarcity of IoT limits the applicability of traditional intrusion detection methods, which are highly data-dependent. To address this, in this paper we propose the Open-Set Dandelion Network (OSDN) based on unsupervised heterogeneous domain adaptation in an open-set manner. The OSDN model performs intrusion knowledge transfer from the knowledge-rich source network intrusion domain to facilitate more accurate intrusion detection for the data-scarce target IoT intrusion domain. Under the open-set setting, it can also detect newly-emerged target domain intrusions that are not observed in the source domain. To achieve this, the OSDN model forms the source domain into a dandelion-like feature space in which each intrusion category is compactly grouped and different intrusion categories are separated, i.e., simultaneously emphasising inter-category separability and intra-category compactness. The dandelion-based target membership mechanism then forms the target dandelion. Then, the dandelion angular separation mechanism achieves better inter-category separability, and the dandelion embedding alignment mechanism further aligns both dandelions in a finer manner. To promote intra-category compactness, the discriminating sampled dandelion mechanism is used. Assisted by the intrusion classifier trained using both known and generated unknown intrusion knowledge, a semantic dandelion correction mechanism emphasises easily-confused categories and guides better inter-category separability. Holistically, these mechanisms form the OSDN model that effectively performs intrusion knowledge transfer to benefit IoT intrusion detection. Comprehensive experiments on several intrusion datasets verify the effectiveness of the OSDN model, outperforming three state-of-the-art baseline methods by 16.9%.
Adaptive Bi-Recommendation and Self-Improving Network for Heterogeneous Domain Adaptation-Assisted IoT Intrusion Detection
Mar 25, 2023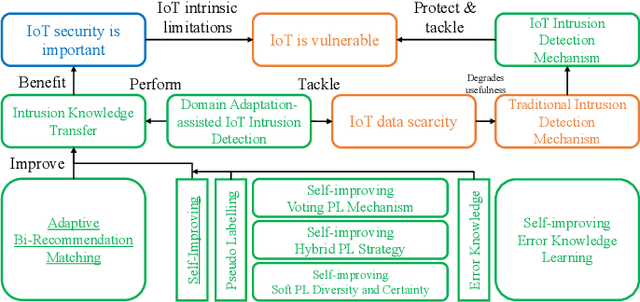
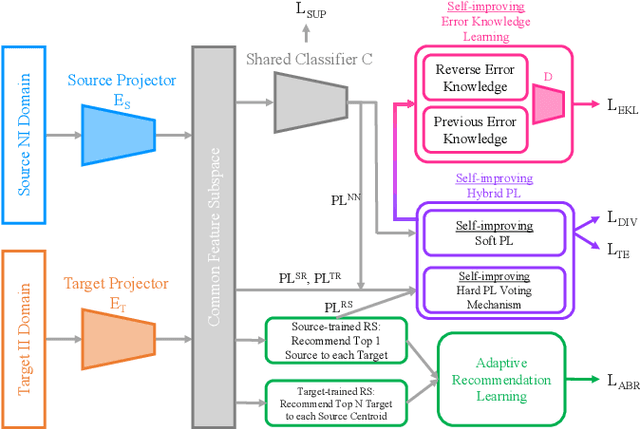
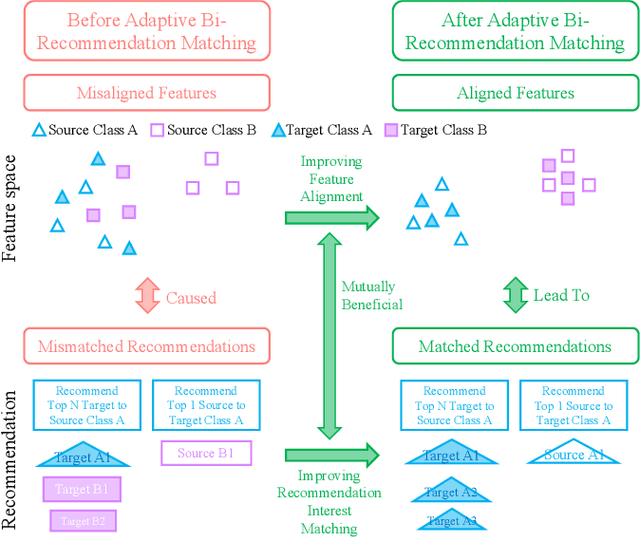
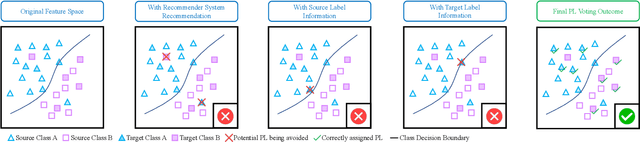
As Internet of Things devices become prevalent, using intrusion detection to protect IoT from malicious intrusions is of vital importance. However, the data scarcity of IoT hinders the effectiveness of traditional intrusion detection methods. To tackle this issue, in this paper, we propose the Adaptive Bi-Recommendation and Self-Improving Network (ABRSI) based on unsupervised heterogeneous domain adaptation (HDA). The ABRSI transfers enrich intrusion knowledge from a data-rich network intrusion source domain to facilitate effective intrusion detection for data-scarce IoT target domains. The ABRSI achieves fine-grained intrusion knowledge transfer via adaptive bi-recommendation matching. Matching the bi-recommendation interests of two recommender systems and the alignment of intrusion categories in the shared feature space form a mutual-benefit loop. Besides, the ABRSI uses a self-improving mechanism, autonomously improving the intrusion knowledge transfer from four ways. A hard pseudo label voting mechanism jointly considers recommender system decision and label relationship information to promote more accurate hard pseudo label assignment. To promote diversity and target data participation during intrusion knowledge transfer, target instances failing to be assigned with a hard pseudo label will be assigned with a probabilistic soft pseudo label, forming a hybrid pseudo-labelling strategy. Meanwhile, the ABRSI also makes soft pseudo-labels globally diverse and individually certain. Finally, an error knowledge learning mechanism is utilised to adversarially exploit factors that causes detection ambiguity and learns through both current and previous error knowledge, preventing error knowledge forgetfulness. Holistically, these mechanisms form the ABRSI model that boosts IoT intrusion detection accuracy via HDA-assisted intrusion knowledge transfer.
Heterogeneous Domain Adaptation for IoT Intrusion Detection: A Geometric Graph Alignment Approach
Jan 24, 2023Data scarcity hinders the usability of data-dependent algorithms when tackling IoT intrusion detection (IID). To address this, we utilise the data rich network intrusion detection (NID) domain to facilitate more accurate intrusion detection for IID domains. In this paper, a Geometric Graph Alignment (GGA) approach is leveraged to mask the geometric heterogeneities between domains for better intrusion knowledge transfer. Specifically, each intrusion domain is formulated as a graph where vertices and edges represent intrusion categories and category-wise interrelationships, respectively. The overall shape is preserved via a confused discriminator incapable to identify adjacency matrices between different intrusion domain graphs. A rotation avoidance mechanism and a centre point matching mechanism is used to avoid graph misalignment due to rotation and symmetry, respectively. Besides, category-wise semantic knowledge is transferred to act as vertex-level alignment. To exploit the target data, a pseudo-label election mechanism that jointly considers network prediction, geometric property and neighbourhood information is used to produce fine-grained pseudo-label assignment. Upon aligning the intrusion graphs geometrically from different granularities, the transferred intrusion knowledge can boost IID performance. Comprehensive experiments on several intrusion datasets demonstrate state-of-the-art performance of the GGA approach and validate the usefulness of GGA constituting components.
Multi-Scenario Bimetric-Balanced IoT Resource Allocation: An Evolutionary Approach
Nov 10, 2022



In this paper, we allocate IoT devices as resources for smart services with time-constrained resource requirements. The allocation method named as BRAD can work under multiple resource scenarios with diverse resource richnesses, availabilities and costs, such as the intelligent healthcare system deployed by Harbin Institute of Technology (HIT-IHC). The allocation aims for bimetric-balancing under the multi-scenario case, i.e., the profit and cost associated with service satisfaction are jointly optimised and balanced wisely. Besides, we abstract IoT devices as digital objects (DO) to make them easier to interact with during resource allocation. Considering that the problem is NP-Hard and the optimisation objective is not differentiable, we utilise Grey Wolf Optimisation (GWO) algorithm as the model optimiser. Specifically, we tackle the deficiencies of GWO and significantly improve its performance by introducing three new mechanisms to form the BRAD-GWA algorithm. Comprehensive experiments are conducted on realistic HIT-IHC IoT testbeds and several algorithms are compared, including the allocation method originally used by HIT-IHC system to verify the effectiveness of the BRAD-GWA. The BRAD-GWA achieves a 3.14 times and 29.6% objective reduction compared with the HIT-IHC and the original GWO algorithm, respectively.
Joint Semantic Transfer Network for IoT Intrusion Detection
Oct 28, 2022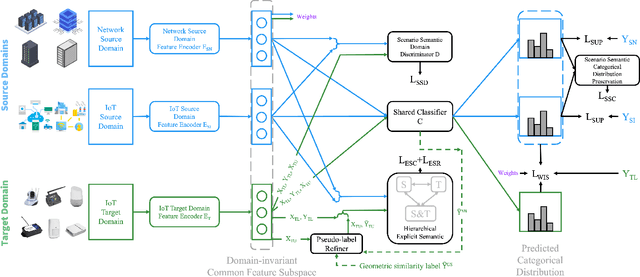

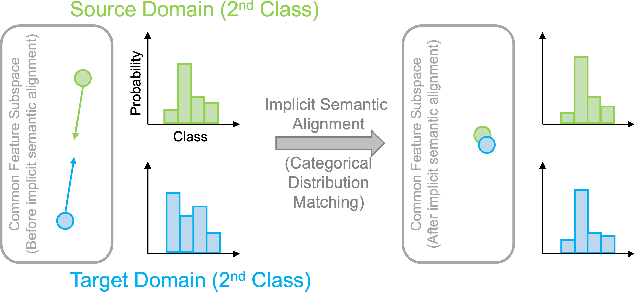
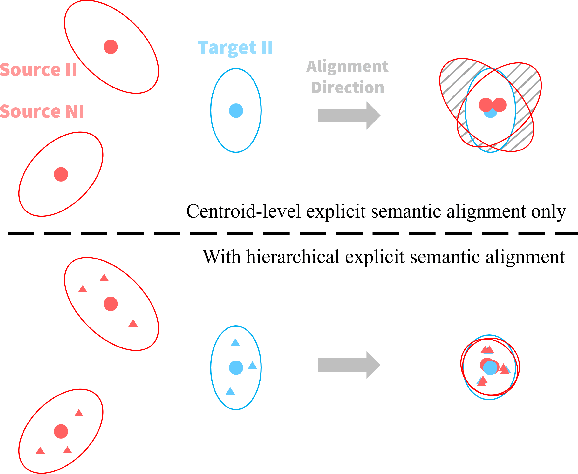
In this paper, we propose a Joint Semantic Transfer Network (JSTN) towards effective intrusion detection for large-scale scarcely labelled IoT domain. As a multi-source heterogeneous domain adaptation (MS-HDA) method, the JSTN integrates a knowledge rich network intrusion (NI) domain and another small-scale IoT intrusion (II) domain as source domains, and preserves intrinsic semantic properties to assist target II domain intrusion detection. The JSTN jointly transfers the following three semantics to learn a domain-invariant and discriminative feature representation. The scenario semantic endows source NI and II domain with characteristics from each other to ease the knowledge transfer process via a confused domain discriminator and categorical distribution knowledge preservation. It also reduces the source-target discrepancy to make the shared feature space domain-invariant. Meanwhile, the weighted implicit semantic transfer boosts discriminability via a fine-grained knowledge preservation, which transfers the source categorical distribution to the target domain. The source-target divergence guides the importance weighting during knowledge preservation to reflect the degree of knowledge learning. Additionally, the hierarchical explicit semantic alignment performs centroid-level and representative-level alignment with the help of a geometric similarity-aware pseudo-label refiner, which exploits the value of unlabelled target II domain and explicitly aligns feature representations from a global and local perspective in a concentrated manner. Comprehensive experiments on various tasks verify the superiority of the JSTN against state-of-the-art comparing methods, on average a 10.3% of accuracy boost is achieved. The statistical soundness of each constituting component and the computational efficiency are also verified.
PECCO: A Profit and Cost-oriented Computation Offloading Scheme in Edge-Cloud Environment with Improved Moth-flame Optimisation
Aug 09, 2022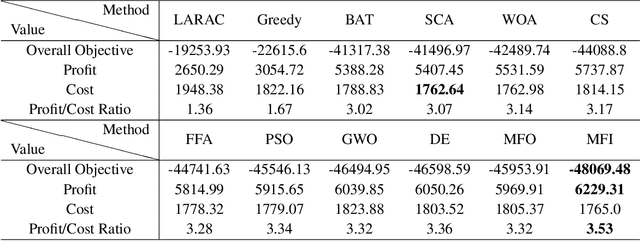
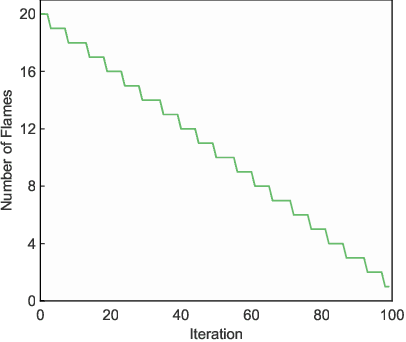
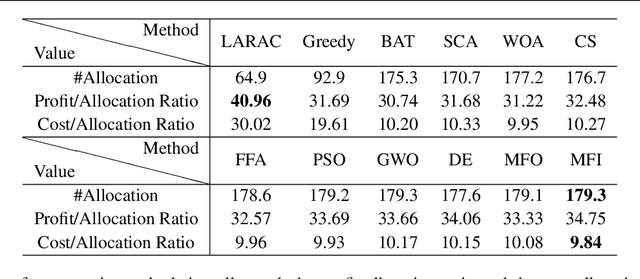
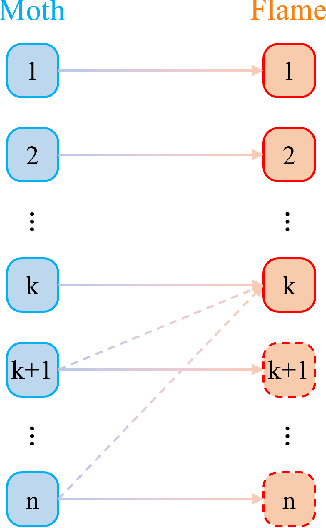
With the fast growing quantity of data generated by smart devices and the exponential surge of processing demand in the Internet of Things (IoT) era, the resource-rich cloud centres have been utilised to tackle these challenges. To relieve the burden on cloud centres, edge-cloud computation offloading becomes a promising solution since shortening the proximity between the data source and the computation by offloading computation tasks from the cloud to edge devices can improve performance and Quality of Service (QoS). Several optimisation models of edge-cloud computation offloading have been proposed that take computation costs and heterogeneous communication costs into account. However, several important factors are not jointly considered, such as heterogeneities of tasks, load balancing among nodes and the profit yielded by computation tasks, which lead to the profit and cost-oriented computation offloading optimisation model PECCO proposed in this paper. Considering that the model is hard in nature and the optimisation objective is not differentiable, we propose an improved Moth-flame optimiser PECCO-MFI which addresses some deficiencies of the original Moth-flame Optimiser and integrate it under the edge-cloud environment. Comprehensive experiments are conducted to verify the superior performance of the proposed method when optimising the proposed task offloading model under the edge-cloud environment.
Learning to Rank with Small Set of Ground Truth Data
Jul 04, 2022


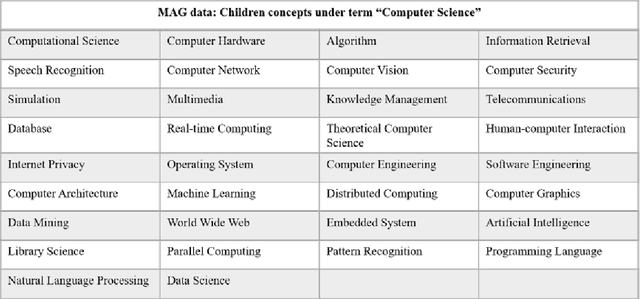
Over the past decades, researchers had put lots of effort investigating ranking techniques used to rank query results retrieved during information retrieval, or to rank the recommended products in recommender systems. In this project, we aim to investigate searching, ranking, as well as recommendation techniques to help to realize a university academia searching platform. Unlike the usual information retrieval scenarios where lots of ground truth ranking data is present, in our case, we have only limited ground truth knowledge regarding the academia ranking. For instance, given some search queries, we only know a few researchers who are highly relevant and thus should be ranked at the top, and for some other search queries, we have no knowledge about which researcher should be ranked at the top at all. The limited amount of ground truth data makes some of the conventional ranking techniques and evaluation metrics become infeasible, and this is a huge challenge we faced during this project. This project enhances the user's academia searching experience to a large extent, it helps to achieve an academic searching platform which includes researchers, publications and fields of study information, which will be beneficial not only to the university faculties but also to students' research experiences.
Simultaneous Semantic Alignment Network for Heterogeneous Domain Adaptation
Aug 05, 2020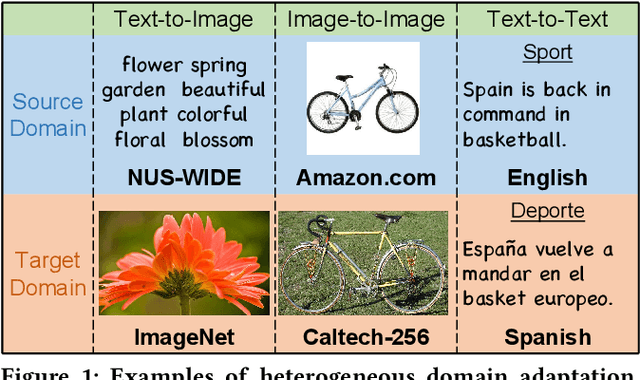
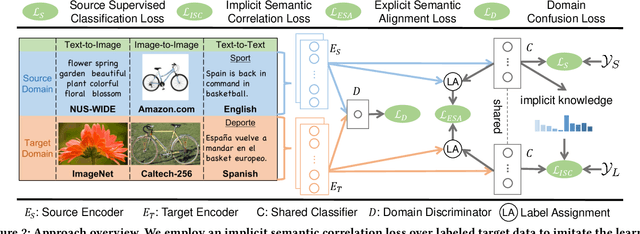
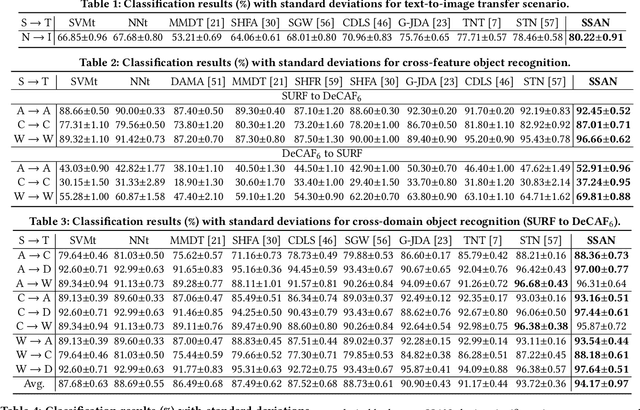
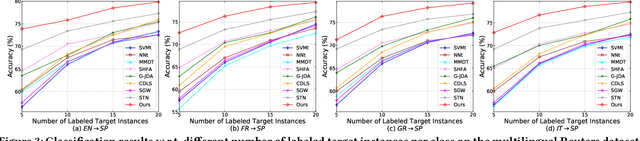
Heterogeneous domain adaptation (HDA) transfers knowledge across source and target domains that present heterogeneities e.g., distinct domain distributions and difference in feature type or dimension. Most previous HDA methods tackle this problem through learning a domain-invariant feature subspace to reduce the discrepancy between domains. However, the intrinsic semantic properties contained in data are under-explored in such alignment strategy, which is also indispensable to achieve promising adaptability. In this paper, we propose a Simultaneous Semantic Alignment Network (SSAN) to simultaneously exploit correlations among categories and align the centroids for each category across domains. In particular, we propose an implicit semantic correlation loss to transfer the correlation knowledge of source categorical prediction distributions to target domain. Meanwhile, by leveraging target pseudo-labels, a robust triplet-centroid alignment mechanism is explicitly applied to align feature representations for each category. Notably, a pseudo-label refinement procedure with geometric similarity involved is introduced to enhance the target pseudo-label assignment accuracy. Comprehensive experiments on various HDA tasks across text-to-image, image-to-image and text-to-text successfully validate the superiority of our SSAN against state-of-the-art HDA methods. The code is publicly available at https://github.com/BIT-DA/SSAN.