 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Clarification in LLM Agents with Information Gain
Jun 02, 2026Large Language Model (LLM) agents often operate under underspecified user instructions, where latent uncertainty over user intent leads to erroneous tool actions. To address this challenge, we propose a goal-oriented clarification framework that aligns clarification behavior with ambiguity resolution. Central to our approach is the Information Gain Reward, a metric that quantifies the utility of clarification questions by measuring the Bayesian belief update towards the ground-truth goal induced by the clarification exchange. We train the clarifier (LLM) using this reward to optimize for high information gain, ensuring that clarifications effectively reduce uncertainty and improve task completion within the agent-tool-user environment. We validate our framework within a clarification-enhanced $τ$-Bench environment, conducting cross-agent evaluations across five heterogeneous backbones. Empirical results demonstrate that our method consistently improves the success rate by 3.7\% over the no-clarification baseline, while adding only 0.3 total interaction steps on average.
HiSE: A Lightweight Hierarchical Semantic Explainer for Heterogeneous Graph Neural Networks
Jun 02, 2026Heterogeneous graph neural networks (HGNNs) have demonstrated remarkable performance in modeling complex relational data, however their interpretability in high-stakes applications remains a critical challenge. Existing explanation methods suffer from two major limitations: on the one hand, the generated explanations fail to reflect the inherent semantic hierarchy of HGNNs, resulting in a lack of fidelity to the model's internal decision-making mechanism; on the other hand, feature explanations often rely on complex search or perturbation mechanisms, leading to excessive computational complexity and poor efficiency. To address these issues, we propose HiSE, a lightweight feature-oriented interpretable model for HGNNs. HiSE achieves semantically aware feature explanations through hierarchical semantic modeling: at the semantic level, local surrogate models based on the Least Absolute Shrinkage and Selection Operator (LASSO) are employed to learn sparse feature representations under each semantic view; at the cross-semantic level, the contributions of different semantic views are adaptively characterized via KL divergence to produce a unified explanation. Extensive experiments demonstrate that HiSE outperforms existing methods in terms of fidelity, robustness, and cross-semantic explanation capability, while its lightweight framework incurs low computational overhead, enabling efficient application to large-scale, complex real-world heterogeneous graphs.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
Zebrafish Counting Using Event Stream Data
Apr 18, 2025



Zebrafish share a high degree of homology with human genes and are commonly used as model organism in biomedical research. For medical laboratories, counting zebrafish is a daily task. Due to the tiny size of zebrafish, manual visual counting is challenging. Existing counting methods are either not applicable to small fishes or have too many limitations. The paper proposed a zebrafish counting algorithm based on the event stream data. Firstly, an event camera is applied for data acquisition. Secondly, camera calibration and image fusion were preformed successively. Then, the trajectory information was used to improve the counting accuracy. Finally, the counting results were averaged over an empirical of period and rounded up to get the final results. To evaluate the accuracy of the algorithm, 20 zebrafish were put in a four-liter breeding tank. Among 100 counting trials, the average accuracy reached 97.95%. As compared with traditional algorithms, the proposed one offers a simpler implementation and achieves higher accuracy.
AnomalyHybrid: A Domain-agnostic Generative Framework for General Anomaly Detection
Apr 06, 2025Anomaly generation is an effective way to mitigate data scarcity for anomaly detection task. Most existing works shine at industrial anomaly generation with multiple specialists or large generative models, rarely generalizing to anomalies in other applications. In this paper, we present AnomalyHybrid, a domain-agnostic framework designed to generate authentic and diverse anomalies simply by combining the reference and target images. AnomalyHybrid is a Generative Adversarial Network(GAN)-based framework having two decoders that integrate the appearance of reference image into the depth and edge structures of target image respectively. With the help of depth decoders, AnomalyHybrid achieves authentic generation especially for the anomalies with depth values changing, such a s protrusion and dent. More, it relaxes the fine granularity structural control of the edge decoder and brings more diversity. Without using annotations, AnomalyHybrid is easily trained with sets of color, depth and edge of same images having different augmentations. Extensive experiments carried on HeliconiusButterfly, MVTecAD and MVTec3D datasets demonstrate that AnomalyHybrid surpasses the GAN-based state-of-the-art on anomaly generation and its downstream anomaly classification, detection and segmentation tasks. On MVTecAD dataset, AnomalyHybrid achieves 2.06/0.32 IS/LPIPS for anomaly generation, 52.6 Acc for anomaly classification with ResNet34, 97.3/72.9 AP for image/pixel-level anomaly detection with a simple UNet.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
AnomalyFactory: Regard Anomaly Generation as Unsupervised Anomaly Localization
Aug 18, 2024Recent advances in anomaly generation approaches alleviate the effect of data insufficiency on task of anomaly localization. While effective, most of them learn multiple large generative models on different datasets and cumbersome anomaly prediction models for different classes. To address the limitations, we propose a novel scalable framework, named AnomalyFactory, that unifies unsupervised anomaly generation and localization with same network architecture. It starts with a BootGenerator that combines structure of a target edge map and appearance of a reference color image with the guidance of a learned heatmap. Then, it proceeds with a FlareGenerator that receives supervision signals from the BootGenerator and reforms the heatmap to indicate anomaly locations in the generated image. Finally, it easily transforms the same network architecture to a BlazeDetector that localizes anomaly pixels with the learned heatmap by converting the anomaly images generated by the FlareGenerator to normal images. By manipulating the target edge maps and combining them with various reference images, AnomalyFactory generates authentic and diversity samples cross domains. Comprehensive experiments carried on 5 datasets, including MVTecAD, VisA, MVTecLOCO, MADSim and RealIAD, demonstrate that our approach is superior to competitors in generation capability and scalability.
GRUtopia: Dream General Robots in a City at Scale
Jul 15, 2024Recent works have been exploring the scaling laws in the field of Embodied AI. Given the prohibitive costs of collecting real-world data, we believe the Simulation-to-Real (Sim2Real) paradigm is a crucial step for scaling the learning of embodied models. This paper introduces project GRUtopia, the first simulated interactive 3D society designed for various robots. It features several advancements: (a) The scene dataset, GRScenes, includes 100k interactive, finely annotated scenes, which can be freely combined into city-scale environments. In contrast to previous works mainly focusing on home, GRScenes covers 89 diverse scene categories, bridging the gap of service-oriented environments where general robots would be initially deployed. (b) GRResidents, a Large Language Model (LLM) driven Non-Player Character (NPC) system that is responsible for social interaction, task generation, and task assignment, thus simulating social scenarios for embodied AI applications. (c) The benchmark, GRBench, supports various robots but focuses on legged robots as primary agents and poses moderately challenging tasks involving Object Loco-Navigation, Social Loco-Navigation, and Loco-Manipulation. We hope that this work can alleviate the scarcity of high-quality data in this field and provide a more comprehensive assessment of Embodied AI research. The project is available at https://github.com/OpenRobotLab/GRUtopia.
LogicAL: Towards logical anomaly synthesis for unsupervised anomaly localization
May 11, 2024Anomaly localization is a practical technology for improving industrial production line efficiency. Due to anomalies are manifold and hard to be collected, existing unsupervised researches are usually equipped with anomaly synthesis methods. However, most of them are biased towards structural defects synthesis while ignoring the underlying logical constraints. To fill the gap and boost anomaly localization performance, we propose an edge manipulation based anomaly synthesis framework, named LogicAL, that produces photo-realistic both logical and structural anomalies. We introduce a logical anomaly generation strategy that is adept at breaking logical constraints and a structural anomaly generation strategy that complements to the structural defects synthesis. We further improve the anomaly localization performance by introducing edge reconstruction into the network structure. Extensive experiments on the challenge MVTecLOCO, MVTecAD, VisA and MADsim datasets verify the advantage of proposed LogicAL on both logical and structural anomaly localization.
A Dataset of Open-Domain Question Answering with Multiple-Span Answers
Feb 15, 2024
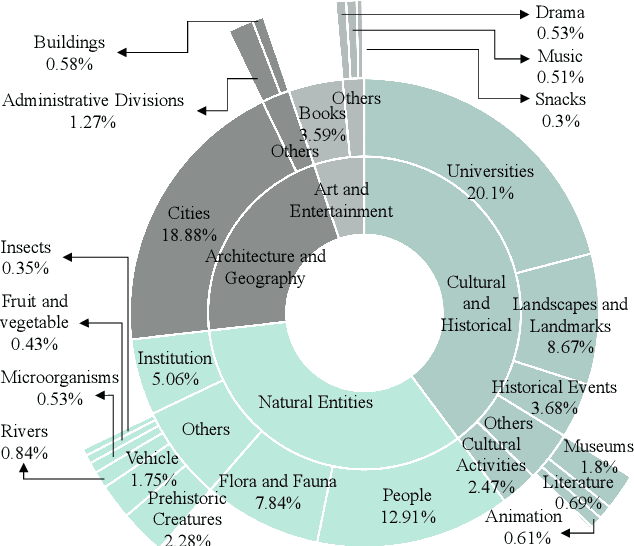


Multi-span answer extraction, also known as the task of multi-span question answering (MSQA), is critical for real-world applications, as it requires extracting multiple pieces of information from a text to answer complex questions. Despite the active studies and rapid progress in English MSQA research, there is a notable lack of publicly available MSQA benchmark in Chinese. Previous efforts for constructing MSQA datasets predominantly emphasized entity-centric contextualization, resulting in a bias towards collecting factoid questions and potentially overlooking questions requiring more detailed descriptive responses. To overcome these limitations, we present CLEAN, a comprehensive Chinese multi-span question answering dataset that involves a wide range of open-domain subjects with a substantial number of instances requiring descriptive answers. Additionally, we provide established models from relevant literature as baselines for CLEAN. Experimental results and analysis show the characteristics and challenge of the newly proposed CLEAN dataset for the community. Our dataset, CLEAN, will be publicly released at zhiyiluo.site/misc/clean_v1.0_ sample.json.