 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAltDiffusion: A Multilingual Text-to-Image Diffusion Model
Aug 23, 2023Large Text-to-Image(T2I) diffusion models have shown a remarkable capability to produce photorealistic and diverse images based on text inputs. However, existing works only support limited language input, e.g., English, Chinese, and Japanese, leaving users beyond these languages underserved and blocking the global expansion of T2I models. Therefore, this paper presents AltDiffusion, a novel multilingual T2I diffusion model that supports eighteen different languages. Specifically, we first train a multilingual text encoder based on the knowledge distillation. Then we plug it into a pretrained English-only diffusion model and train the model with a two-stage schema to enhance the multilingual capability, including concept alignment and quality improvement stage on a large-scale multilingual dataset. Furthermore, we introduce a new benchmark, which includes Multilingual-General-18(MG-18) and Multilingual-Cultural-18(MC-18) datasets, to evaluate the capabilities of T2I diffusion models for generating high-quality images and capturing culture-specific concepts in different languages. Experimental results on both MG-18 and MC-18 demonstrate that AltDiffusion outperforms current state-of-the-art T2I models, e.g., Stable Diffusion in multilingual understanding, especially with respect to culture-specific concepts, while still having comparable capability for generating high-quality images. All source code and checkpoints could be found in https://github.com/superhero-7/AltDiffuson.
UniTabE: Pretraining a Unified Tabular Encoder for Heterogeneous Tabular Data
Jul 18, 2023



Recent advancements in Natural Language Processing (NLP) have witnessed the groundbreaking impact of pretrained models, yielding impressive outcomes across various tasks. This study seeks to extend the power of pretraining methodologies to tabular data, a domain traditionally overlooked, yet inherently challenging due to the plethora of table schemas intrinsic to different tasks. The primary research questions underpinning this work revolve around the adaptation to heterogeneous table structures, the establishment of a universal pretraining protocol for tabular data, the generalizability and transferability of learned knowledge across tasks, the adaptation to diverse downstream applications, and the incorporation of incremental columns over time. In response to these challenges, we introduce UniTabE, a pioneering method designed to process tables in a uniform manner, devoid of constraints imposed by specific table structures. UniTabE's core concept relies on representing each basic table element with a module, termed TabUnit. This is subsequently followed by a Transformer encoder to refine the representation. Moreover, our model is designed to facilitate pretraining and finetuning through the utilization of free-form prompts. In order to implement the pretraining phase, we curated an expansive tabular dataset comprising approximately 13 billion samples, meticulously gathered from the Kaggle platform. Rigorous experimental testing and analyses were performed under a myriad of scenarios to validate the effectiveness of our methodology. The experimental results demonstrate UniTabE's superior performance against several baseline models across a multitude of benchmark datasets. This, therefore, underscores UniTabE's potential to significantly enhance the semantic representation of tabular data, thereby marking a significant stride in the field of tabular data analysis.
EVA-CLIP: Improved Training Techniques for CLIP at Scale
Mar 27, 2023



Contrastive language-image pre-training, CLIP for short, has gained increasing attention for its potential in various scenarios. In this paper, we propose EVA-CLIP, a series of models that significantly improve the efficiency and effectiveness of CLIP training. Our approach incorporates new techniques for representation learning, optimization, and augmentation, enabling EVA-CLIP to achieve superior performance compared to previous CLIP models with the same number of parameters but significantly smaller training costs. Notably, our largest 5.0B-parameter EVA-02-CLIP-E/14+ with only 9 billion seen samples achieves 82.0 zero-shot top-1 accuracy on ImageNet-1K val. A smaller EVA-02-CLIP-L/14+ with only 430 million parameters and 6 billion seen samples achieves 80.4 zero-shot top-1 accuracy on ImageNet-1K val. To facilitate open access and open research, we release the complete suite of EVA-CLIP to the community at https://github.com/baaivision/EVA/tree/master/EVA-CLIP.
AltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities
Nov 21, 2022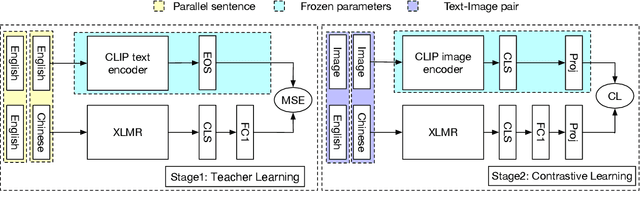
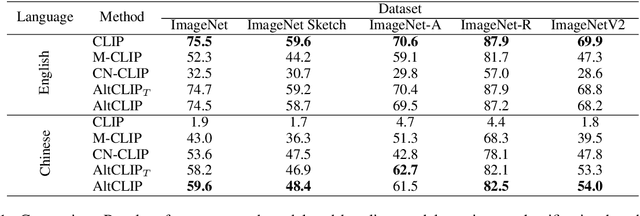
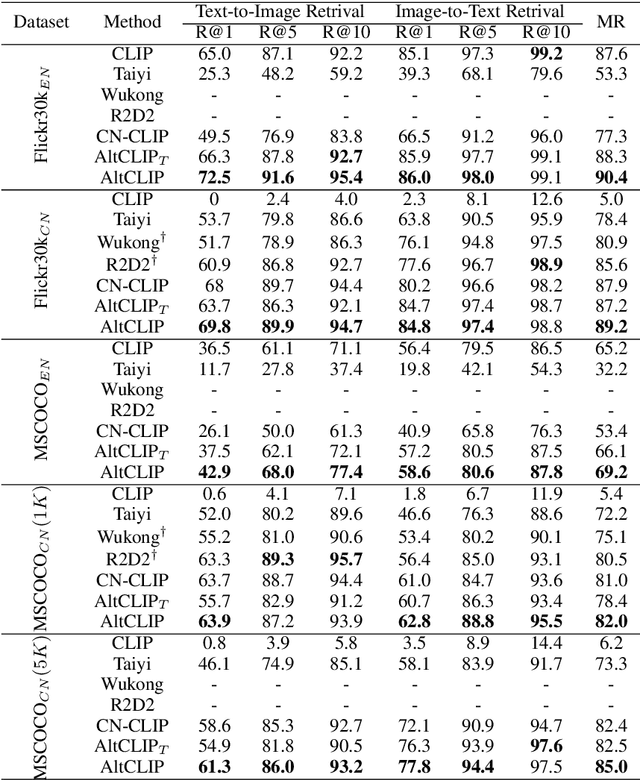
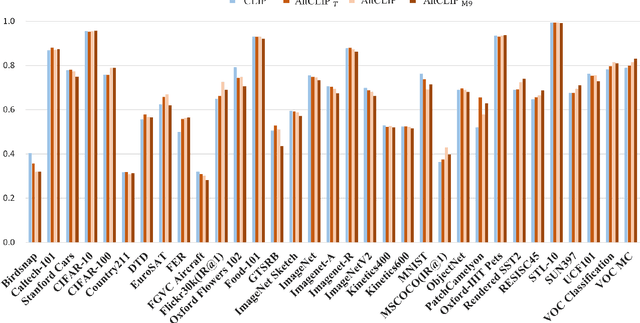
In this work, we present a conceptually simple and effective method to train a strong bilingual/multilingual multimodal representation model. Starting from the pre-trained multimodal representation model CLIP released by OpenAI, we altered its text encoder with a pre-trained multilingual text encoder XLM-R, and aligned both languages and image representations by a two-stage training schema consisting of teacher learning and contrastive learning. We validate our method through evaluations of a wide range of tasks. We set new state-of-the-art performances on a bunch of tasks including ImageNet-CN, Flicker30k-CN, COCO-CN and XTD. Further, we obtain very close performances with CLIP on almost all tasks, suggesting that one can simply alter the text encoder in CLIP for extended capabilities such as multilingual understanding. Our models and code are available at https://github.com/FlagAI-Open/FlagAI.
EVA: Exploring the Limits of Masked Visual Representation Learning at Scale
Nov 14, 2022



We launch EVA, a vision-centric foundation model to explore the limits of visual representation at scale using only publicly accessible data. EVA is a vanilla ViT pre-trained to reconstruct the masked out image-text aligned vision features conditioned on visible image patches. Via this pretext task, we can efficiently scale up EVA to one billion parameters, and sets new records on a broad range of representative vision downstream tasks, such as image recognition, video action recognition, object detection, instance segmentation and semantic segmentation without heavy supervised training. Moreover, we observe quantitative changes in scaling EVA result in qualitative changes in transfer learning performance that are not present in other models. For instance, EVA takes a great leap in the challenging large vocabulary instance segmentation task: our model achieves almost the same state-of-the-art performance on LVISv1.0 dataset with over a thousand categories and COCO dataset with only eighty categories. Beyond a pure vision encoder, EVA can also serve as a vision-centric, multi-modal pivot to connect images and text. We find initializing the vision tower of a giant CLIP from EVA can greatly stabilize the training and outperform the training from scratch counterpart with much fewer samples and less compute, providing a new direction for scaling up and accelerating the costly training of multi-modal foundation models. To facilitate future research, we will release all the code and models at \url{https://github.com/baaivision/EVA}.
PTab: Using the Pre-trained Language Model for Modeling Tabular Data
Sep 15, 2022



Tabular data is the foundation of the information age and has been extensively studied. Recent studies show that neural-based models are effective in learning contextual representation for tabular data. The learning of an effective contextual representation requires meaningful features and a large amount of data. However, current methods often fail to properly learn a contextual representation from the features without semantic information. In addition, it's intractable to enlarge the training set through mixed tabular datasets due to the difference between datasets. To address these problems, we propose a novel framework PTab, using the Pre-trained language model to model Tabular data. PTab learns a contextual representation of tabular data through a three-stage processing: Modality Transformation(MT), Masked-Language Fine-tuning(MF), and Classification Fine-tuning(CF). We initialize our model with a pre-trained Model (PTM) which contains semantic information learned from the large-scale language data. Consequently, contextual representation can be learned effectively during the fine-tuning stages. In addition, we can naturally mix the textualized tabular data to enlarge the training set to further improve representation learning. We evaluate PTab on eight popular tabular classification datasets. Experimental results show that our method has achieved a better average AUC score in supervised settings compared to the state-of-the-art baselines(e.g. XGBoost), and outperforms counterpart methods under semi-supervised settings. We present visualization results that show PTab has well instance-based interpretability.
Ultron: An Ultimate Retriever on Corpus with a Model-based Indexer
Aug 19, 2022



Document retrieval has been extensively studied within the index-retrieve framework for decades, which has withstood the test of time. Unfortunately, such a pipelined framework limits the optimization of the final retrieval quality, because indexing and retrieving are separated stages that can not be jointly optimized in an end-to-end manner. In order to unify these two stages, we explore a model-based indexer for document retrieval. Concretely, we propose Ultron, which encodes the knowledge of all documents into the model and aims to directly retrieve relevant documents end-to-end. For the model-based indexer, how to represent docids and how to train the model are two main issues to be explored. Existing solutions suffer from semantically deficient docids and limited supervised data. To tackle these two problems, first, we devise two types of docids that are richer in semantics and easier for model inference. In addition, we propose a three-stage training workflow to capture more knowledge contained in the corpus and associations between queries and docids. Experiments on two public datasets demonstrate the superiority of Ultron over advanced baselines for document retrieval.
DynamicRetriever: A Pre-training Model-based IR System with Neither Sparse nor Dense Index
Mar 01, 2022



Web search provides a promising way for people to obtain information and has been extensively studied. With the surgence of deep learning and large-scale pre-training techniques, various neural information retrieval models are proposed and they have demonstrated the power for improving search (especially, the ranking) quality. All these existing search methods follow a common paradigm, i.e. index-retrieve-rerank, where they first build an index of all documents based on document terms (i.e., sparse inverted index) or representation vectors (i.e., dense vector index), then retrieve and rerank retrieved documents based on similarity between the query and documents via ranking models. In this paper, we explore a new paradigm of information retrieval with neither sparse nor dense index but only a model. Specifically, we propose a pre-training model-based IR system called DynamicRetriever. As for this system, the training stage embeds the token-level and document-level information (especially, document identifiers) of the corpus into the model parameters, then the inference stage directly generates document identifiers for a given query. Compared with existing search methods, the model-based IR system has two advantages: i) it parameterizes the traditional static index with a pre-training model, which converts the document semantic mapping into a dynamic and updatable process; ii) with separate document identifiers, it captures both the term-level and document-level information for each document. Extensive experiments conducted on the public search benchmark MS MARCO verify the effectiveness and potential of our proposed new paradigm for information retrieval.
Dynaboard: An Evaluation-As-A-Service Platform for Holistic Next-Generation Benchmarking
May 21, 2021



We introduce Dynaboard, an evaluation-as-a-service framework for hosting benchmarks and conducting holistic model comparison, integrated with the Dynabench platform. Our platform evaluates NLP models directly instead of relying on self-reported metrics or predictions on a single dataset. Under this paradigm, models are submitted to be evaluated in the cloud, circumventing the issues of reproducibility, accessibility, and backwards compatibility that often hinder benchmarking in NLP. This allows users to interact with uploaded models in real time to assess their quality, and permits the collection of additional metrics such as memory use, throughput, and robustness, which -- despite their importance to practitioners -- have traditionally been absent from leaderboards. On each task, models are ranked according to the Dynascore, a novel utility-based aggregation of these statistics, which users can customize to better reflect their preferences, placing more/less weight on a particular axis of evaluation or dataset. As state-of-the-art NLP models push the limits of traditional benchmarks, Dynaboard offers a standardized solution for a more diverse and comprehensive evaluation of model quality.
Multilingual Autoregressive Entity Linking
Mar 23, 2021



We present mGENRE, a sequence-to-sequence system for the Multilingual Entity Linking (MEL) problem -- the task of resolving language-specific mentions to a multilingual Knowledge Base (KB). For a mention in a given language, mGENRE predicts the name of the target entity left-to-right, token-by-token in an autoregressive fashion. The autoregressive formulation allows us to effectively cross-encode mention string and entity names to capture more interactions than the standard dot product between mention and entity vectors. It also enables fast search within a large KB even for mentions that do not appear in mention tables and with no need for large-scale vector indices. While prior MEL works use a single representation for each entity, we match against entity names of as many languages as possible, which allows exploiting language connections between source input and target name. Moreover, in a zero-shot setting on languages with no training data at all, mGENRE treats the target language as a latent variable that is marginalized at prediction time. This leads to over 50% improvements in average accuracy. We show the efficacy of our approach through extensive evaluation including experiments on three popular MEL benchmarks where mGENRE establishes new state-of-the-art results. Code and pre-trained models at https://github.com/facebookresearch/GENRE.