 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAltCLIP: Altering the Language Encoder in CLIP for Extended Language Capabilities
Paper and Code
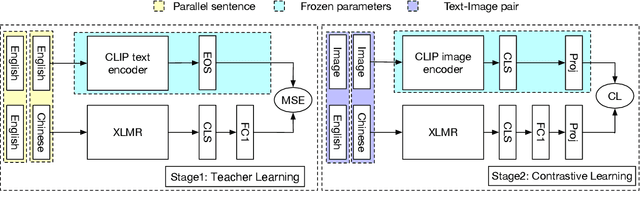
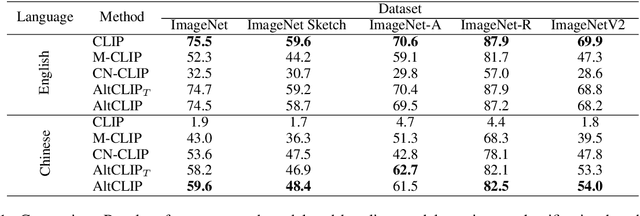
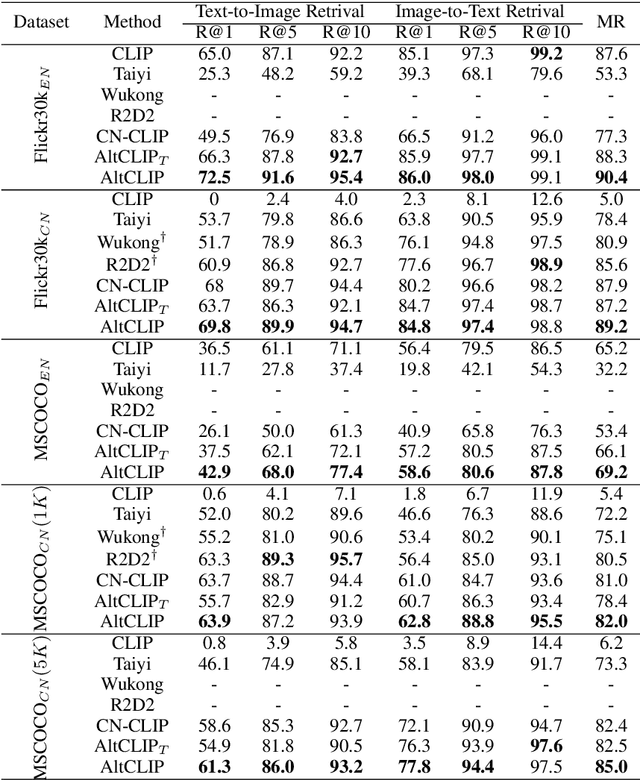
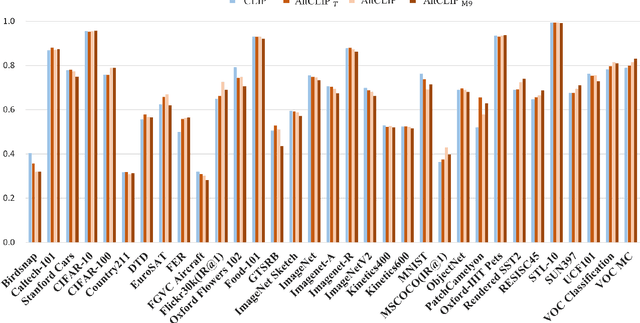
In this work, we present a conceptually simple and effective method to train a strong bilingual/multilingual multimodal representation model. Starting from the pre-trained multimodal representation model CLIP released by OpenAI, we altered its text encoder with a pre-trained multilingual text encoder XLM-R, and aligned both languages and image representations by a two-stage training schema consisting of teacher learning and contrastive learning. We validate our method through evaluations of a wide range of tasks. We set new state-of-the-art performances on a bunch of tasks including ImageNet-CN, Flicker30k-CN, COCO-CN and XTD. Further, we obtain very close performances with CLIP on almost all tasks, suggesting that one can simply alter the text encoder in CLIP for extended capabilities such as multilingual understanding. Our models and code are available at https://github.com/FlagAI-Open/FlagAI.