 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState Rank Dynamics in Linear Attention LLMs
Feb 02, 2026Linear Attention Large Language Models (LLMs) offer a compelling recurrent formulation that compresses context into a fixed-size state matrix, enabling constant-time inference. However, the internal dynamics of this compressed state remain largely opaque. In this work, we present a comprehensive study on the runtime state dynamics of state-of-the-art Linear Attention models. We uncover a fundamental phenomenon termed State Rank Stratification, characterized by a distinct spectral bifurcation among linear attention heads: while one group maintains an effective rank oscillating near zero, the other exhibits rapid growth that converges to an upper bound. Extensive experiments across diverse inference contexts reveal that these dynamics remain strikingly consistent, indicating that the identity of a head,whether low-rank or high-rank,is an intrinsic structural property acquired during pre-training, rather than a transient state dependent on the input data. Furthermore, our diagnostic probes reveal a surprising functional divergence: low-rank heads are indispensable for model reasoning, whereas high-rank heads exhibit significant redundancy. Leveraging this insight, we propose Joint Rank-Norm Pruning, a zero-shot strategy that achieves a 38.9\% reduction in KV-cache overhead while largely maintaining model accuracy.
A Simple DropConnect Approach to Transfer-based Targeted Attack
Apr 24, 2025We study the problem of transfer-based black-box attack, where adversarial samples generated using a single surrogate model are directly applied to target models. Compared with untargeted attacks, existing methods still have lower Attack Success Rates (ASRs) in the targeted setting, i.e., the obtained adversarial examples often overfit the surrogate model but fail to mislead other models. In this paper, we hypothesize that the pixels or features in these adversarial examples collaborate in a highly dependent manner to maximize the success of an adversarial attack on the surrogate model, which we refer to as perturbation co-adaptation. Then, we propose to Mitigate perturbation Co-adaptation by DropConnect (MCD) to enhance transferability, by creating diverse variants of surrogate model at each optimization iteration. We conduct extensive experiments across various CNN- and Transformer-based models to demonstrate the effectiveness of MCD. In the challenging scenario of transferring from a CNN-based model to Transformer-based models, MCD achieves 13% higher average ASRs compared with state-of-the-art baselines. MCD boosts the performance of self-ensemble methods by bringing in more diversification across the variants while reserving sufficient semantic information for each variant. In addition, MCD attains the highest performance gain when scaling the compute of crafting adversarial examples.
Exploring Structured Semantic Priors Underlying Diffusion Score for Test-time Adaptation
Jan 01, 2025
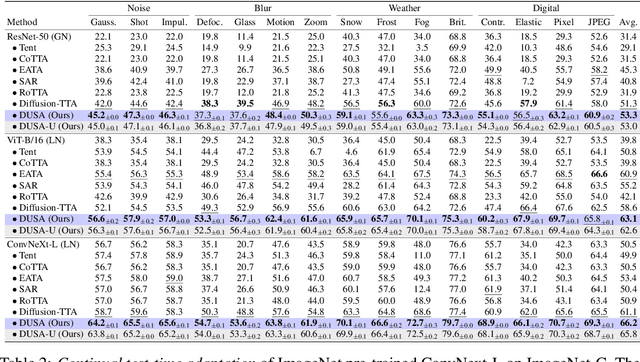


Capitalizing on the complementary advantages of generative and discriminative models has always been a compelling vision in machine learning, backed by a growing body of research. This work discloses the hidden semantic structure within score-based generative models, unveiling their potential as effective discriminative priors. Inspired by our theoretical findings, we propose DUSA to exploit the structured semantic priors underlying diffusion score to facilitate the test-time adaptation of image classifiers or dense predictors. Notably, DUSA extracts knowledge from a single timestep of denoising diffusion, lifting the curse of Monte Carlo-based likelihood estimation over timesteps. We demonstrate the efficacy of our DUSA in adapting a wide variety of competitive pre-trained discriminative models on diverse test-time scenarios. Additionally, a thorough ablation study is conducted to dissect the pivotal elements in DUSA. Code is publicly available at https://github.com/BIT-DA/DUSA.