 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeState Rank Dynamics in Linear Attention LLMs
Feb 02, 2026Linear Attention Large Language Models (LLMs) offer a compelling recurrent formulation that compresses context into a fixed-size state matrix, enabling constant-time inference. However, the internal dynamics of this compressed state remain largely opaque. In this work, we present a comprehensive study on the runtime state dynamics of state-of-the-art Linear Attention models. We uncover a fundamental phenomenon termed State Rank Stratification, characterized by a distinct spectral bifurcation among linear attention heads: while one group maintains an effective rank oscillating near zero, the other exhibits rapid growth that converges to an upper bound. Extensive experiments across diverse inference contexts reveal that these dynamics remain strikingly consistent, indicating that the identity of a head,whether low-rank or high-rank,is an intrinsic structural property acquired during pre-training, rather than a transient state dependent on the input data. Furthermore, our diagnostic probes reveal a surprising functional divergence: low-rank heads are indispensable for model reasoning, whereas high-rank heads exhibit significant redundancy. Leveraging this insight, we propose Joint Rank-Norm Pruning, a zero-shot strategy that achieves a 38.9\% reduction in KV-cache overhead while largely maintaining model accuracy.
How Particle-System Random Batch Methods Enhance Graph Transformer: Memory Efficiency and Parallel Computing Strategy
Nov 08, 2025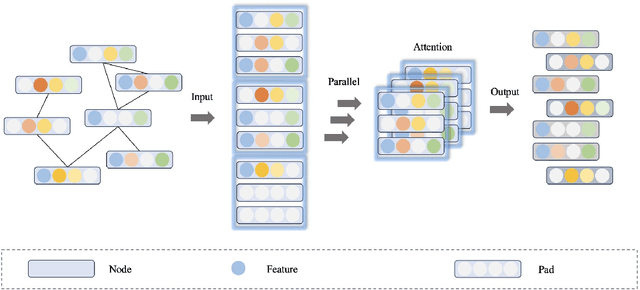


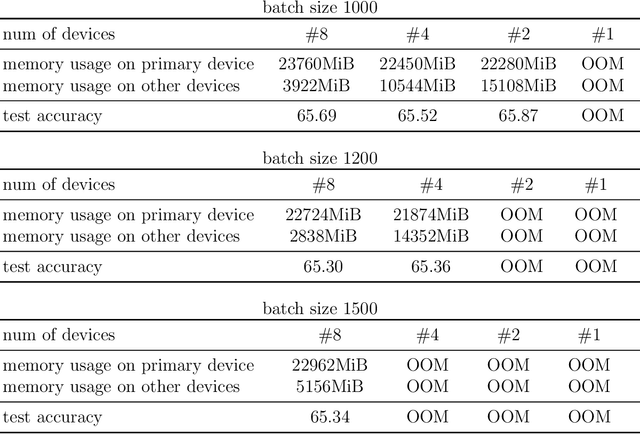
Attention mechanism is a significant part of Transformer models. It helps extract features from embedded vectors by adding global information and its expressivity has been proved to be powerful. Nevertheless, the quadratic complexity restricts its practicability. Although several researches have provided attention mechanism in sparse form, they are lack of theoretical analysis about the expressivity of their mechanism while reducing complexity. In this paper, we put forward Random Batch Attention (RBA), a linear self-attention mechanism, which has theoretical support of the ability to maintain its expressivity. Random Batch Attention has several significant strengths as follows: (1) Random Batch Attention has linear time complexity. Other than this, it can be implemented in parallel on a new dimension, which contributes to much memory saving. (2) Random Batch Attention mechanism can improve most of the existing models by replacing their attention mechanisms, even many previously improved attention mechanisms. (3) Random Batch Attention mechanism has theoretical explanation in convergence, as it comes from Random Batch Methods on computation mathematics. Experiments on large graphs have proved advantages mentioned above. Also, the theoretical modeling of self-attention mechanism is a new tool for future research on attention-mechanism analysis.
Solving excited states for long-range interacting trapped ions with neural networks
Jun 10, 2025The computation of excited states in strongly interacting quantum many-body systems is of fundamental importance. Yet, it is notoriously challenging due to the exponential scaling of the Hilbert space dimension with the system size. Here, we introduce a neural network-based algorithm that can simultaneously output multiple low-lying excited states of a quantum many-body spin system in an accurate and efficient fashion. This algorithm, dubbed the neural quantum excited-state (NQES) algorithm, requires no explicit orthogonalization of the states and is generally applicable to higher dimensions. We demonstrate, through concrete examples including the Haldane-Shastry model with all-to-all interactions, that the NQES algorithm is capable of efficiently computing multiple excited states and their related observable expectations. In addition, we apply the NQES algorithm to two classes of long-range interacting trapped-ion systems in a two-dimensional Wigner crystal. For non-decaying all-to-all interactions with alternating signs, our computed low-lying excited states bear spatial correlation patterns similar to those of the ground states, which closely match recent experimental observations that the quasi-adiabatically prepared state accurately reproduces analytical ground-state correlations. For a system of up to 300 ions with power-law decaying antiferromagnetic interactions, we successfully uncover its gap scaling and correlation features. Our results establish a scalable and efficient algorithm for computing excited states of interacting quantum many-body systems, which holds potential applications ranging from benchmarking quantum devices to photoisomerization.
How Particle System Theory Enhances Hypergraph Message Passing
May 24, 2025Hypergraphs effectively model higher-order relationships in natural phenomena, capturing complex interactions beyond pairwise connections. We introduce a novel hypergraph message passing framework inspired by interacting particle systems, where hyperedges act as fields inducing shared node dynamics. By incorporating attraction, repulsion, and Allen-Cahn forcing terms, particles of varying classes and features achieve class-dependent equilibrium, enabling separability through the particle-driven message passing. We investigate both first-order and second-order particle system equations for modeling these dynamics, which mitigate over-smoothing and heterophily thus can capture complete interactions. The more stable second-order system permits deeper message passing. Furthermore, we enhance deterministic message passing with stochastic element to account for interaction uncertainties. We prove theoretically that our approach mitigates over-smoothing by maintaining a positive lower bound on the hypergraph Dirichlet energy during propagation and thus to enable hypergraph message passing to go deep. Empirically, our models demonstrate competitive performance on diverse real-world hypergraph node classification tasks, excelling on both homophilic and heterophilic datasets.
Information Gain-Guided Causal Intervention for Autonomous Debiasing Large Language Models
Apr 17, 2025Despite significant progress, recent studies indicate that current large language models (LLMs) may still capture dataset biases and utilize them during inference, leading to the poor generalizability of LLMs. However, due to the diversity of dataset biases and the insufficient nature of bias suppression based on in-context learning, the effectiveness of previous prior knowledge-based debiasing methods and in-context learning based automatic debiasing methods is limited. To address these challenges, we explore the combination of causal mechanisms with information theory and propose an information gain-guided causal intervention debiasing (IGCIDB) framework. This framework first utilizes an information gain-guided causal intervention method to automatically and autonomously balance the distribution of instruction-tuning dataset. Subsequently, it employs a standard supervised fine-tuning process to train LLMs on the debiased dataset. Experimental results show that IGCIDB can effectively debias LLM to improve its generalizability across different tasks.
Causal-Guided Active Learning for Debiasing Large Language Models
Aug 23, 2024Although achieving promising performance, recent analyses show that current generative large language models (LLMs) may still capture dataset biases and utilize them for generation, leading to poor generalizability and harmfulness of LLMs. However, due to the diversity of dataset biases and the over-optimization problem, previous prior-knowledge-based debiasing methods and fine-tuning-based debiasing methods may not be suitable for current LLMs. To address this issue, we explore combining active learning with the causal mechanisms and propose a casual-guided active learning (CAL) framework, which utilizes LLMs itself to automatically and autonomously identify informative biased samples and induce the bias patterns. Then a cost-effective and efficient in-context learning based method is employed to prevent LLMs from utilizing dataset biases during generation. Experimental results show that CAL can effectively recognize typical biased instances and induce various bias patterns for debiasing LLMs.
Entropy Neural Estimation for Graph Contrastive Learning
Jul 26, 2023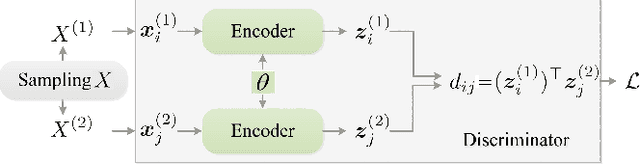
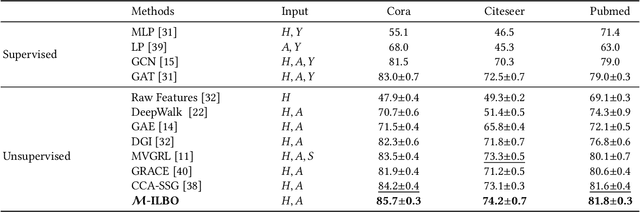
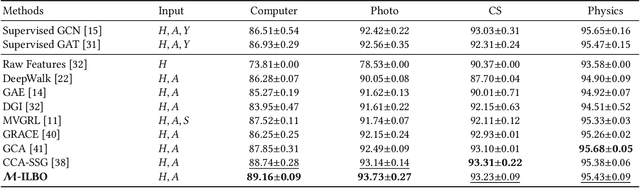
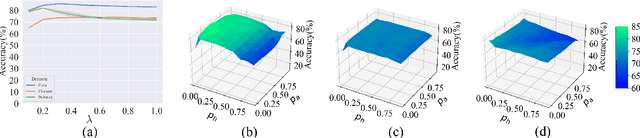
Contrastive learning on graphs aims at extracting distinguishable high-level representations of nodes. In this paper, we theoretically illustrate that the entropy of a dataset can be approximated by maximizing the lower bound of the mutual information across different views of a graph, \ie, entropy is estimated by a neural network. Based on this finding, we propose a simple yet effective subset sampling strategy to contrast pairwise representations between views of a dataset. In particular, we randomly sample nodes and edges from a given graph to build the input subset for a view. Two views are fed into a parameter-shared Siamese network to extract the high-dimensional embeddings and estimate the information entropy of the entire graph. For the learning process, we propose to optimize the network using two objectives, simultaneously. Concretely, the input of the contrastive loss function consists of positive and negative pairs. Our selection strategy of pairs is different from previous works and we present a novel strategy to enhance the representation ability of the graph encoder by selecting nodes based on cross-view similarities. We enrich the diversity of the positive and negative pairs by selecting highly similar samples and totally different data with the guidance of cross-view similarity scores, respectively. We also introduce a cross-view consistency constraint on the representations generated from the different views. This objective guarantees the learned representations are consistent across views from the perspective of the entire graph. We conduct extensive experiments on seven graph benchmarks, and the proposed approach achieves competitive performance compared to the current state-of-the-art methods. The source code will be publicly released once this paper is accepted.
* ACM MM 2023 accepted
Stationary Diffusion State Neural Estimation for Multiview Clustering
Dec 02, 2021



Although many graph-based clustering methods attempt to model the stationary diffusion state in their objectives, their performance limits to using a predefined graph. We argue that the estimation of the stationary diffusion state can be achieved by gradient descent over neural networks. We specifically design the Stationary Diffusion State Neural Estimation (SDSNE) to exploit multiview structural graph information for co-supervised learning. We explore how to design a graph neural network specially for unsupervised multiview learning and integrate multiple graphs into a unified consensus graph by a shared self-attentional module. The view-shared self-attentional module utilizes the graph structure to learn a view-consistent global graph. Meanwhile, instead of using auto-encoder in most unsupervised learning graph neural networks, SDSNE uses a co-supervised strategy with structure information to supervise the model learning. The co-supervised strategy as the loss function guides SDSNE in achieving the stationary state. With the help of the loss and the self-attentional module, we learn to obtain a graph in which nodes in each connected component fully connect by the same weight. Experiments on several multiview datasets demonstrate effectiveness of SDSNE in terms of six clustering evaluation metrics.
* AAAI 2022
A Comprehensive Study on Learning-Based PE Malware Family Classification Methods
Oct 29, 2021
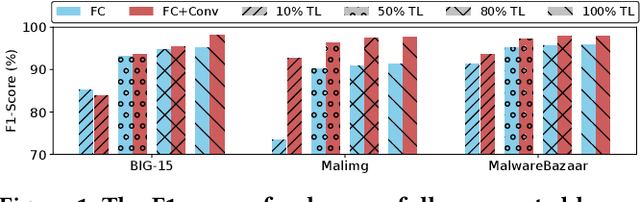
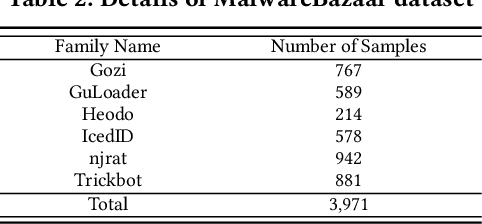
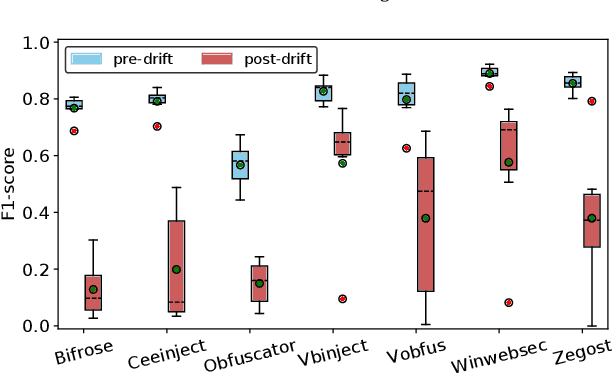
Driven by the high profit, Portable Executable (PE) malware has been consistently evolving in terms of both volume and sophistication. PE malware family classification has gained great attention and a large number of approaches have been proposed. With the rapid development of machine learning techniques and the exciting results they achieved on various tasks, machine learning algorithms have also gained popularity in the PE malware family classification task. Three mainstream approaches that use learning based algorithms, as categorized by the input format the methods take, are image-based, binary-based and disassembly-based approaches. Although a large number of approaches are published, there is no consistent comparisons on those approaches, especially from the practical industry adoption perspective. Moreover, there is no comparison in the scenario of concept drift, which is a fact for the malware classification task due to the fast evolving nature of malware. In this work, we conduct a thorough empirical study on learning-based PE malware classification approaches on 4 different datasets and consistent experiment settings. Based on the experiment results and an interview with our industry partners, we find that (1) there is no individual class of methods that significantly outperforms the others; (2) All classes of methods show performance degradation on concept drift (by an average F1-score of 32.23%); and (3) the prediction time and high memory consumption hinder existing approaches from being adopted for industry usage.
An improved helmet detection method for YOLOv3 on an unbalanced dataset
Nov 09, 2020
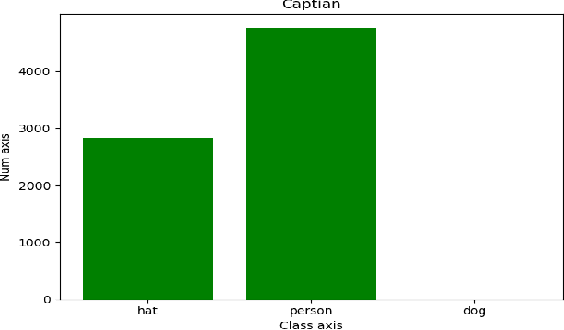
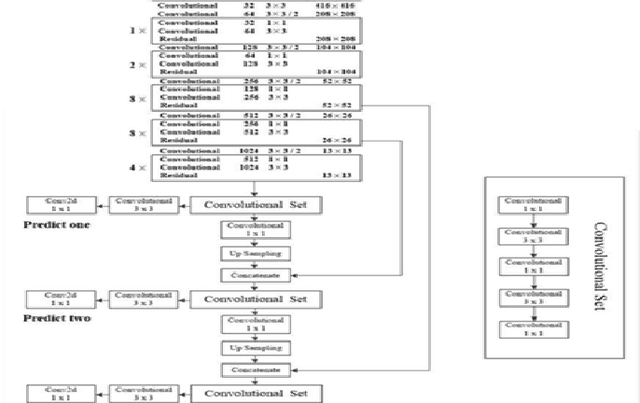

The YOLOv3 target detection algorithm is widely used in industry due to its high speed and high accuracy, but it has some limitations, such as the accuracy degradation of unbalanced datasets. The YOLOv3 target detection algorithm is based on a Gaussian fuzzy data augmentation approach to pre-process the data set and improve the YOLOv3 target detection algorithm. Through the efficient pre-processing, the confidence level of YOLOv3 is generally improved by 0.01-0.02 without changing the recognition speed of YOLOv3, and the processed images also perform better in image localization due to effective feature fusion, which is more in line with the requirement of recognition speed and accuracy in production.