 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Study on Learning-Based PE Malware Family Classification Methods
Paper and Code

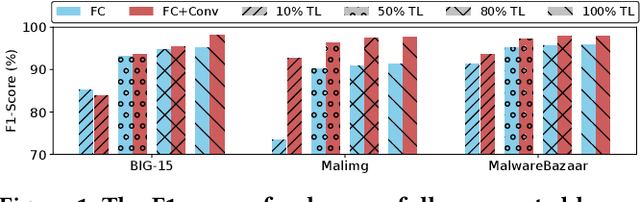
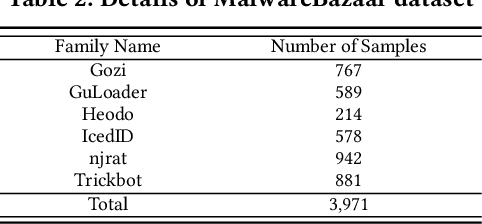
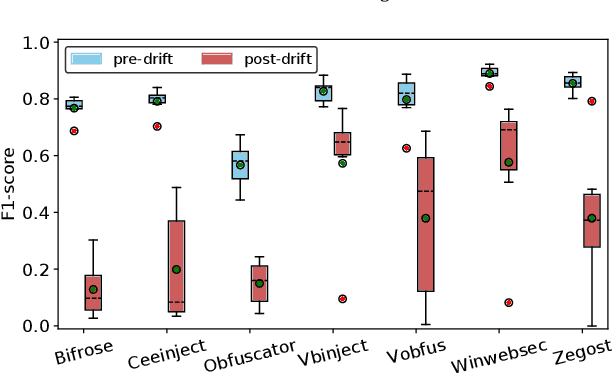
Driven by the high profit, Portable Executable (PE) malware has been consistently evolving in terms of both volume and sophistication. PE malware family classification has gained great attention and a large number of approaches have been proposed. With the rapid development of machine learning techniques and the exciting results they achieved on various tasks, machine learning algorithms have also gained popularity in the PE malware family classification task. Three mainstream approaches that use learning based algorithms, as categorized by the input format the methods take, are image-based, binary-based and disassembly-based approaches. Although a large number of approaches are published, there is no consistent comparisons on those approaches, especially from the practical industry adoption perspective. Moreover, there is no comparison in the scenario of concept drift, which is a fact for the malware classification task due to the fast evolving nature of malware. In this work, we conduct a thorough empirical study on learning-based PE malware classification approaches on 4 different datasets and consistent experiment settings. Based on the experiment results and an interview with our industry partners, we find that (1) there is no individual class of methods that significantly outperforms the others; (2) All classes of methods show performance degradation on concept drift (by an average F1-score of 32.23%); and (3) the prediction time and high memory consumption hinder existing approaches from being adopted for industry usage.