 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
On Accurate and Robust Estimation of 3D and 2D Circular Center: Method and Application to Camera-Lidar Calibration
Nov 10, 2025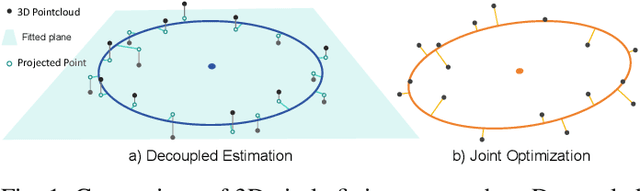

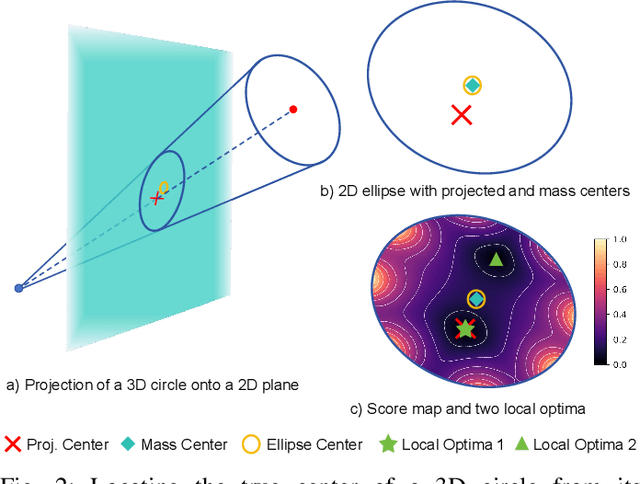
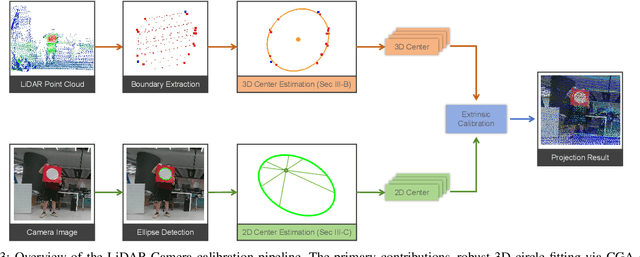
Circular targets are widely used in LiDAR-camera extrinsic calibration due to their geometric consistency and ease of detection. However, achieving accurate 3D-2D circular center correspondence remains challenging. Existing methods often fail due to decoupled 3D fitting and erroneous 2D ellipse-center estimation. To address this, we propose a geometrically principled framework featuring two innovations: (i) a robust 3D circle center estimator based on conformal geometric algebra and RANSAC; and (ii) a chord-length variance minimization method to recover the true 2D projected center, resolving its dual-minima ambiguity via homography validation or a quasi-RANSAC fallback. Evaluated on synthetic and real-world datasets, our framework significantly outperforms state-of-the-art approaches. It reduces extrinsic estimation error and enables robust calibration across diverse sensors and target types, including natural circular objects. Our code will be publicly released for reproducibility.
Evaluating the Generalizability of LLMs in Automated Program Repair
Mar 12, 2025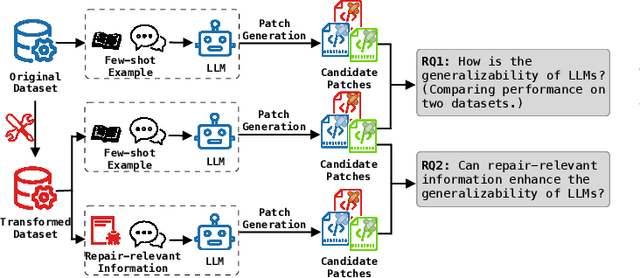
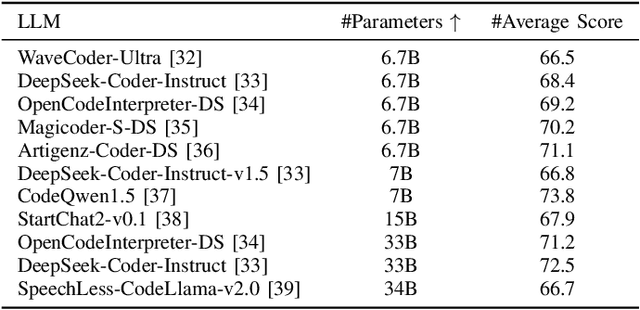
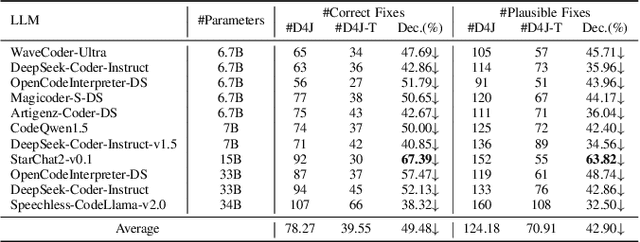

LLM-based automated program repair methods have attracted significant attention for their state-of-the-art performance. However, they were primarily evaluated on a few well known datasets like Defects4J, raising questions about their effectiveness on new datasets. In this study, we evaluate 11 top-performing LLMs on DEFECTS4J-TRANS, a new dataset derived from transforming Defects4J while maintaining the original semantics. Results from experiments on both Defects4J and DEFECTS4J-TRANS show that all studied LLMs have limited generalizability in APR tasks, with the average number of correct and plausible patches decreasing by 49.48% and 42.90%, respectively, on DEFECTS4J-TRANS. Further investigation into incorporating additional repair-relevant information in repair prompts reveals that, although this information significantly enhances the LLMs' capabilities (increasing the number of correct and plausible patches by up to 136.67% and 121.82%, respectively), performance still falls short of their original results. This indicates that prompt engineering alone is insufficient to substantially enhance LLMs' repair capabilities. Based on our study, we also offer several recommendations for future research.
A Large-scale Empirical Study on Improving the Fairness of Deep Learning Models
Jan 08, 2024
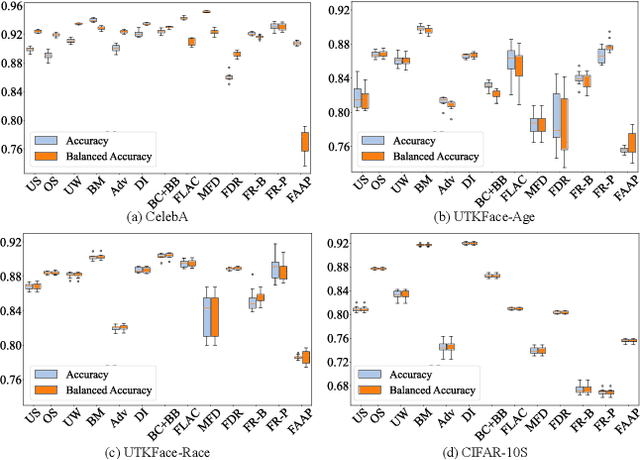

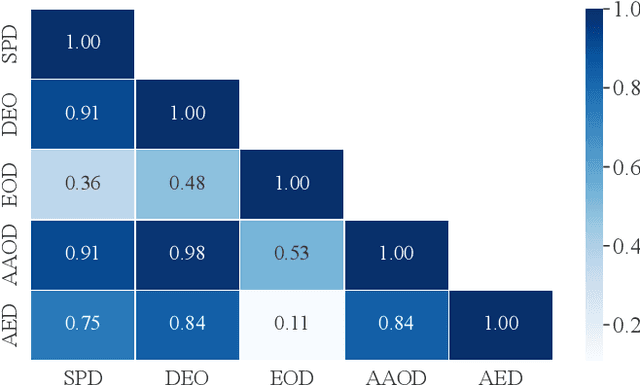
Fairness has been a critical issue that affects the adoption of deep learning models in real practice. To improve model fairness, many existing methods have been proposed and evaluated to be effective in their own contexts. However, there is still no systematic evaluation among them for a comprehensive comparison under the same context, which makes it hard to understand the performance distinction among them, hindering the research progress and practical adoption of them. To fill this gap, this paper endeavours to conduct the first large-scale empirical study to comprehensively compare the performance of existing state-of-the-art fairness improving techniques. Specifically, we target the widely-used application scenario of image classification, and utilized three different datasets and five commonly-used performance metrics to assess in total 13 methods from diverse categories. Our findings reveal substantial variations in the performance of each method across different datasets and sensitive attributes, indicating over-fitting on specific datasets by many existing methods. Furthermore, different fairness evaluation metrics, due to their distinct focuses, yield significantly different assessment results. Overall, we observe that pre-processing methods and in-processing methods outperform post-processing methods, with pre-processing methods exhibiting the best performance. Our empirical study offers comprehensive recommendations for enhancing fairness in deep learning models. We approach the problem from multiple dimensions, aiming to provide a uniform evaluation platform and inspire researchers to explore more effective fairness solutions via a set of implications.
A Comprehensive Study on Learning-Based PE Malware Family Classification Methods
Oct 29, 2021
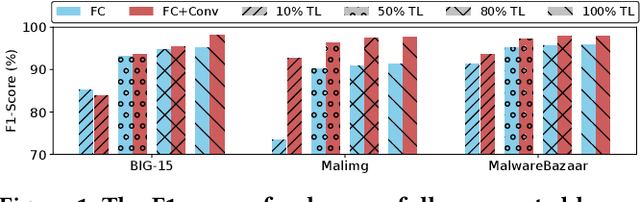
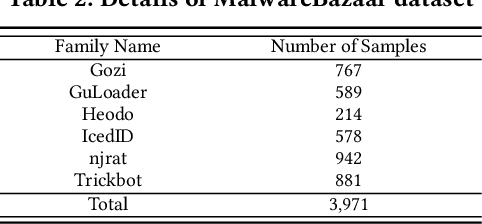
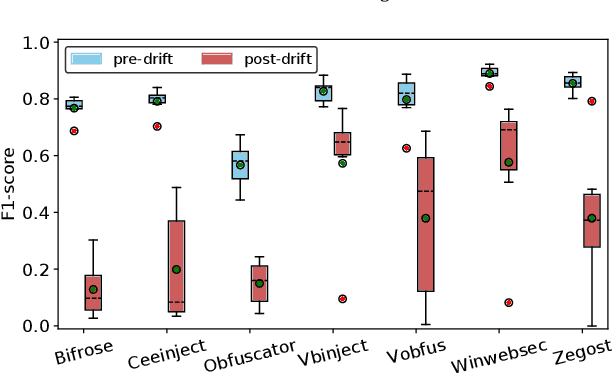
Driven by the high profit, Portable Executable (PE) malware has been consistently evolving in terms of both volume and sophistication. PE malware family classification has gained great attention and a large number of approaches have been proposed. With the rapid development of machine learning techniques and the exciting results they achieved on various tasks, machine learning algorithms have also gained popularity in the PE malware family classification task. Three mainstream approaches that use learning based algorithms, as categorized by the input format the methods take, are image-based, binary-based and disassembly-based approaches. Although a large number of approaches are published, there is no consistent comparisons on those approaches, especially from the practical industry adoption perspective. Moreover, there is no comparison in the scenario of concept drift, which is a fact for the malware classification task due to the fast evolving nature of malware. In this work, we conduct a thorough empirical study on learning-based PE malware classification approaches on 4 different datasets and consistent experiment settings. Based on the experiment results and an interview with our industry partners, we find that (1) there is no individual class of methods that significantly outperforms the others; (2) All classes of methods show performance degradation on concept drift (by an average F1-score of 32.23%); and (3) the prediction time and high memory consumption hinder existing approaches from being adopted for industry usage.