 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Generalizability of LLMs in Automated Program Repair
Paper and Code
Mar 12, 2025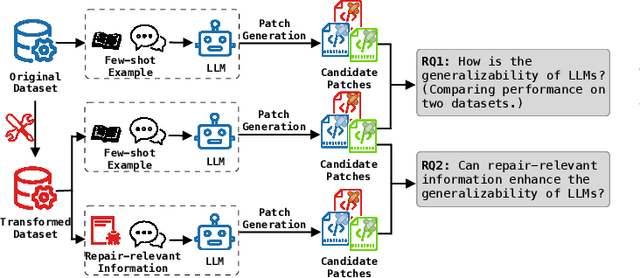
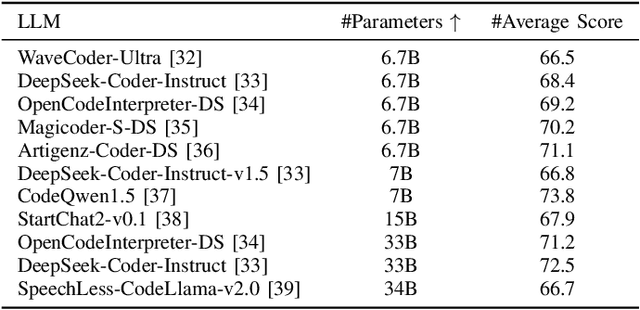
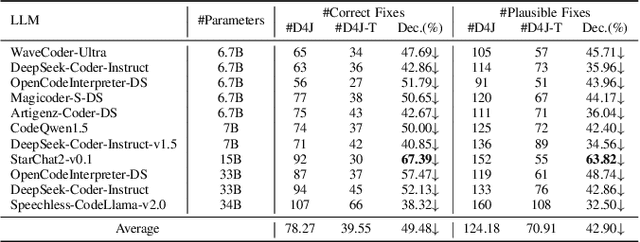

LLM-based automated program repair methods have attracted significant attention for their state-of-the-art performance. However, they were primarily evaluated on a few well known datasets like Defects4J, raising questions about their effectiveness on new datasets. In this study, we evaluate 11 top-performing LLMs on DEFECTS4J-TRANS, a new dataset derived from transforming Defects4J while maintaining the original semantics. Results from experiments on both Defects4J and DEFECTS4J-TRANS show that all studied LLMs have limited generalizability in APR tasks, with the average number of correct and plausible patches decreasing by 49.48% and 42.90%, respectively, on DEFECTS4J-TRANS. Further investigation into incorporating additional repair-relevant information in repair prompts reveals that, although this information significantly enhances the LLMs' capabilities (increasing the number of correct and plausible patches by up to 136.67% and 121.82%, respectively), performance still falls short of their original results. This indicates that prompt engineering alone is insufficient to substantially enhance LLMs' repair capabilities. Based on our study, we also offer several recommendations for future research.