 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Prompting for Few-shot Action Recognition
Nov 22, 2022



Few-shot action recognition in videos is challenging for its lack of supervision and difficulty in generalizing to unseen actions. To address this task, we propose a simple yet effective method, called knowledge prompting, which leverages commonsense knowledge of actions from external resources to prompt a powerful pre-trained vision-language model for few-shot classification. We first collect large-scale language descriptions of actions, defined as text proposals, to build an action knowledge base. The collection of text proposals is done by filling in handcraft sentence templates with external action-related corpus or by extracting action-related phrases from captions of Web instruction videos.Then we feed these text proposals into the pre-trained vision-language model along with video frames to generate matching scores of the proposals to each frame, and the scores can be treated as action semantics with strong generalization. Finally, we design a lightweight temporal modeling network to capture the temporal evolution of action semantics for classification.Extensive experiments on six benchmark datasets demonstrate that our method generally achieves the state-of-the-art performance while reducing the training overhead to 0.001 of existing methods.
Adaptive Recursive Circle Framework for Fine-grained Action Recognition
Jul 25, 2021

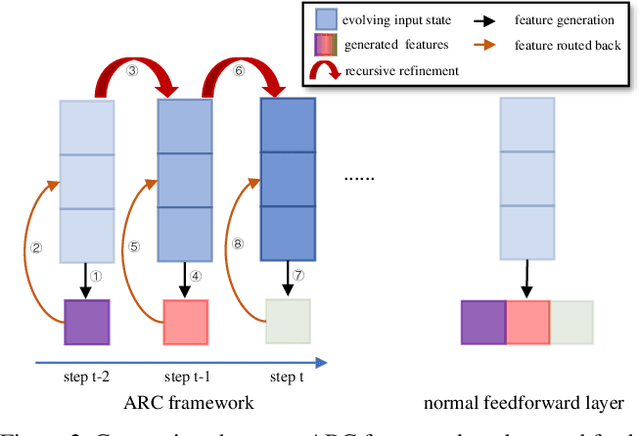
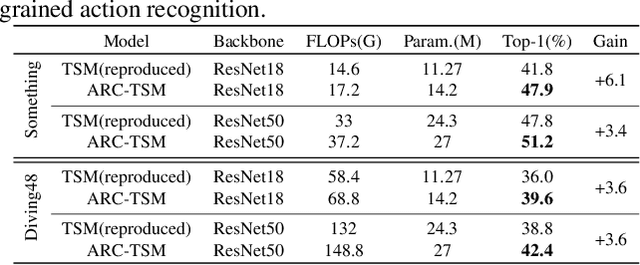
How to model fine-grained spatial-temporal dynamics in videos has been a challenging problem for action recognition. It requires learning deep and rich features with superior distinctiveness for the subtle and abstract motions. Most existing methods generate features of a layer in a pure feedforward manner, where the information moves in one direction from inputs to outputs. And they rely on stacking more layers to obtain more powerful features, bringing extra non-negligible overheads. In this paper, we propose an Adaptive Recursive Circle (ARC) framework, a fine-grained decorator for pure feedforward layers. It inherits the operators and parameters of the original layer but is slightly different in the use of those operators and parameters. Specifically, the input of the layer is treated as an evolving state, and its update is alternated with the feature generation. At each recursive step, the input state is enriched by the previously generated features and the feature generation is made with the newly updated input state. We hope the ARC framework can facilitate fine-grained action recognition by introducing deeply refined features and multi-scale receptive fields at a low cost. Significant improvements over feedforward baselines are observed on several benchmarks. For example, an ARC-equipped TSM-ResNet18 outperforms TSM-ResNet50 with 48% fewer FLOPs and 52% model parameters on Something-Something V1 and Diving48.