 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Vision Foundation Models for High-Performance, Training-Free Open Vocabulary Segmentation
Paper and Code
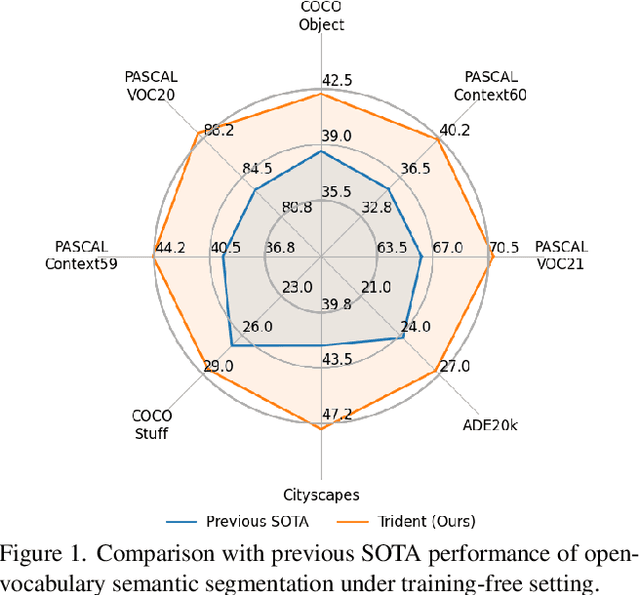


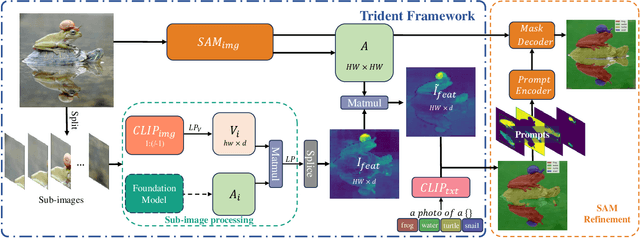
While Contrastive Language-Image Pre-training (CLIP) has advanced open-vocabulary predictions, its performance on semantic segmentation remains suboptimal. This shortfall primarily stems from its spatial-invariant semantic features and constrained resolution. While previous adaptations addressed spatial invariance semantic by modifying the self-attention in CLIP's image encoder, the issue of limited resolution remains unexplored. Different from previous segment-then-splice methods that segment sub-images via a sliding window and splice the results, we introduce a splice-then-segment paradigm that incorporates Segment-Anything Model (SAM) to tackle the resolution issue since SAM excels at extracting fine-grained semantic correlations from high-resolution images. Specifically, we introduce Trident, a training-free framework that first splices features extracted by CLIP and DINO from sub-images, then leverages SAM's encoder to create a correlation matrix for global aggregation, enabling a broadened receptive field for effective segmentation. Besides, we propose a refinement strategy for CLIP's coarse segmentation outputs by transforming them into prompts for SAM, further enhancing the segmentation performance. Trident achieves a significant improvement in the mIoU across eight benchmarks compared with the current SOTA, increasing from 44.4 to 48.6.Code is available at https://github.com/YuHengsss/Trident.