 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Robustness of Visual State Space Models for Image Classification
Mar 16, 2024Visual State Space Model (VMamba) has recently emerged as a promising architecture, exhibiting remarkable performance in various computer vision tasks. However, its robustness has not yet been thoroughly studied. In this paper, we delve into the robustness of this architecture through comprehensive investigations from multiple perspectives. Firstly, we investigate its robustness to adversarial attacks, employing both whole-image and patch-specific adversarial attacks. Results demonstrate superior adversarial robustness compared to Transformer architectures while revealing scalability weaknesses. Secondly, the general robustness of VMamba is assessed against diverse scenarios, including natural adversarial examples, out-of-distribution data, and common corruptions. VMamba exhibits exceptional generalizability with out-of-distribution data but shows scalability weaknesses against natural adversarial examples and common corruptions. Additionally, we explore VMamba's gradients and back-propagation during white-box attacks, uncovering unique vulnerabilities and defensive capabilities of its novel components. Lastly, the sensitivity of VMamba to image structure variations is examined, highlighting vulnerabilities associated with the distribution of disturbance areas and spatial information, with increased susceptibility closer to the image center. Through these comprehensive studies, we contribute to a deeper understanding of VMamba's robustness, providing valuable insights for refining and advancing the capabilities of deep neural networks in computer vision applications.
Stable Diffusion is Unstable
Jun 06, 2023Recently, text-to-image models have been thriving. Despite their powerful generative capacity, our research has uncovered a lack of robustness in this generation process. Specifically, the introduction of small perturbations to the text prompts can result in the blending of primary subjects with other categories or their complete disappearance in the generated images. In this paper, we propose Auto-attack on Text-to-image Models (ATM), a gradient-based approach, to effectively and efficiently generate such perturbations. By learning a Gumbel Softmax distribution, we can make the discrete process of word replacement or extension continuous, thus ensuring the differentiability of the perturbation generation. Once the distribution is learned, ATM can sample multiple attack samples simultaneously. These attack samples can prevent the generative model from generating the desired subjects without compromising image quality. ATM has achieved a 91.1% success rate in short-text attacks and an 81.2% success rate in long-text attacks. Further empirical analysis revealed four attack patterns based on: 1) the variability in generation speed, 2) the similarity of coarse-grained characteristics, 3) the polysemy of words, and 4) the positioning of words.
Two-in-one Knowledge Distillation for Efficient Facial Forgery Detection
Feb 21, 2023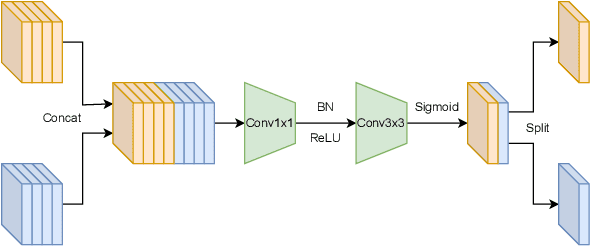

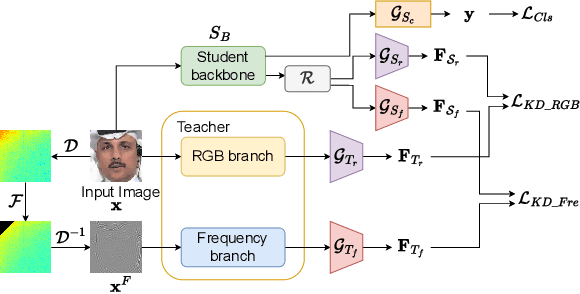
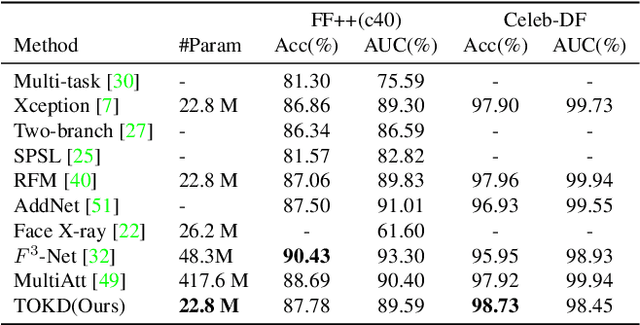
Facial forgery detection is a crucial but extremely challenging topic, with the fast development of forgery techniques making the synthetic artefact highly indistinguishable. Prior works show that by mining both spatial and frequency information the forgery detection performance of deep learning models can be vastly improved. However, leveraging multiple types of information usually requires more than one branch in the neural network, which makes the model heavy and cumbersome. Knowledge distillation, as an important technique for efficient modelling, could be a possible remedy. We find that existing knowledge distillation methods have difficulties distilling a dual-branch model into a single-branch model. More specifically, knowledge distillation on both the spatial and frequency branches has degraded performance than distillation only on the spatial branch. To handle such problem, we propose a novel two-in-one knowledge distillation framework which can smoothly merge the information from a large dual-branch network into a small single-branch network, with the help of different dedicated feature projectors and the gradient homogenization technique. Experimental analysis on two datasets, FaceForensics++ and Celeb-DF, shows that our proposed framework achieves superior performance for facial forgery detection with much fewer parameters.
Anti-Compression Contrastive Facial Forgery Detection
Feb 13, 2023Forgery facial images and videos have increased the concern of digital security. It leads to the significant development of detecting forgery data recently. However, the data, especially the videos published on the Internet, are usually compressed with lossy compression algorithms such as H.264. The compressed data could significantly degrade the performance of recent detection algorithms. The existing anti-compression algorithms focus on enhancing the performance in detecting heavily compressed data but less consider the compression adaption to the data from various compression levels. We believe creating a forgery detection model that can handle the data compressed with unknown levels is important. To enhance the performance for such models, we consider the weak compressed and strong compressed data as two views of the original data and they should have similar representation and relationships with other samples. We propose a novel anti-compression forgery detection framework by maintaining closer relations within data under different compression levels. Specifically, the algorithm measures the pair-wise similarity within data as the relations, and forcing the relations of weak and strong compressed data close to each other, thus improving the discriminate power for detecting strong compressed data. To achieve a better strong compressed data relation guided by the less compressed one, we apply video level contrastive learning for weak compressed data, which forces the model to produce similar representations within the same video and far from the negative samples. The experiment results show that the proposed algorithm could boost performance for strong compressed data while improving the accuracy rate when detecting the clean data.