 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnti-Compression Contrastive Facial Forgery Detection
Feb 13, 2023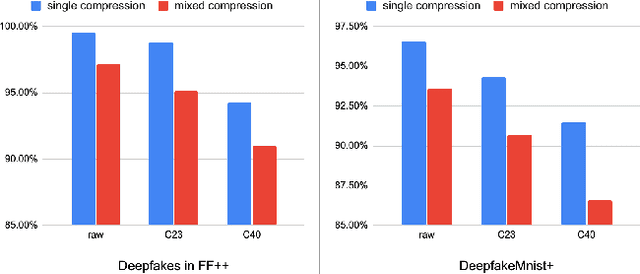
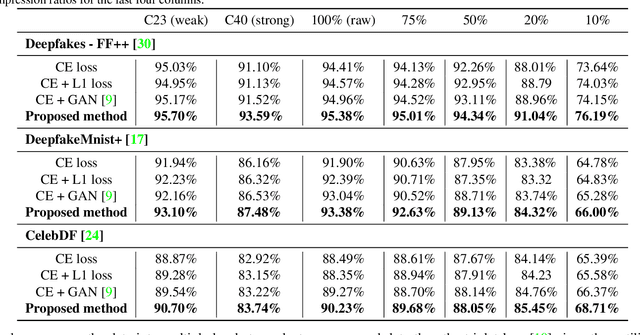

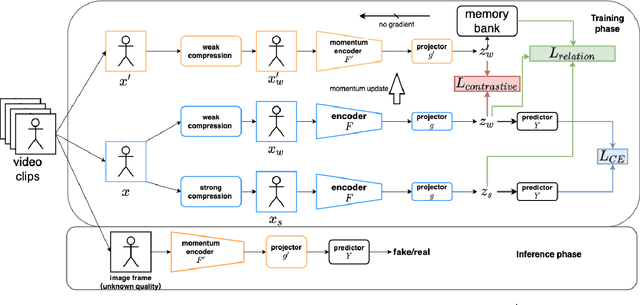
Forgery facial images and videos have increased the concern of digital security. It leads to the significant development of detecting forgery data recently. However, the data, especially the videos published on the Internet, are usually compressed with lossy compression algorithms such as H.264. The compressed data could significantly degrade the performance of recent detection algorithms. The existing anti-compression algorithms focus on enhancing the performance in detecting heavily compressed data but less consider the compression adaption to the data from various compression levels. We believe creating a forgery detection model that can handle the data compressed with unknown levels is important. To enhance the performance for such models, we consider the weak compressed and strong compressed data as two views of the original data and they should have similar representation and relationships with other samples. We propose a novel anti-compression forgery detection framework by maintaining closer relations within data under different compression levels. Specifically, the algorithm measures the pair-wise similarity within data as the relations, and forcing the relations of weak and strong compressed data close to each other, thus improving the discriminate power for detecting strong compressed data. To achieve a better strong compressed data relation guided by the less compressed one, we apply video level contrastive learning for weak compressed data, which forces the model to produce similar representations within the same video and far from the negative samples. The experiment results show that the proposed algorithm could boost performance for strong compressed data while improving the accuracy rate when detecting the clean data.
ContraFeat: Contrasting Deep Features for Semantic Discovery
Dec 14, 2022



StyleGAN has shown strong potential for disentangled semantic control, thanks to its special design of multi-layer intermediate latent variables. However, existing semantic discovery methods on StyleGAN rely on manual selection of modified latent layers to obtain satisfactory manipulation results, which is tedious and demanding. In this paper, we propose a model that automates this process and achieves state-of-the-art semantic discovery performance. The model consists of an attention-equipped navigator module and losses contrasting deep-feature changes. We propose two model variants, with one contrasting samples in a binary manner, and another one contrasting samples with learned prototype variation patterns. The proposed losses are defined with pretrained deep features, based on our assumption that the features can implicitly reveal the desired semantic structure including consistency and orthogonality. Additionally, we design two metrics to quantitatively evaluate the performance of semantic discovery methods on FFHQ dataset, and also show that disentangled representations can be derived via a simple training process. Experimentally, our models can obtain state-of-the-art semantic discovery results without relying on latent layer-wise manual selection, and these discovered semantics can be used to manipulate real-world images.
Commutative Lie Group VAE for Disentanglement Learning
Jun 07, 2021


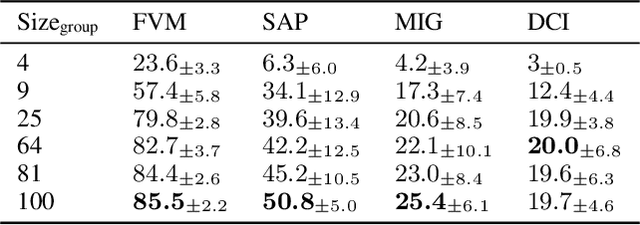
We view disentanglement learning as discovering an underlying structure that equivariantly reflects the factorized variations shown in data. Traditionally, such a structure is fixed to be a vector space with data variations represented by translations along individual latent dimensions. We argue this simple structure is suboptimal since it requires the model to learn to discard the properties (e.g. different scales of changes, different levels of abstractness) of data variations, which is an extra work than equivariance learning. Instead, we propose to encode the data variations with groups, a structure not only can equivariantly represent variations, but can also be adaptively optimized to preserve the properties of data variations. Considering it is hard to conduct training on group structures, we focus on Lie groups and adopt a parameterization using Lie algebra. Based on the parameterization, some disentanglement learning constraints are naturally derived. A simple model named Commutative Lie Group VAE is introduced to realize the group-based disentanglement learning. Experiments show that our model can effectively learn disentangled representations without supervision, and can achieve state-of-the-art performance without extra constraints.
Where and What? Examining Interpretable Disentangled Representations
Apr 07, 2021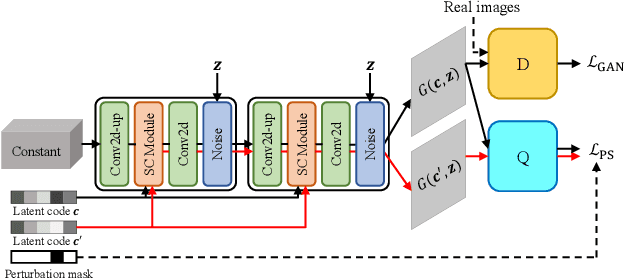



Capturing interpretable variations has long been one of the goals in disentanglement learning. However, unlike the independence assumption, interpretability has rarely been exploited to encourage disentanglement in the unsupervised setting. In this paper, we examine the interpretability of disentangled representations by investigating two questions: where to be interpreted and what to be interpreted? A latent code is easily to be interpreted if it would consistently impact a certain subarea of the resulting generated image. We thus propose to learn a spatial mask to localize the effect of each individual latent dimension. On the other hand, interpretability usually comes from latent dimensions that capture simple and basic variations in data. We thus impose a perturbation on a certain dimension of the latent code, and expect to identify the perturbation along this dimension from the generated images so that the encoding of simple variations can be enforced. Additionally, we develop an unsupervised model selection method, which accumulates perceptual distance scores along axes in the latent space. On various datasets, our models can learn high-quality disentangled representations without supervision, showing the proposed modeling of interpretability is an effective proxy for achieving unsupervised disentanglement.
Approximated Bilinear Modules for Temporal Modeling
Jul 25, 2020

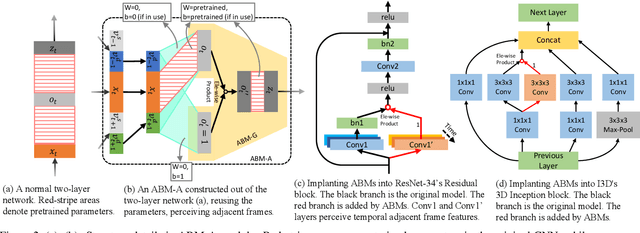
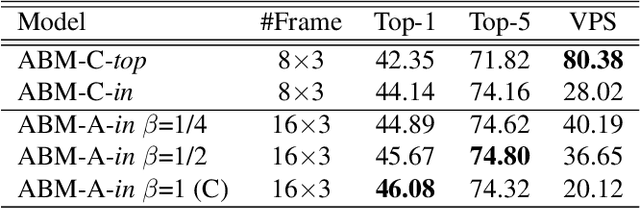
We consider two less-emphasized temporal properties of video: 1. Temporal cues are fine-grained; 2. Temporal modeling needs reasoning. To tackle both problems at once, we exploit approximated bilinear modules (ABMs) for temporal modeling. There are two main points making the modules effective: two-layer MLPs can be seen as a constraint approximation of bilinear operations, thus can be used to construct deep ABMs in existing CNNs while reusing pretrained parameters; frame features can be divided into static and dynamic parts because of visual repetition in adjacent frames, which enables temporal modeling to be more efficient. Multiple ABM variants and implementations are investigated, from high performance to high efficiency. Specifically, we show how two-layer subnets in CNNs can be converted to temporal bilinear modules by adding an auxiliary-branch. Besides, we introduce snippet sampling and shifting inference to boost sparse-frame video classification performance. Extensive ablation studies are conducted to show the effectiveness of proposed techniques. Our models can outperform most state-of-the-art methods on Something-Something v1 and v2 datasets without Kinetics pretraining, and are also competitive on other YouTube-like action recognition datasets. Our code is available on https://github.com/zhuxinqimac/abm-pytorch.
Learning Disentangled Representations with Latent Variation Predictability
Jul 25, 2020
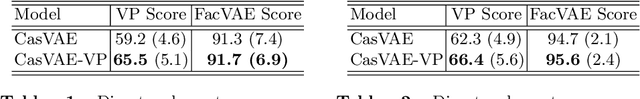
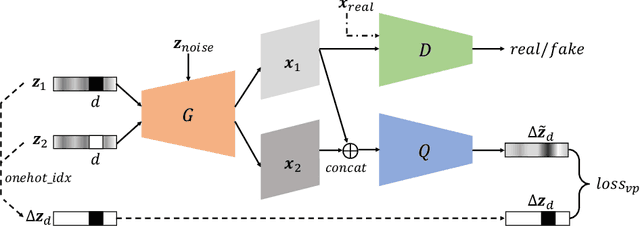
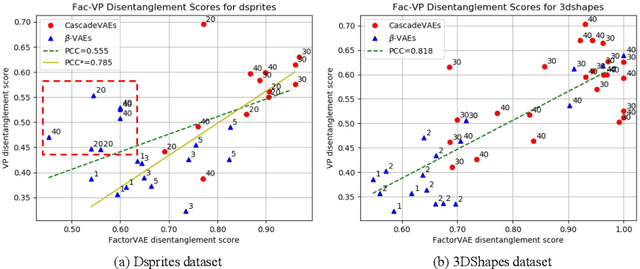
Latent traversal is a popular approach to visualize the disentangled latent representations. Given a bunch of variations in a single unit of the latent representation, it is expected that there is a change in a single factor of variation of the data while others are fixed. However, this impressive experimental observation is rarely explicitly encoded in the objective function of learning disentangled representations. This paper defines the variation predictability of latent disentangled representations. Given image pairs generated by latent codes varying in a single dimension, this varied dimension could be closely correlated with these image pairs if the representation is well disentangled. Within an adversarial generation process, we encourage variation predictability by maximizing the mutual information between latent variations and corresponding image pairs. We further develop an evaluation metric that does not rely on the ground-truth generative factors to measure the disentanglement of latent representations. The proposed variation predictability is a general constraint that is applicable to the VAE and GAN frameworks for boosting disentanglement of latent representations. Experiments show that the proposed variation predictability correlates well with existing ground-truth-required metrics and the proposed algorithm is effective for disentanglement learning.
B-CNN: Branch Convolutional Neural Network for Hierarchical Classification
Oct 05, 2017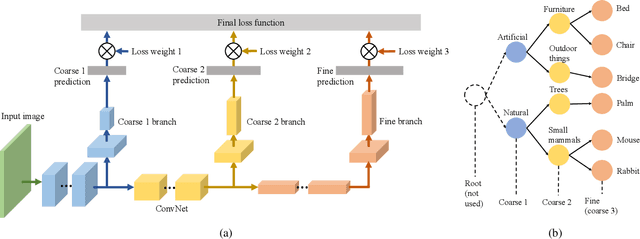
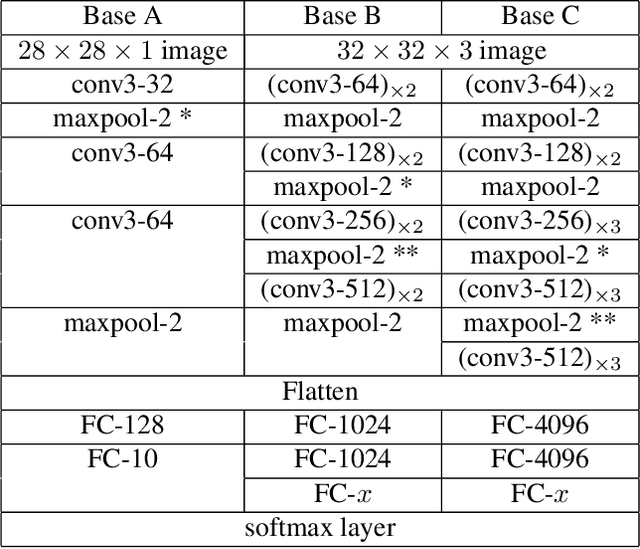
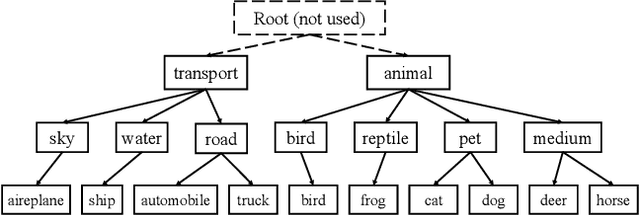
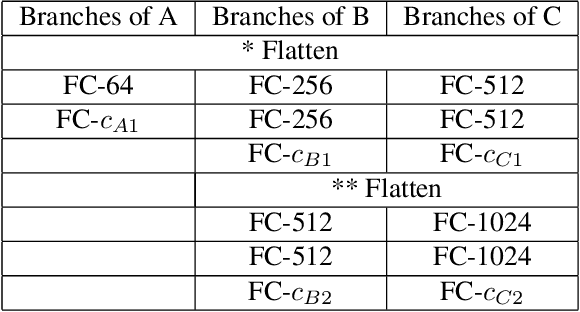
Convolutional Neural Network (CNN) image classifiers are traditionally designed to have sequential convolutional layers with a single output layer. This is based on the assumption that all target classes should be treated equally and exclusively. However, some classes can be more difficult to distinguish than others, and classes may be organized in a hierarchy of categories. At the same time, a CNN is designed to learn internal representations that abstract from the input data based on its hierarchical layered structure. So it is natural to ask if an inverse of this idea can be applied to learn a model that can predict over a classification hierarchy using multiple output layers in decreasing order of class abstraction. In this paper, we introduce a variant of the traditional CNN model named the Branch Convolutional Neural Network (B-CNN). A B-CNN model outputs multiple predictions ordered from coarse to fine along the concatenated convolutional layers corresponding to the hierarchical structure of the target classes, which can be regarded as a form of prior knowledge on the output. To learn with B-CNNs a novel training strategy, named the Branch Training strategy (BT-strategy), is introduced which balances the strictness of the prior with the freedom to adjust parameters on the output layers to minimize the loss. In this way we show that CNN based models can be forced to learn successively coarse to fine concepts in the internal layers at the output stage, and that hierarchical prior knowledge can be adopted to boost CNN models' classification performance. Our models are evaluated to show that the B-CNN extensions improve over the corresponding baseline CNN on the benchmark datasets MNIST, CIFAR-10 and CIFAR-100.