 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAP: Structure-Aware Masked Image Modeling for Human-Centric Perception
Oct 31, 2023Model pre-training is essential in human-centric perception. In this paper, we first introduce masked image modeling (MIM) as a pre-training approach for this task. Upon revisiting the MIM training strategy, we reveal that human structure priors offer significant potential. Motivated by this insight, we further incorporate an intuitive human structure prior - human parts - into pre-training. Specifically, we employ this prior to guide the mask sampling process. Image patches, corresponding to human part regions, have high priority to be masked out. This encourages the model to concentrate more on body structure information during pre-training, yielding substantial benefits across a range of human-centric perception tasks. To further capture human characteristics, we propose a structure-invariant alignment loss that enforces different masked views, guided by the human part prior, to be closely aligned for the same image. We term the entire method as HAP. HAP simply uses a plain ViT as the encoder yet establishes new state-of-the-art performance on 11 human-centric benchmarks, and on-par result on one dataset. For example, HAP achieves 78.1% mAP on MSMT17 for person re-identification, 86.54% mA on PA-100K for pedestrian attribute recognition, 78.2% AP on MS COCO for 2D pose estimation, and 56.0 PA-MPJPE on 3DPW for 3D pose and shape estimation.
Unified Pre-training with Pseudo Texts for Text-To-Image Person Re-identification
Sep 04, 2023



The pre-training task is indispensable for the text-to-image person re-identification (T2I-ReID) task. However, there are two underlying inconsistencies between these two tasks that may impact the performance; i) Data inconsistency. A large domain gap exists between the generic images/texts used in public pre-trained models and the specific person data in the T2I-ReID task. This gap is especially severe for texts, as general textual data are usually unable to describe specific people in fine-grained detail. ii) Training inconsistency. The processes of pre-training of images and texts are independent, despite cross-modality learning being critical to T2I-ReID. To address the above issues, we present a new unified pre-training pipeline (UniPT) designed specifically for the T2I-ReID task. We first build a large-scale text-labeled person dataset "LUPerson-T", in which pseudo-textual descriptions of images are automatically generated by the CLIP paradigm using a divide-conquer-combine strategy. Benefiting from this dataset, we then utilize a simple vision-and-language pre-training framework to explicitly align the feature space of the image and text modalities during pre-training. In this way, the pre-training task and the T2I-ReID task are made consistent with each other on both data and training levels. Without the need for any bells and whistles, our UniPT achieves competitive Rank-1 accuracy of, ie, 68.50%, 60.09%, and 51.85% on CUHK-PEDES, ICFG-PEDES and RSTPReid, respectively. Both the LUPerson-T dataset and code are available at https;//github.com/ZhiyinShao-H/UniPT.
Mining False Positive Examples for Text-Based Person Re-identification
Mar 15, 2023



Text-based person re-identification (ReID) aims to identify images of the targeted person from a large-scale person image database according to a given textual description. However, due to significant inter-modal gaps, text-based person ReID remains a challenging problem. Most existing methods generally rely heavily on the similarity contributed by matched word-region pairs, while neglecting mismatched word-region pairs which may play a decisive role. Accordingly, we propose to mine false positive examples (MFPE) via a jointly optimized multi-branch architecture to handle this problem. MFPE contains three branches including a false positive mining (FPM) branch to highlight the role of mismatched word-region pairs. Besides, MFPE delicately designs a cross-relu loss to increase the gap of similarity scores between matched and mismatched word-region pairs. Extensive experiments on CUHK-PEDES demonstrate the superior effectiveness of MFPE. Our code is released at https://github.com/xx-adeline/MFPE.
Learning Granularity-Unified Representations for Text-to-Image Person Re-identification
Jul 16, 2022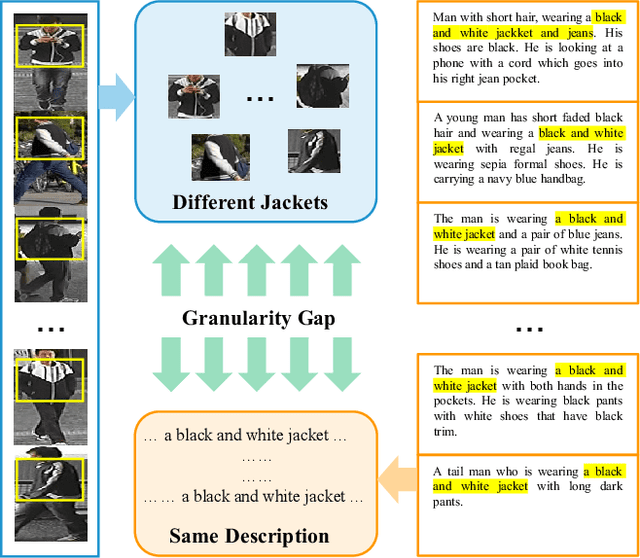
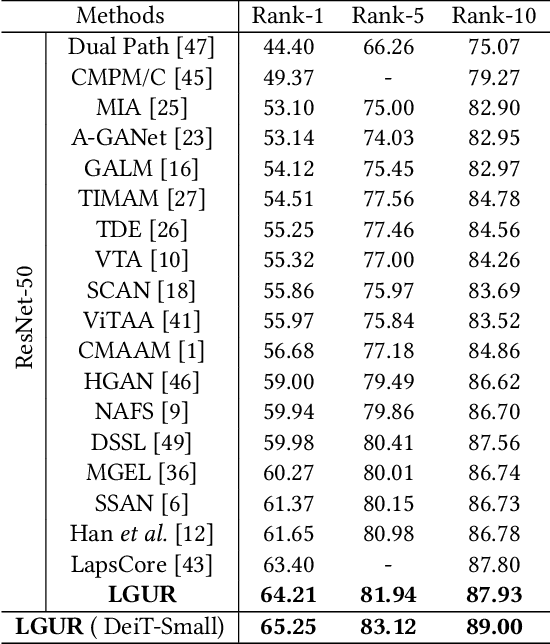
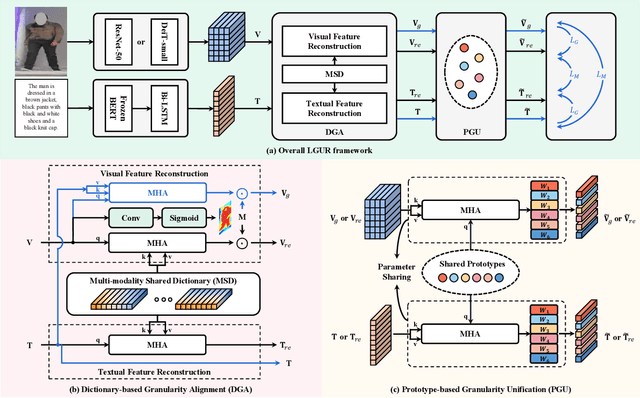
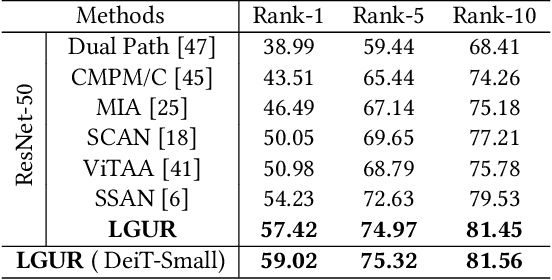
Text-to-image person re-identification (ReID) aims to search for pedestrian images of an interested identity via textual descriptions. It is challenging due to both rich intra-modal variations and significant inter-modal gaps. Existing works usually ignore the difference in feature granularity between the two modalities, i.e., the visual features are usually fine-grained while textual features are coarse, which is mainly responsible for the large inter-modal gaps. In this paper, we propose an end-to-end framework based on transformers to learn granularity-unified representations for both modalities, denoted as LGUR. LGUR framework contains two modules: a Dictionary-based Granularity Alignment (DGA) module and a Prototype-based Granularity Unification (PGU) module. In DGA, in order to align the granularities of two modalities, we introduce a Multi-modality Shared Dictionary (MSD) to reconstruct both visual and textual features. Besides, DGA has two important factors, i.e., the cross-modality guidance and the foreground-centric reconstruction, to facilitate the optimization of MSD. In PGU, we adopt a set of shared and learnable prototypes as the queries to extract diverse and semantically aligned features for both modalities in the granularity-unified feature space, which further promotes the ReID performance. Comprehensive experiments show that our LGUR consistently outperforms state-of-the-arts by large margins on both CUHK-PEDES and ICFG-PEDES datasets. Code will be released at https://github.com/ZhiyinShao-H/LGUR.
Quality-aware Part Models for Occluded Person Re-identification
Jan 01, 2022
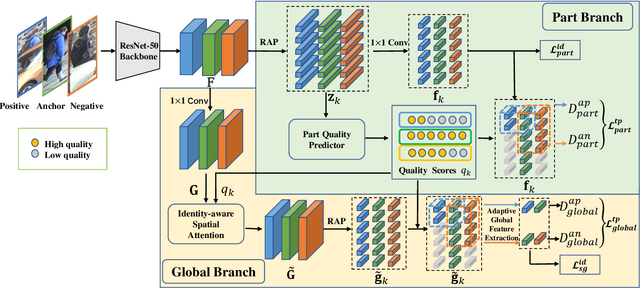


Occlusion poses a major challenge for person re-identification (ReID). Existing approaches typically rely on outside tools to infer visible body parts, which may be suboptimal in terms of both computational efficiency and ReID accuracy. In particular, they may fail when facing complex occlusions, such as those between pedestrians. Accordingly, in this paper, we propose a novel method named Quality-aware Part Models (QPM) for occlusion-robust ReID. First, we propose to jointly learn part features and predict part quality scores. As no quality annotation is available, we introduce a strategy that automatically assigns low scores to occluded body parts, thereby weakening the impact of occluded body parts on ReID results. Second, based on the predicted part quality scores, we propose a novel identity-aware spatial attention (ISA) module. In this module, a coarse identity-aware feature is utilized to highlight pixels of the target pedestrian, so as to handle the occlusion between pedestrians. Third, we design an adaptive and efficient approach for generating global features from common non-occluded regions with respect to each image pair. This design is crucial, but is often ignored by existing methods. QPM has three key advantages: 1) it does not rely on any outside tools in either the training or inference stages; 2) it handles occlusions caused by both objects and other pedestrians;3) it is highly computationally efficient. Experimental results on four popular databases for occluded ReID demonstrate that QPM consistently outperforms state-of-the-art methods by significant margins. The code of QPM will be released.
Semantically Self-Aligned Network for Text-to-Image Part-aware Person Re-identification
Aug 09, 2021
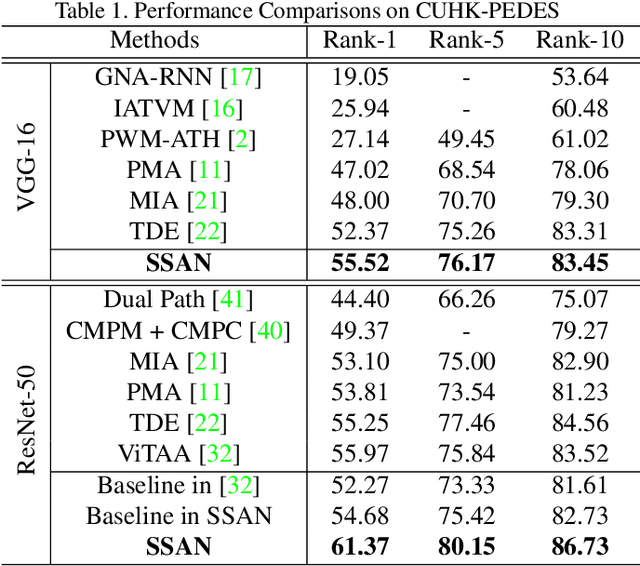
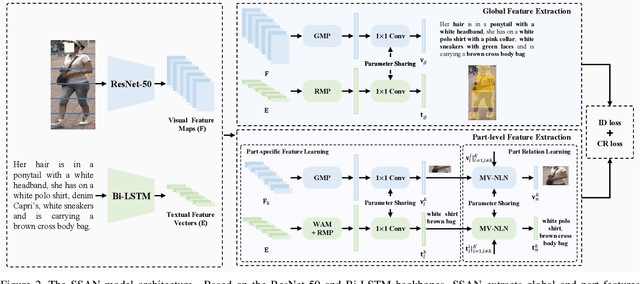
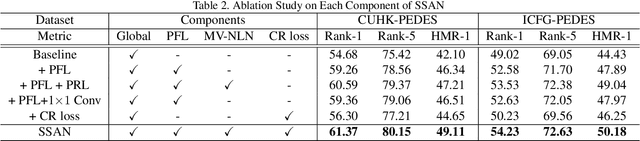
Text-to-image person re-identification (ReID) aims to search for images containing a person of interest using textual descriptions. However, due to the significant modality gap and the large intra-class variance in textual descriptions, text-to-image ReID remains a challenging problem. Accordingly, in this paper, we propose a Semantically Self-Aligned Network (SSAN) to handle the above problems. First, we propose a novel method that automatically extracts semantically aligned part-level features from the two modalities. Second, we design a multi-view non-local network that captures the relationships between body parts, thereby establishing better correspondences between body parts and noun phrases. Third, we introduce a Compound Ranking (CR) loss that makes use of textual descriptions for other images of the same identity to provide extra supervision, thereby effectively reducing the intra-class variance in textual features. Finally, to expedite future research in text-to-image ReID, we build a new database named ICFG-PEDES. Extensive experiments demonstrate that SSAN outperforms state-of-the-art approaches by significant margins. Both the new ICFG-PEDES database and the SSAN code are available at https://github.com/zifyloo/SSAN.