 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Self-Aligned Network for Text-to-Image Part-aware Person Re-identification
Aug 09, 2021
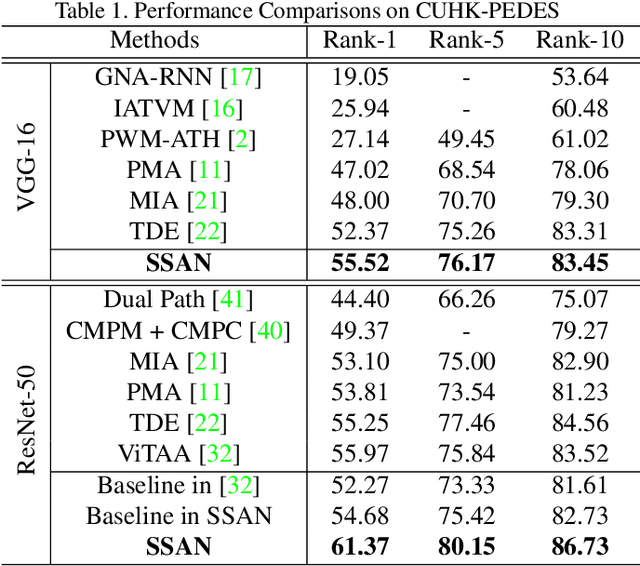
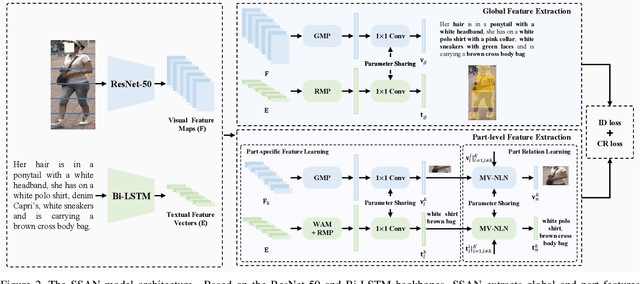
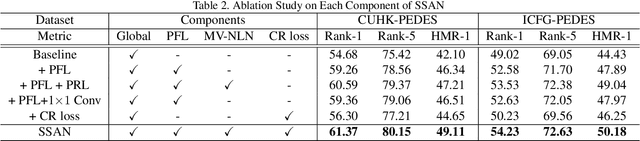
Text-to-image person re-identification (ReID) aims to search for images containing a person of interest using textual descriptions. However, due to the significant modality gap and the large intra-class variance in textual descriptions, text-to-image ReID remains a challenging problem. Accordingly, in this paper, we propose a Semantically Self-Aligned Network (SSAN) to handle the above problems. First, we propose a novel method that automatically extracts semantically aligned part-level features from the two modalities. Second, we design a multi-view non-local network that captures the relationships between body parts, thereby establishing better correspondences between body parts and noun phrases. Third, we introduce a Compound Ranking (CR) loss that makes use of textual descriptions for other images of the same identity to provide extra supervision, thereby effectively reducing the intra-class variance in textual features. Finally, to expedite future research in text-to-image ReID, we build a new database named ICFG-PEDES. Extensive experiments demonstrate that SSAN outperforms state-of-the-art approaches by significant margins. Both the new ICFG-PEDES database and the SSAN code are available at https://github.com/zifyloo/SSAN.