 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIVT: An End-to-End Instance-guided Video Transformer for 3D Pose Estimation
Paper and Code
Aug 06, 2022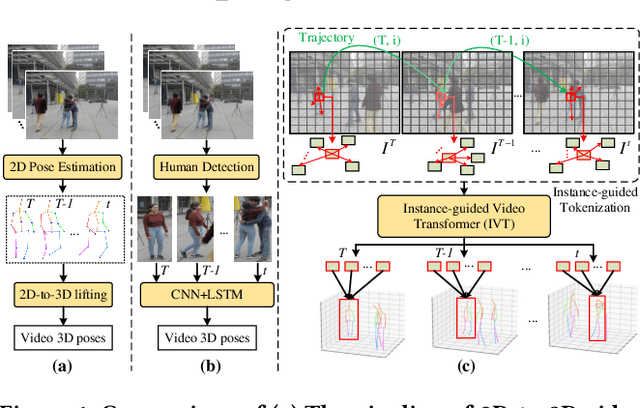
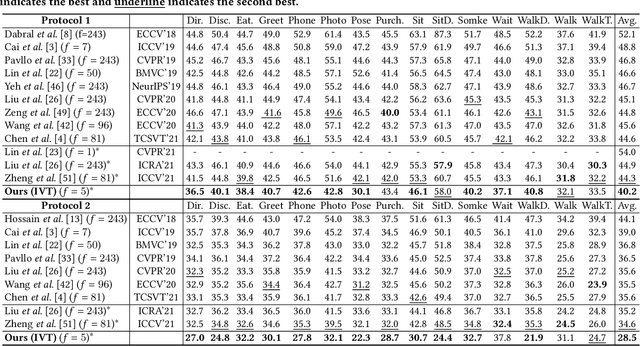
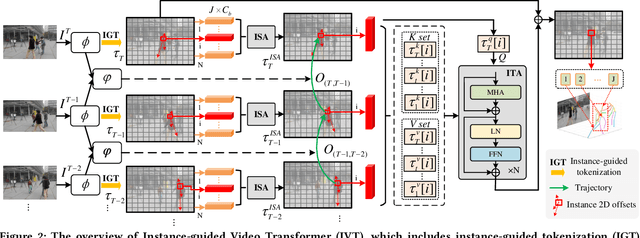
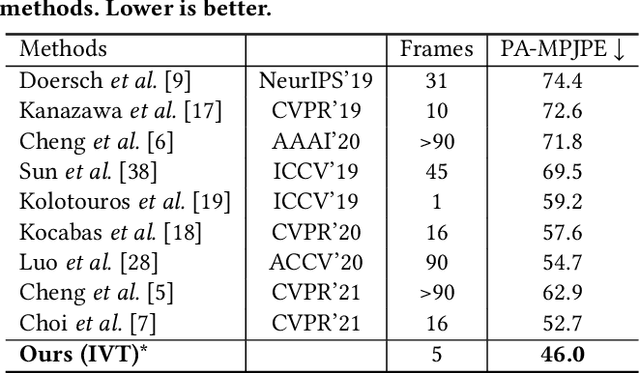
Video 3D human pose estimation aims to localize the 3D coordinates of human joints from videos. Recent transformer-based approaches focus on capturing the spatiotemporal information from sequential 2D poses, which cannot model the contextual depth feature effectively since the visual depth features are lost in the step of 2D pose estimation. In this paper, we simplify the paradigm into an end-to-end framework, Instance-guided Video Transformer (IVT), which enables learning spatiotemporal contextual depth information from visual features effectively and predicts 3D poses directly from video frames. In particular, we firstly formulate video frames as a series of instance-guided tokens and each token is in charge of predicting the 3D pose of a human instance. These tokens contain body structure information since they are extracted by the guidance of joint offsets from the human center to the corresponding body joints. Then, these tokens are sent into IVT for learning spatiotemporal contextual depth. In addition, we propose a cross-scale instance-guided attention mechanism to handle the variational scales among multiple persons. Finally, the 3D poses of each person are decoded from instance-guided tokens by coordinate regression. Experiments on three widely-used 3D pose estimation benchmarks show that the proposed IVT achieves state-of-the-art performances.