 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Graph Reasoning for Multi-person 3D Pose Estimation
Paper and Code
Aug 06, 2022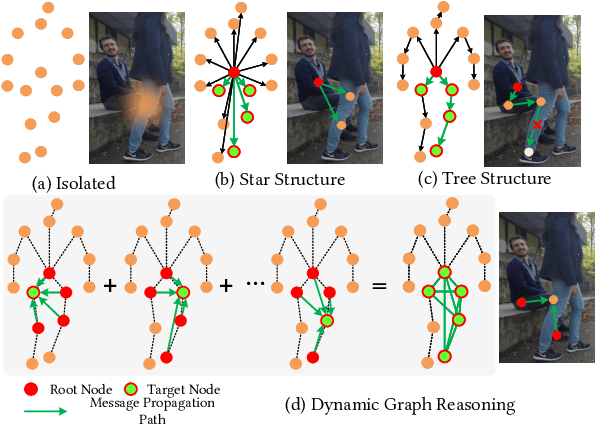


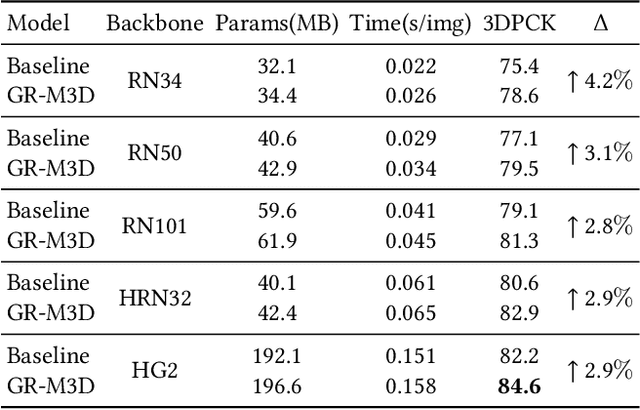
Multi-person 3D pose estimation is a challenging task because of occlusion and depth ambiguity, especially in the cases of crowd scenes. To solve these problems, most existing methods explore modeling body context cues by enhancing feature representation with graph neural networks or adding structural constraints. However, these methods are not robust for their single-root formulation that decoding 3D poses from a root node with a pre-defined graph. In this paper, we propose GR-M3D, which models the \textbf{M}ulti-person \textbf{3D} pose estimation with dynamic \textbf{G}raph \textbf{R}easoning. The decoding graph in GR-M3D is predicted instead of pre-defined. In particular, It firstly generates several data maps and enhances them with a scale and depth aware refinement module (SDAR). Then multiple root keypoints and dense decoding paths for each person are estimated from these data maps. Based on them, dynamic decoding graphs are built by assigning path weights to the decoding paths, while the path weights are inferred from those enhanced data maps. And this process is named dynamic graph reasoning (DGR). Finally, the 3D poses are decoded according to dynamic decoding graphs for each detected person. GR-M3D can adjust the structure of the decoding graph implicitly by adopting soft path weights according to input data, which makes the decoding graphs be adaptive to different input persons to the best extent and more capable of handling occlusion and depth ambiguity than previous methods. We empirically show that the proposed bottom-up approach even outperforms top-down methods and achieves state-of-the-art results on three 3D pose datasets.