 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLIM-Brain: A Data- and Training-Efficient Foundation Model for fMRI Data Analysis
Dec 26, 2025Foundation models are emerging as a powerful paradigm for fMRI analysis, but current approaches face a dual bottleneck of data- and training-efficiency. Atlas-based methods aggregate voxel signals into fixed regions of interest, reducing data dimensionality but discarding fine-grained spatial details, and requiring extremely large cohorts to train effectively as general-purpose foundation models. Atlas-free methods, on the other hand, operate directly on voxel-level information - preserving spatial fidelity but are prohibitively memory- and compute-intensive, making large-scale pre-training infeasible. We introduce SLIM-Brain (Sample-efficient, Low-memory fMRI Foundation Model for Human Brain), a new atlas-free foundation model that simultaneously improves both data- and training-efficiency. SLIM-Brain adopts a two-stage adaptive design: (i) a lightweight temporal extractor captures global context across full sequences and ranks data windows by saliency, and (ii) a 4D hierarchical encoder (Hiera-JEPA) learns fine-grained voxel-level representations only from the top-$k$ selected windows, while deleting about 70% masked patches. Extensive experiments across seven public benchmarks show that SLIM-Brain establishes new state-of-the-art performance on diverse tasks, while requiring only 4 thousand pre-training sessions and approximately 30% of GPU memory comparing to traditional voxel-level methods.
ICH-Qwen: A Large Language Model Towards Chinese Intangible Cultural Heritage
May 28, 2025The intangible cultural heritage (ICH) of China, a cultural asset transmitted across generations by various ethnic groups, serves as a significant testament to the evolution of human civilization and holds irreplaceable value for the preservation of historical lineage and the enhancement of cultural self-confidence. However, the rapid pace of modernization poses formidable challenges to ICH, including threats damage, disappearance and discontinuity of inheritance. China has the highest number of items on the UNESCO Intangible Cultural Heritage List, which is indicative of the nation's abundant cultural resources and emphasises the pressing need for ICH preservation. In recent years, the rapid advancements in large language modelling have provided a novel technological approach for the preservation and dissemination of ICH. This study utilises a substantial corpus of open-source Chinese ICH data to develop a large language model, ICH-Qwen, for the ICH domain. The model employs natural language understanding and knowledge reasoning capabilities of large language models, augmented with synthetic data and fine-tuning techniques. The experimental results demonstrate the efficacy of ICH-Qwen in executing tasks specific to the ICH domain. It is anticipated that the model will provide intelligent solutions for the protection, inheritance and dissemination of intangible cultural heritage, as well as new theoretical and practical references for the sustainable development of intangible cultural heritage. Furthermore, it is expected that the study will open up new paths for digital humanities research.
Variations on a Theme by Blahut and Arimoto
May 04, 2023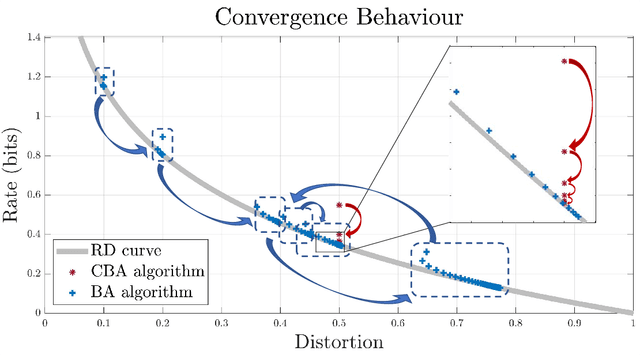
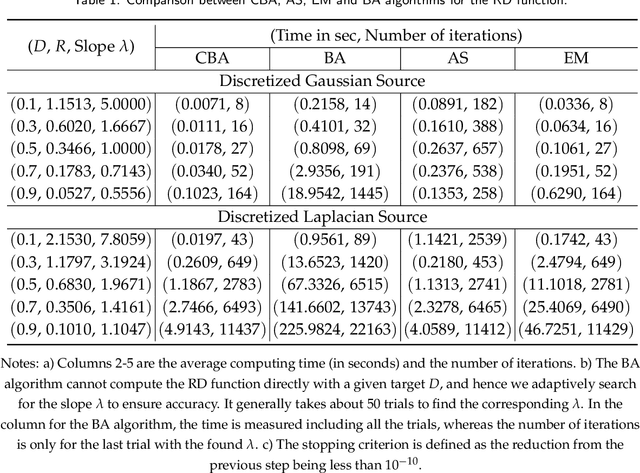
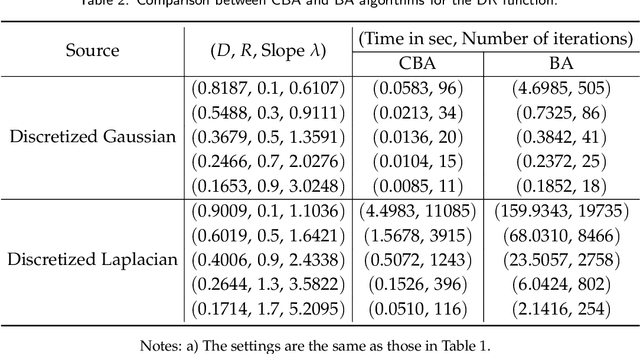
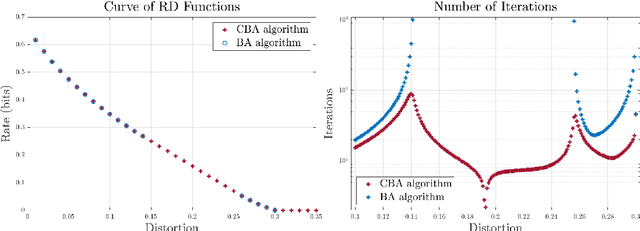
The Blahut-Arimoto (BA) algorithm has played a fundamental role in the numerical computation of rate-distortion (RD) functions. This algorithm possesses a desirable monotonic convergence property by alternatively minimizing its Lagrangian with a fixed multiplier. In this paper, we propose a novel modification of the BA algorithm, letting the multiplier be updated in each iteration via a one-dimensional root-finding step with respect to a monotonic univariate function, which can be efficiently implemented by Newton's method. This allows the multiplier to be updated in a flexible and efficient manner, overcoming a major drawback of the original BA algorithm wherein the multiplier is fixed throughout iterations. Consequently, the modified algorithm is capable of directly computing the RD function for a given target distortion, without exploring the entire RD curve as in the original BA algorithm. A theoretical analysis shows that the modified algorithm still converges to the RD function and the convergence rate is $\Theta(1/n)$, where $n$ denotes the number of iterations. Numerical experiments demonstrate that the modified algorithm directly computes the RD function with a given target distortion, and it significantly accelerates the original BA algorithm.