 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Grained Activation Steering: Steering Less, Achieving More
Feb 04, 2026Activation steering has emerged as a cost-effective paradigm for modifying large language model (LLM) behaviors. Existing methods typically intervene at the block level, steering the bundled activations of selected attention heads, feedforward networks, or residual streams. However, we reveal that block-level activations are inherently heterogeneous, entangling beneficial, irrelevant, and harmful features, thereby rendering block-level steering coarse, inefficient, and intrusive. To investigate the root cause, we decompose block activations into fine-grained atomic unit (AU)-level activations, where each AU-level activation corresponds to a single dimension of the block activation, and each AU denotes a slice of the block weight matrix. Steering an AU-level activation is thus equivalent to steering its associated AU. Our theoretical and empirical analysis show that heterogeneity arises because different AUs or dimensions control distinct token distributions in LLM outputs. Hence, block-level steering inevitably moves helpful and harmful token directions together, which reduces efficiency. Restricting intervention to beneficial AUs yields more precise and effective steering. Building on this insight, we propose AUSteer, a simple and efficient method that operates at a finer granularity of the AU level. AUSteer first identifies discriminative AUs globally by computing activation momenta on contrastive samples. It then assigns adaptive steering strengths tailored to diverse inputs and selected AU activations. Comprehensive experiments on multiple LLMs and tasks show that AUSteer consistently surpasses advanced baselines while steering considerably fewer activations, demonstrating that steering less achieves more.
Rethinking Prompt Optimizers: From Prompt Merits to Optimization
May 15, 2025
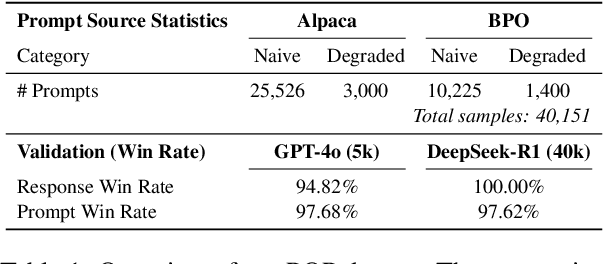
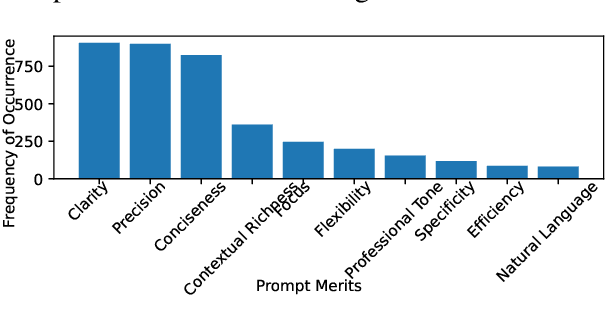
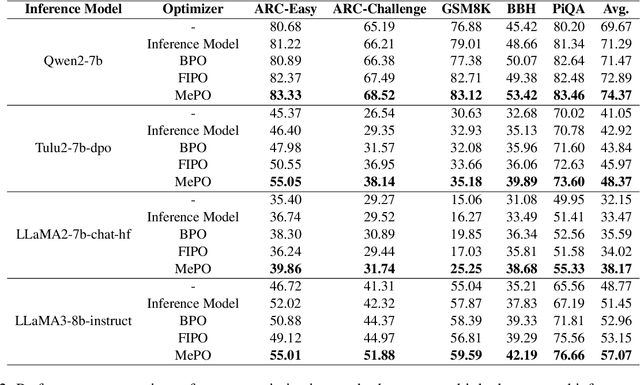
Prompt optimization (PO) offers a practical alternative to fine-tuning large language models (LLMs), enabling performance improvements without altering model weights. Existing methods typically rely on advanced, large-scale LLMs like GPT-4 to generate optimized prompts. However, due to limited downward compatibility, verbose, instruction-heavy prompts from advanced LLMs can overwhelm lightweight inference models and degrade response quality. In this work, we rethink prompt optimization through the lens of interpretable design. We first identify a set of model-agnostic prompt quality merits and empirically validate their effectiveness in enhancing prompt and response quality. We then introduce MePO, a merit-guided, lightweight, and locally deployable prompt optimizer trained on our preference dataset built from merit-aligned prompts generated by a lightweight LLM. Unlike prior work, MePO avoids online optimization reliance, reduces cost and privacy concerns, and, by learning clear, interpretable merits, generalizes effectively to both large-scale and lightweight inference models. Experiments demonstrate that MePO achieves better results across diverse tasks and model types, offering a scalable and robust solution for real-world deployment. Our model and dataset are available at: https://github.com/MidiyaZhu/MePO
Beyond the Next Token: Towards Prompt-Robust Zero-Shot Classification via Efficient Multi-Token Prediction
Apr 04, 2025



Zero-shot text classification typically relies on prompt engineering, but the inherent prompt brittleness of large language models undermines its reliability. Minor changes in prompt can cause significant discrepancies in model performance. We attribute this prompt brittleness largely to the narrow focus on nexttoken probabilities in existing methods. To address this, we propose Placeholding Parallel Prediction (P3), a novel approach that predicts token probabilities across multiple positions and simulates comprehensive sampling of generation paths in a single run of a language model. Experiments show improved accuracy and up to 98% reduction in the standard deviation across prompts, boosting robustness. Even without a prompt, P3 maintains comparable performance, reducing the need for prompt engineering.
FreeCtrl: Constructing Control Centers with Feedforward Layers for Learning-Free Controllable Text Generation
Jun 14, 2024



Controllable text generation (CTG) seeks to craft texts adhering to specific attributes, traditionally employing learning-based techniques such as training, fine-tuning, or prefix-tuning with attribute-specific datasets. These approaches, while effective, demand extensive computational and data resources. In contrast, some proposed learning-free alternatives circumvent learning but often yield inferior results, exemplifying the fundamental machine learning trade-off between computational expense and model efficacy. To overcome these limitations, we propose FreeCtrl, a learning-free approach that dynamically adjusts the weights of selected feedforward neural network (FFN) vectors to steer the outputs of large language models (LLMs). FreeCtrl hinges on the principle that the weights of different FFN vectors influence the likelihood of different tokens appearing in the output. By identifying and adaptively adjusting the weights of attribute-related FFN vectors, FreeCtrl can control the output likelihood of attribute keywords in the generated content. Extensive experiments on single- and multi-attribute control reveal that the learning-free FreeCtrl outperforms other learning-free and learning-based methods, successfully resolving the dilemma between learning costs and model performance.
UniBias: Unveiling and Mitigating LLM Bias through Internal Attention and FFN Manipulation
May 31, 2024Large language models (LLMs) have demonstrated impressive capabilities in various tasks using the in-context learning (ICL) paradigm. However, their effectiveness is often compromised by inherent bias, leading to prompt brittleness, i.e., sensitivity to design settings such as example selection, order, and prompt formatting. Previous studies have addressed LLM bias through external adjustment of model outputs, but the internal mechanisms that lead to such bias remain unexplored. Our work delves into these mechanisms, particularly investigating how feedforward neural networks (FFNs) and attention heads result in the bias of LLMs. By Interpreting the contribution of individual FFN vectors and attention heads, we identify the biased LLM components that skew LLMs' prediction toward specific labels. To mitigate these biases, we introduce UniBias, an inference-only method that effectively identifies and eliminates biased FFN vectors and attention heads. Extensive experiments across 12 NLP datasets demonstrate that UniBias significantly enhances ICL performance and alleviates prompt brittleness of LLMs.
Unveiling and Manipulating Prompt Influence in Large Language Models
May 20, 2024Prompts play a crucial role in guiding the responses of Large Language Models (LLMs). However, the intricate role of individual tokens in prompts, known as input saliency, in shaping the responses remains largely underexplored. Existing saliency methods either misalign with LLM generation objectives or rely heavily on linearity assumptions, leading to potential inaccuracies. To address this, we propose Token Distribution Dynamics (TDD), a \textcolor{black}{simple yet effective} approach to unveil and manipulate the role of prompts in generating LLM outputs. TDD leverages the robust interpreting capabilities of the language model head (LM head) to assess input saliency. It projects input tokens into the embedding space and then estimates their significance based on distribution dynamics over the vocabulary. We introduce three TDD variants: forward, backward, and bidirectional, each offering unique insights into token relevance. Extensive experiments reveal that the TDD surpasses state-of-the-art baselines with a big margin in elucidating the causal relationships between prompts and LLM outputs. Beyond mere interpretation, we apply TDD to two prompt manipulation tasks for controlled text generation: zero-shot toxic language suppression and sentiment steering. Empirical results underscore TDD's proficiency in identifying both toxic and sentimental cues in prompts, subsequently mitigating toxicity or modulating sentiment in the generated content.
GAM-Depth: Self-Supervised Indoor Depth Estimation Leveraging a Gradient-Aware Mask and Semantic Constraints
Feb 22, 2024



Self-supervised depth estimation has evolved into an image reconstruction task that minimizes a photometric loss. While recent methods have made strides in indoor depth estimation, they often produce inconsistent depth estimation in textureless areas and unsatisfactory depth discrepancies at object boundaries. To address these issues, in this work, we propose GAM-Depth, developed upon two novel components: gradient-aware mask and semantic constraints. The gradient-aware mask enables adaptive and robust supervision for both key areas and textureless regions by allocating weights based on gradient magnitudes.The incorporation of semantic constraints for indoor self-supervised depth estimation improves depth discrepancies at object boundaries, leveraging a co-optimization network and proxy semantic labels derived from a pretrained segmentation model. Experimental studies on three indoor datasets, including NYUv2, ScanNet, and InteriorNet, show that GAM-Depth outperforms existing methods and achieves state-of-the-art performance, signifying a meaningful step forward in indoor depth estimation. Our code will be available at https://github.com/AnqiCheng1234/GAM-Depth.
Heuristics-Driven Link-of-Analogy Prompting: Enhancing Large Language Models for Document-Level Event Argument Extraction
Nov 11, 2023



In this study, we investigate in-context learning (ICL) in document-level event argument extraction (EAE). The paper identifies key challenges in this problem, including example selection, context length limitation, abundance of event types, and the limitation of Chain-of-Thought (CoT) prompting in non-reasoning tasks. To address these challenges, we introduce the Heuristic-Driven Link-of-Analogy (HD-LoA) prompting method. Specifically, we hypothesize and validate that LLMs learn task-specific heuristics from demonstrations via ICL. Building upon this hypothesis, we introduce an explicit heuristic-driven demonstration construction approach, which transforms the haphazard example selection process into a methodical method that emphasizes task heuristics. Additionally, inspired by the analogical reasoning of human, we propose the link-of-analogy prompting, which enables LLMs to process new situations by drawing analogies to known situations, enhancing their adaptability. Extensive experiments show that our method outperforms the existing prompting methods and few-shot supervised learning methods, exhibiting F1 score improvements of 4.53% and 9.38% on the document-level EAE dataset. Furthermore, when applied to sentiment analysis and natural language inference tasks, the HD-LoA prompting achieves accuracy gains of 2.87% and 2.63%, indicating its effectiveness across different tasks.
Particle swarm optimization with state-based adaptive velocity limit strategy
Aug 02, 2023Velocity limit (VL) has been widely adopted in many variants of particle swarm optimization (PSO) to prevent particles from searching outside the solution space. Several adaptive VL strategies have been introduced with which the performance of PSO can be improved. However, the existing adaptive VL strategies simply adjust their VL based on iterations, leading to unsatisfactory optimization results because of the incompatibility between VL and the current searching state of particles. To deal with this problem, a novel PSO variant with state-based adaptive velocity limit strategy (PSO-SAVL) is proposed. In the proposed PSO-SAVL, VL is adaptively adjusted based on the evolutionary state estimation (ESE) in which a high value of VL is set for global searching state and a low value of VL is set for local searching state. Besides that, limit handling strategies have been modified and adopted to improve the capability of avoiding local optima. The good performance of PSO-SAVL has been experimentally validated on a wide range of benchmark functions with 50 dimensions. The satisfactory scalability of PSO-SAVL in high-dimension and large-scale problems is also verified. Besides, the merits of the strategies in PSO-SAVL are verified in experiments. Sensitivity analysis for the relevant hyper-parameters in state-based adaptive VL strategy is conducted, and insights in how to select these hyper-parameters are also discussed.
Feature-aware conditional GAN for category text generation
Aug 02, 2023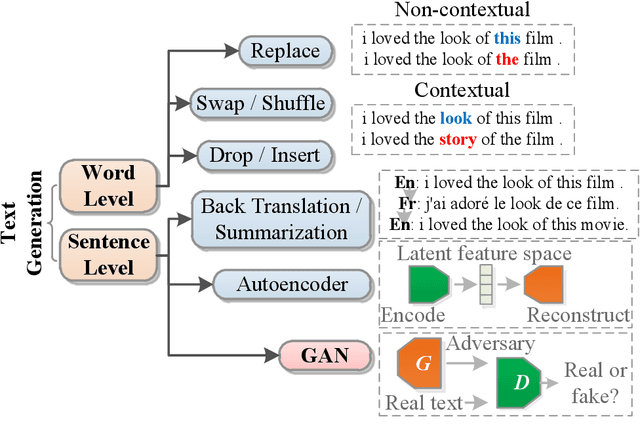
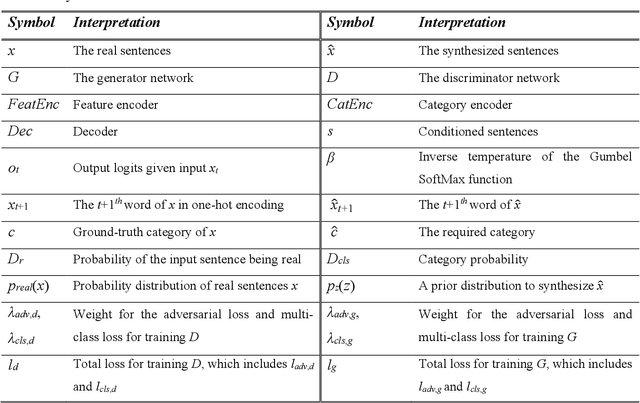
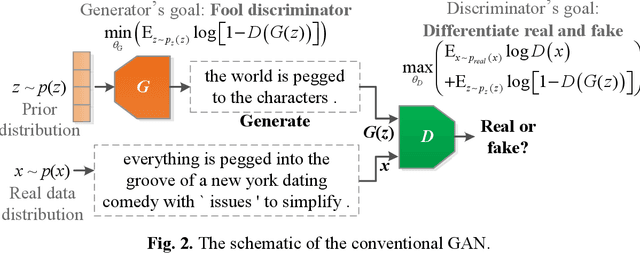
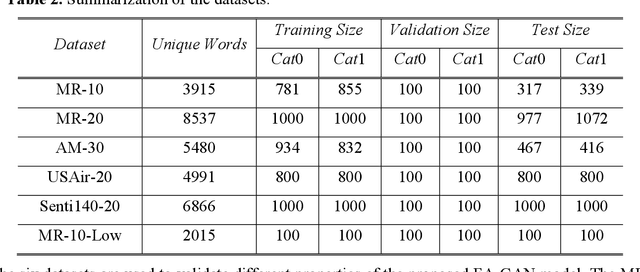
Category text generation receives considerable attentions since it is beneficial for various natural language processing tasks. Recently, the generative adversarial network (GAN) has attained promising performance in text generation, attributed to its adversarial training process. However, there are several issues in text GANs, including discreteness, training instability, mode collapse, lack of diversity and controllability etc. To address these issues, this paper proposes a novel GAN framework, the feature-aware conditional GAN (FA-GAN), for controllable category text generation. In FA-GAN, the generator has a sequence-to-sequence structure for improving sentence diversity, which consists of three encoders including a special feature-aware encoder and a category-aware encoder, and one relational-memory-core-based decoder with the Gumbel SoftMax activation function. The discriminator has an additional category classification head. To generate sentences with specified categories, the multi-class classification loss is supplemented in the adversarial training. Comprehensive experiments have been conducted, and the results show that FA-GAN consistently outperforms 10 state-of-the-art text generation approaches on 6 text classification datasets. The case study demonstrates that the synthetic sentences generated by FA-GAN can match the required categories and are aware of the features of conditioned sentences, with good readability, fluency, and text authenticity.