 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSoliReward: Mitigating Susceptibility to Reward Hacking and Annotation Noise in Video Generation Reward Models
Dec 17, 2025Post-training alignment of video generation models with human preferences is a critical goal. Developing effective Reward Models (RMs) for this process faces significant methodological hurdles. Current data collection paradigms, reliant on in-prompt pairwise annotations, suffer from labeling noise. Concurrently, the architectural design of VLM-based RMs, particularly their output mechanisms, remains underexplored. Furthermore, RM is susceptible to reward hacking in post-training. To mitigate these limitations, we propose SoliReward, a systematic framework for video RM training. Our framework first sources high-quality, cost-efficient data via single-item binary annotations, then constructs preference pairs using a cross-prompt pairing strategy. Architecturally, we employ a Hierarchical Progressive Query Attention mechanism to enhance feature aggregation. Finally, we introduce a modified BT loss that explicitly accommodates win-tie scenarios. This approach regularizes the RM's score distribution for positive samples, providing more nuanced preference signals to alleviate over-focus on a small number of top-scoring samples. Our approach is validated on benchmarks evaluating physical plausibility, subject deformity, and semantic alignment, demonstrating improvements in direct RM evaluation metrics and in the efficacy of post-training on video generation models. Code and benchmark will be publicly available.
SASep: Saliency-Aware Structured Separation of Geometry and Feature for Open Set Learning on Point Clouds
Jun 16, 2025Recent advancements in deep learning have greatly enhanced 3D object recognition, but most models are limited to closed-set scenarios, unable to handle unknown samples in real-world applications. Open-set recognition (OSR) addresses this limitation by enabling models to both classify known classes and identify novel classes. However, current OSR methods rely on global features to differentiate known and unknown classes, treating the entire object uniformly and overlooking the varying semantic importance of its different parts. To address this gap, we propose Salience-Aware Structured Separation (SASep), which includes (i) a tunable semantic decomposition (TSD) module to semantically decompose objects into important and unimportant parts, (ii) a geometric synthesis strategy (GSS) to generate pseudo-unknown objects by combining these unimportant parts, and (iii) a synth-aided margin separation (SMS) module to enhance feature-level separation by expanding the feature distributions between classes. Together, these components improve both geometric and feature representations, enhancing the model's ability to effectively distinguish known and unknown classes. Experimental results show that SASep achieves superior performance in 3D OSR, outperforming existing state-of-the-art methods.
Natural Language Fine-Tuning
Dec 29, 2024Large language model fine-tuning techniques typically depend on extensive labeled data, external guidance, and feedback, such as human alignment, scalar rewards, and demonstration. However, in practical application, the scarcity of specific knowledge poses unprecedented challenges to existing fine-tuning techniques. In this paper, focusing on fine-tuning tasks in specific domains with limited data, we introduce Natural Language Fine-Tuning (NLFT), which utilizes natural language for fine-tuning for the first time. By leveraging the strong language comprehension capability of the target LM, NLFT attaches the guidance of natural language to the token-level outputs. Then, saliency tokens are identified with calculated probabilities. Since linguistic information is effectively utilized in NLFT, our proposed method significantly reduces training costs. It markedly enhances training efficiency, comprehensively outperforming reinforcement fine-tuning algorithms in accuracy, time-saving, and resource conservation. Additionally, on the macro level, NLFT can be viewed as a token-level fine-grained optimization of SFT, thereby efficiently replacing the SFT process without the need for warm-up (as opposed to ReFT requiring multiple rounds of warm-up with SFT). Compared to SFT, NLFT does not increase the algorithmic complexity, maintaining O(n). Extensive experiments on the GSM8K dataset demonstrate that NLFT, with only 50 data instances, achieves an accuracy increase that exceeds SFT by 219%. Compared to ReFT, the time complexity and space complexity of NLFT are reduced by 78.27% and 92.24%, respectively. The superior technique of NLFT is paving the way for the deployment of various innovative LLM fine-tuning applications when resources are limited at network edges. Our code has been released at https://github.com/Julia-LiuJ/NLFT.
Fancy123: One Image to High-Quality 3D Mesh Generation via Plug-and-Play Deformation
Nov 25, 2024



Generating 3D meshes from a single image is an important but ill-posed task. Existing methods mainly adopt 2D multiview diffusion models to generate intermediate multiview images, and use the Large Reconstruction Model (LRM) to create the final meshes. However, the multiview images exhibit local inconsistencies, and the meshes often lack fidelity to the input image or look blurry. We propose Fancy123, featuring two enhancement modules and an unprojection operation to address the above three issues, respectively. The appearance enhancement module deforms the 2D multiview images to realign misaligned pixels for better multiview consistency. The fidelity enhancement module deforms the 3D mesh to match the input image. The unprojection of the input image and deformed multiview images onto LRM's generated mesh ensures high clarity, discarding LRM's predicted blurry-looking mesh colors. Extensive qualitative and quantitative experiments verify Fancy123's SoTA performance with significant improvement. Also, the two enhancement modules are plug-and-play and work at inference time, allowing seamless integration into various existing single-image-to-3D methods.
DCMAC: Demand-aware Customized Multi-Agent Communication via Upper Bound Training
Sep 11, 2024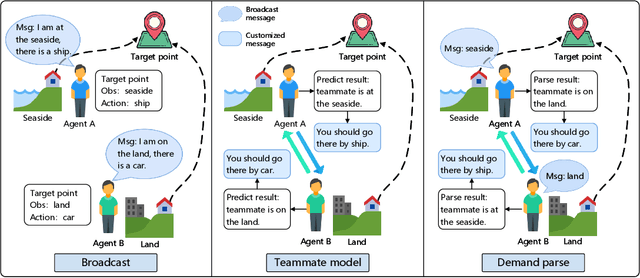
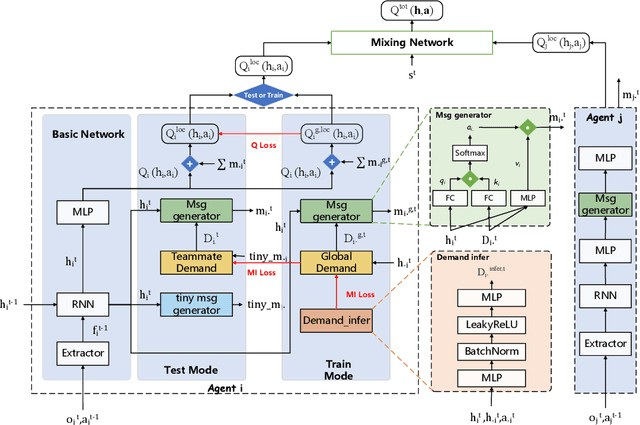
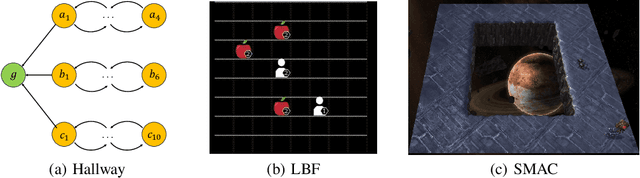
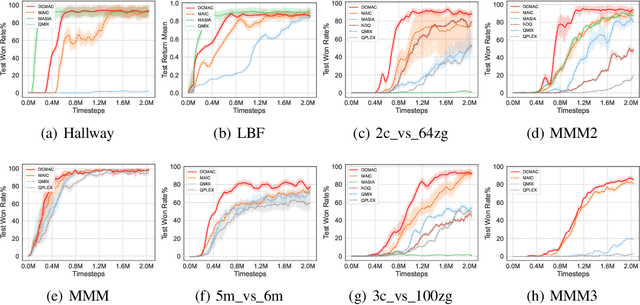
Efficient communication can enhance the overall performance of collaborative multi-agent reinforcement learning. A common approach is to share observations through full communication, leading to significant communication overhead. Existing work attempts to perceive the global state by conducting teammate model based on local information. However, they ignore that the uncertainty generated by prediction may lead to difficult training. To address this problem, we propose a Demand-aware Customized Multi-Agent Communication (DCMAC) protocol, which use an upper bound training to obtain the ideal policy. By utilizing the demand parsing module, agent can interpret the gain of sending local message on teammate, and generate customized messages via compute the correlation between demands and local observation using cross-attention mechanism. Moreover, our method can adapt to the communication resources of agents and accelerate the training progress by appropriating the ideal policy which is trained with joint observation. Experimental results reveal that DCMAC significantly outperforms the baseline algorithms in both unconstrained and communication constrained scenarios.
More Text, Less Point: Towards 3D Data-Efficient Point-Language Understanding
Aug 28, 2024
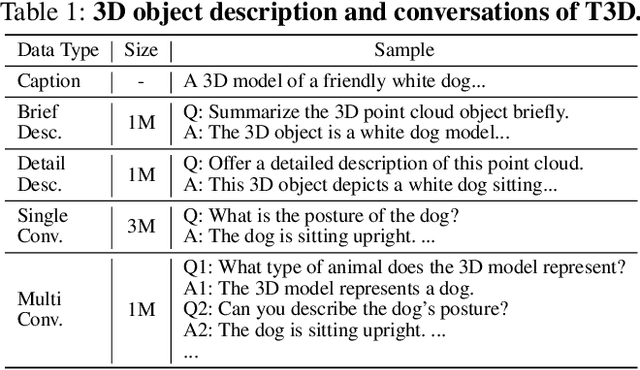
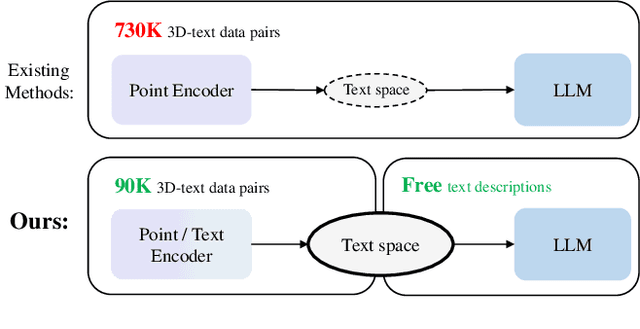
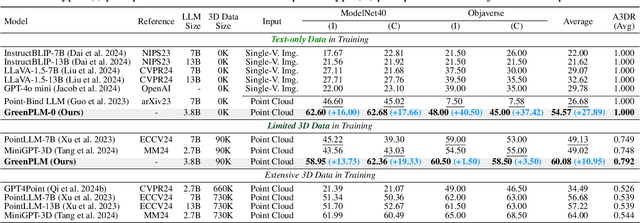
Enabling Large Language Models (LLMs) to comprehend the 3D physical world remains a significant challenge. Due to the lack of large-scale 3D-text pair datasets, the success of LLMs has yet to be replicated in 3D understanding. In this paper, we rethink this issue and propose a new task: 3D Data-Efficient Point-Language Understanding. The goal is to enable LLMs to achieve robust 3D object understanding with minimal 3D point cloud and text data pairs. To address this task, we introduce GreenPLM, which leverages more text data to compensate for the lack of 3D data. First, inspired by using CLIP to align images and text, we utilize a pre-trained point cloud-text encoder to map the 3D point cloud space to the text space. This mapping leaves us to seamlessly connect the text space with LLMs. Once the point-text-LLM connection is established, we further enhance text-LLM alignment by expanding the intermediate text space, thereby reducing the reliance on 3D point cloud data. Specifically, we generate 6M free-text descriptions of 3D objects, and design a three-stage training strategy to help LLMs better explore the intrinsic connections between different modalities. To achieve efficient modality alignment, we design a zero-parameter cross-attention module for token pooling. Extensive experimental results show that GreenPLM requires only 12% of the 3D training data used by existing state-of-the-art models to achieve superior 3D understanding. Remarkably, GreenPLM also achieves competitive performance using text-only data. The code and weights are available at: https://github.com/TangYuan96/GreenPLM.
Multimodal Physiological Signals Representation Learning via Multiscale Contrasting for Depression Recognition
Jun 26, 2024



Depression recognition based on physiological signals such as functional near-infrared spectroscopy (fNIRS) and electroencephalogram (EEG) has made considerable progress. However, most existing studies ignore the complementarity and semantic consistency of multimodal physiological signals under the same stimulation task in complex spatio-temporal patterns. In this paper, we introduce a multimodal physiological signals representation learning framework using Siamese architecture via multiscale contrasting for depression recognition (MRLMC). First, fNIRS and EEG are transformed into different but correlated data based on a time-domain data augmentation strategy. Then, we design a spatio-temporal contrasting module to learn the representation of fNIRS and EEG through weight-sharing multiscale spatio-temporal convolution. Furthermore, to enhance the learning of semantic representation associated with stimulation tasks, a semantic consistency contrast module is proposed, aiming to maximize the semantic similarity of fNIRS and EEG. Extensive experiments on publicly available and self-collected multimodal physiological signals datasets indicate that MRLMC outperforms the state-of-the-art models. Moreover, our proposed framework is capable of transferring to multimodal time series downstream tasks.
PointDreamer: Zero-shot 3D Textured Mesh Reconstruction from Colored Point Cloud by 2D Inpainting
Jun 22, 2024Reconstructing textured meshes from colored point clouds is an important but challenging task in 3D graphics and vision. Most existing methods predict colors as implicit functions in 3D or UV space, suffering from blurry textures or the lack of generalization capability. Addressing this, we propose PointDreamer, a novel framework for textured mesh reconstruction from colored point cloud. It produces meshes with enhanced fidelity and clarity by 2D image inpainting, taking advantage of the mature techniques and massive data of 2D vision. Specifically, we first project the input point cloud into 2D space to generate sparse multi-view images, and then inpaint empty pixels utilizing a pre-trained 2D diffusion model. Next, we design a novel Non-Border-First strategy to unproject the colors of the inpainted dense images back to 3D space, thus obtaining the final textured mesh. In this way, our PointDreamer works in a zero-shot manner, requiring no extra training. Extensive qualitative and quantitative experiments on various synthetic and real-scanned datasets show the SoTA performance of PointDreamer, by significantly outperforming baseline methods with 30\% improvement in LPIPS score (from 0.118 to 0.068). Code at: https://github.com/YuQiao0303/PointDreamer.
Fusion-PSRO: Nash Policy Fusion for Policy Space Response Oracles
Jun 03, 2024A popular approach for solving zero-sum games is to maintain populations of policies to approximate the Nash Equilibrium (NE). Previous studies have shown that Policy Space Response Oracle (PSRO) algorithm is an effective multi-agent reinforcement learning framework for solving such games. However, repeatedly training new policies from scratch to approximate Best Response (BR) to opponents' mixed policies at each iteration is both inefficient and costly. While some PSRO variants initialize a new policy by inheriting from past BR policies, this approach limits the exploration of new policies, especially against challenging opponents. To address this issue, we propose Fusion-PSRO, which employs policy fusion to initialize policies for better approximation to BR. By selecting high-quality base policies from meta-NE, policy fusion fuses the base policies into a new policy through model averaging. This approach allows the initialized policies to incorporate multiple expert policies, making it easier to handle difficult opponents compared to inheriting from past BR policies or initializing from scratch. Moreover, our method only modifies the policy initialization phase, allowing its application to nearly all PSRO variants without additional training overhead. Our experiments on non-transitive matrix games, Leduc Poker, and the more complex Liars Dice demonstrate that Fusion-PSRO enhances the performance of nearly all PSRO variants, achieving lower exploitability.
MiniGPT-3D: Efficiently Aligning 3D Point Clouds with Large Language Models using 2D Priors
May 02, 2024



Large 2D vision-language models (2D-LLMs) have gained significant attention by bridging Large Language Models (LLMs) with images using a simple projector. Inspired by their success, large 3D point cloud-language models (3D-LLMs) also integrate point clouds into LLMs. However, directly aligning point clouds with LLM requires expensive training costs, typically in hundreds of GPU-hours on A100, which hinders the development of 3D-LLMs. In this paper, we introduce MiniGPT-3D, an efficient and powerful 3D-LLM that achieves multiple SOTA results while training for only 27 hours on one RTX 3090. Specifically, we propose to align 3D point clouds with LLMs using 2D priors from 2D-LLMs, which can leverage the similarity between 2D and 3D visual information. We introduce a novel four-stage training strategy for modality alignment in a cascaded way, and a mixture of query experts module to adaptively aggregate features with high efficiency. Moreover, we utilize parameter-efficient fine-tuning methods LoRA and Norm fine-tuning, resulting in only 47.8M learnable parameters, which is up to 260x fewer than existing methods. Extensive experiments show that MiniGPT-3D achieves SOTA on 3D object classification and captioning tasks, with significantly cheaper training costs. Notably, MiniGPT-3D gains an 8.12 increase on GPT-4 evaluation score for the challenging object captioning task compared to ShapeLLM-13B, while the latter costs 160 total GPU-hours on 8 A800. We are the first to explore the efficient 3D-LLM, offering new insights to the community. Code and weights are available at https://github.com/TangYuan96/MiniGPT-3D.