 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Finite Space Mean-Field Type Games
Sep 25, 2024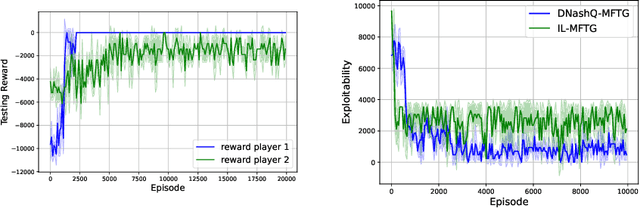

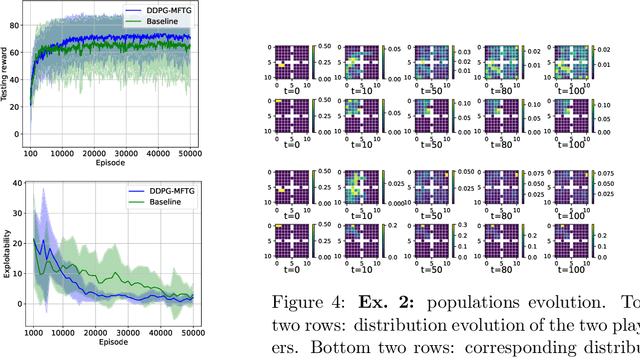
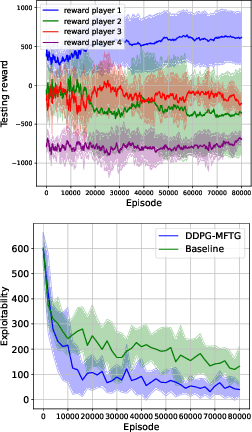
Mean field type games (MFTGs) describe Nash equilibria between large coalitions: each coalition consists of a continuum of cooperative agents who maximize the average reward of their coalition while interacting non-cooperatively with a finite number of other coalitions. Although the theory has been extensively developed, we are still lacking efficient and scalable computational methods. Here, we develop reinforcement learning methods for such games in a finite space setting with general dynamics and reward functions. We start by proving that MFTG solution yields approximate Nash equilibria in finite-size coalition games. We then propose two algorithms. The first is based on quantization of the mean-field spaces and Nash Q-learning. We provide convergence and stability analysis. We then propose an deep reinforcement learning algorithm, which can scale to larger spaces. Numerical examples on 5 environments show the scalability and the efficiency of the proposed method.
Multimodal Physiological Signals Representation Learning via Multiscale Contrasting for Depression Recognition
Jun 26, 2024



Depression recognition based on physiological signals such as functional near-infrared spectroscopy (fNIRS) and electroencephalogram (EEG) has made considerable progress. However, most existing studies ignore the complementarity and semantic consistency of multimodal physiological signals under the same stimulation task in complex spatio-temporal patterns. In this paper, we introduce a multimodal physiological signals representation learning framework using Siamese architecture via multiscale contrasting for depression recognition (MRLMC). First, fNIRS and EEG are transformed into different but correlated data based on a time-domain data augmentation strategy. Then, we design a spatio-temporal contrasting module to learn the representation of fNIRS and EEG through weight-sharing multiscale spatio-temporal convolution. Furthermore, to enhance the learning of semantic representation associated with stimulation tasks, a semantic consistency contrast module is proposed, aiming to maximize the semantic similarity of fNIRS and EEG. Extensive experiments on publicly available and self-collected multimodal physiological signals datasets indicate that MRLMC outperforms the state-of-the-art models. Moreover, our proposed framework is capable of transferring to multimodal time series downstream tasks.
Vis2Mus: Exploring Multimodal Representation Mapping for Controllable Music Generation
Nov 10, 2022In this study, we explore the representation mapping from the domain of visual arts to the domain of music, with which we can use visual arts as an effective handle to control music generation. Unlike most studies in multimodal representation learning that are purely data-driven, we adopt an analysis-by-synthesis approach that combines deep music representation learning with user studies. Such an approach enables us to discover \textit{interpretable} representation mapping without a huge amount of paired data. In particular, we discover that visual-to-music mapping has a nice property similar to equivariant. In other words, we can use various image transformations, say, changing brightness, changing contrast, style transfer, to control the corresponding transformations in the music domain. In addition, we released the Vis2Mus system as a controllable interface for symbolic music generation.