 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLORA: Efficient Synthetic Data Generation for Object Detection in Low-Data Regimes via finetuning Flux LoRA
Aug 29, 2025Recent advances in diffusion-based generative models have demonstrated significant potential in augmenting scarce datasets for object detection tasks. Nevertheless, most recent models rely on resource-intensive full fine-tuning of large-scale diffusion models, requiring enterprise-grade GPUs (e.g., NVIDIA V100) and thousands of synthetic images. To address these limitations, we propose Flux LoRA Augmentation (FLORA), a lightweight synthetic data generation pipeline. Our approach uses the Flux 1.1 Dev diffusion model, fine-tuned exclusively through Low-Rank Adaptation (LoRA). This dramatically reduces computational requirements, enabling synthetic dataset generation with a consumer-grade GPU (e.g., NVIDIA RTX 4090). We empirically evaluate our approach on seven diverse object detection datasets. Our results demonstrate that training object detectors with just 500 synthetic images generated by our approach yields superior detection performance compared to models trained on 5000 synthetic images from the ODGEN baseline, achieving improvements of up to 21.3% in mAP@.50:.95. This work demonstrates that it is possible to surpass state-of-the-art performance with far greater efficiency, as FLORA achieves superior results using only 10% of the data and a fraction of the computational cost. This work demonstrates that a quality and efficiency-focused approach is more effective than brute-force generation, making advanced synthetic data creation more practical and accessible for real-world scenarios.
CAD2DMD-SET: Synthetic Generation Tool of Digital Measurement Device CAD Model Datasets for fine-tuning Large Vision-Language Models
Aug 29, 2025Recent advancements in Large Vision-Language Models (LVLMs) have demonstrated impressive capabilities across various multimodal tasks. They continue, however, to struggle with trivial scenarios such as reading values from Digital Measurement Devices (DMDs), particularly in real-world conditions involving clutter, occlusions, extreme viewpoints, and motion blur; common in head-mounted cameras and Augmented Reality (AR) applications. Motivated by these limitations, this work introduces CAD2DMD-SET, a synthetic data generation tool designed to support visual question answering (VQA) tasks involving DMDs. By leveraging 3D CAD models, advanced rendering, and high-fidelity image composition, our tool produces diverse, VQA-labelled synthetic DMD datasets suitable for fine-tuning LVLMs. Additionally, we present DMDBench, a curated validation set of 1,000 annotated real-world images designed to evaluate model performance under practical constraints. Benchmarking three state-of-the-art LVLMs using Average Normalised Levenshtein Similarity (ANLS) and further fine-tuning LoRA's of these models with CAD2DMD-SET's generated dataset yielded substantial improvements, with InternVL showcasing a score increase of 200% without degrading on other tasks. This demonstrates that the CAD2DMD-SET training dataset substantially improves the robustness and performance of LVLMs when operating under the previously stated challenging conditions. The CAD2DMD-SET tool is expected to be released as open-source once the final version of this manuscript is prepared, allowing the community to add different measurement devices and generate their own datasets.
HERB: Human-augmented Efficient Reinforcement learning for Bin-packing
Apr 23, 2025Packing objects efficiently is a fundamental problem in logistics, warehouse automation, and robotics. While traditional packing solutions focus on geometric optimization, packing irregular, 3D objects presents significant challenges due to variations in shape and stability. Reinforcement Learning~(RL) has gained popularity in robotic packing tasks, but training purely from simulation can be inefficient and computationally expensive. In this work, we propose HERB, a human-augmented RL framework for packing irregular objects. We first leverage human demonstrations to learn the best sequence of objects to pack, incorporating latent factors such as space optimization, stability, and object relationships that are difficult to model explicitly. Next, we train a placement algorithm that uses visual information to determine the optimal object positioning inside a packing container. Our approach is validated through extensive performance evaluations, analyzing both packing efficiency and latency. Finally, we demonstrate the real-world feasibility of our method on a robotic system. Experimental results show that our method outperforms geometric and purely RL-based approaches by leveraging human intuition, improving both packing robustness and adaptability. This work highlights the potential of combining human expertise-driven RL to tackle complex real-world packing challenges in robotic systems.
AI-Powered Augmented Reality for Satellite Assembly, Integration and Test
Sep 26, 2024



The integration of Artificial Intelligence (AI) and Augmented Reality (AR) is set to transform satellite Assembly, Integration, and Testing (AIT) processes by enhancing precision, minimizing human error, and improving operational efficiency in cleanroom environments. This paper presents a technical description of the European Space Agency's (ESA) project "AI for AR in Satellite AIT," which combines real-time computer vision and AR systems to assist technicians during satellite assembly. Leveraging Microsoft HoloLens 2 as the AR interface, the system delivers context-aware instructions and real-time feedback, tackling the complexities of object recognition and 6D pose estimation in AIT workflows. All AI models demonstrated over 70% accuracy, with the detection model exceeding 95% accuracy, indicating a high level of performance and reliability. A key contribution of this work lies in the effective use of synthetic data for training AI models in AR applications, addressing the significant challenges of obtaining real-world datasets in highly dynamic satellite environments, as well as the creation of the Segmented Anything Model for Automatic Labelling (SAMAL), which facilitates the automatic annotation of real data, achieving speeds up to 20 times faster than manual human annotation. The findings demonstrate the efficacy of AI-driven AR systems in automating critical satellite assembly tasks, setting a foundation for future innovations in the space industry.
3DSGrasp: 3D Shape-Completion for Robotic Grasp
Jan 02, 2023



Real-world robotic grasping can be done robustly if a complete 3D Point Cloud Data (PCD) of an object is available. However, in practice, PCDs are often incomplete when objects are viewed from few and sparse viewpoints before the grasping action, leading to the generation of wrong or inaccurate grasp poses. We propose a novel grasping strategy, named 3DSGrasp, that predicts the missing geometry from the partial PCD to produce reliable grasp poses. Our proposed PCD completion network is a Transformer-based encoder-decoder network with an Offset-Attention layer. Our network is inherently invariant to the object pose and point's permutation, which generates PCDs that are geometrically consistent and completed properly. Experiments on a wide range of partial PCD show that 3DSGrasp outperforms the best state-of-the-art method on PCD completion tasks and largely improves the grasping success rate in real-world scenarios. The code and dataset will be made available upon acceptance.
Robotic Learning the Sequence of Packing Irregular Objects from Human Demonstrations
Oct 04, 2022


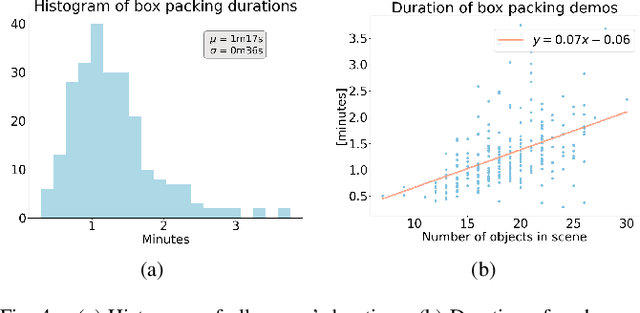
We address the unsolved task of robotic bin packing with irregular objects, such as groceries, where the underlying constraints on object placement and manipulation, and the diverse objects' physical properties make preprogrammed strategies unfeasible. Our approach is to learn directly from expert demonstrations in order to extract implicit task knowledge and strategies to achieve an efficient space usage, safe object positioning and to generate human-like behaviors that enhance human-robot trust. We collect and make available a novel and diverse dataset, BoxED, of box packing demonstrations by humans in virtual reality. In total, 263 boxes were packed with supermarket-like objects by 43 participants, yielding 4644 object manipulations. We use the BoxED dataset to learn a Markov chain to predict the object packing sequence for a given set of objects and compare it with human performance. Our experimental results show that the model surpasses human performance by generating sequence predictions that humans classify as human-like more frequently than human-generated sequences.
SENSORIMOTOR GRAPH: Action-Conditioned Graph Neural Network for Learning Robotic Soft Hand Dynamics
Jul 18, 2021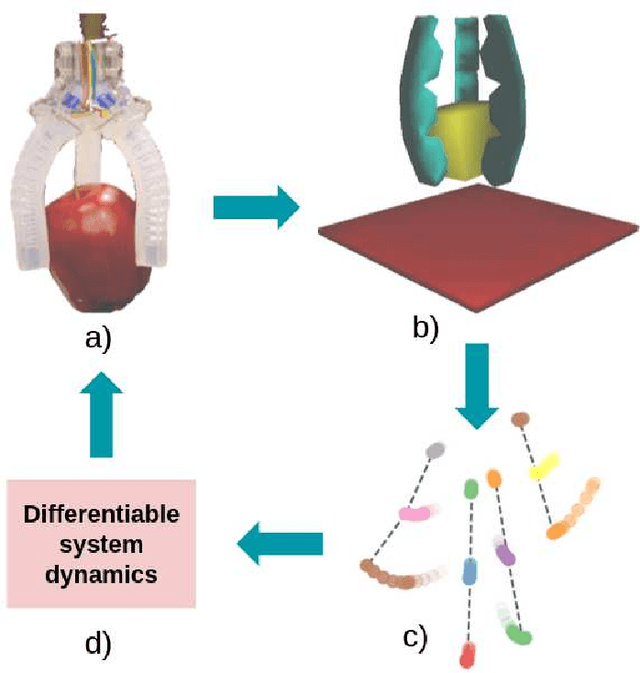
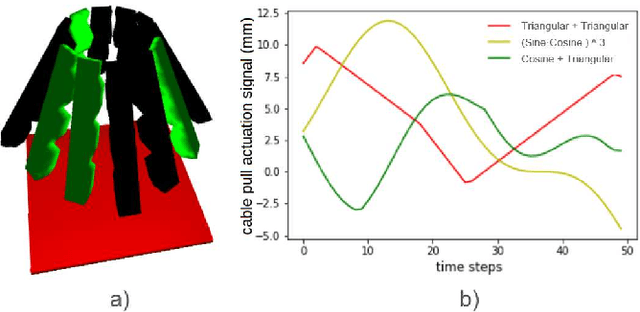
Soft robotics is a thriving branch of robotics which takes inspiration from nature and uses affordable flexible materials to design adaptable non-rigid robots. However, their flexible behavior makes these robots hard to model, which is essential for a precise actuation and for optimal control. For system modelling, learning-based approaches have demonstrated good results, yet they fail to consider the physical structure underlying the system as an inductive prior. In this work, we take inspiration from sensorimotor learning, and apply a Graph Neural Network to the problem of modelling a non-rigid kinematic chain (i.e. a robotic soft hand) taking advantage of two key properties: 1) the system is compositional, that is, it is composed of simple interacting parts connected by edges, 2) it is order invariant, i.e. only the structure of the system is relevant for predicting future trajectories. We denote our model as the 'Sensorimotor Graph' since it learns the system connectivity from observation and uses it for dynamics prediction. We validate our model in different scenarios and show that it outperforms the non-structured baselines in dynamics prediction while being more robust to configurational variations, tracking errors or node failures.
Action-conditioned Benchmarking of Robotic Video Prediction Models: a Comparative Study
Oct 07, 2019



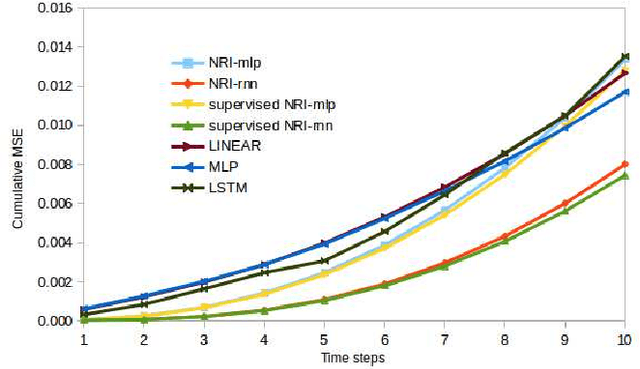
A defining characteristic of intelligent systems is the ability to make action decisions based on the anticipated outcomes. Video prediction systems have been demonstrated as a solution for predicting how the future will unfold visually, and thus, many models have been proposed that are capable of predicting future frames based on a history of observed frames~(and sometimes robot actions). However, a comprehensive method for determining the fitness of different video prediction models at guiding the selection of actions is yet to be developed. Current metrics assess video prediction models based on human perception of frame quality. In contrast, we argue that if these systems are to be used to guide action, necessarily, the actions the robot performs should be encoded in the predicted frames. In this paper, we are proposing a new metric to compare different video prediction models based on this argument. More specifically, we propose an action inference system and quantitatively rank different models based on how well we can infer the robot actions from the predicted frames. Our extensive experiments show that models with high perceptual scores can perform poorly in the proposed action inference tests and thus, may not be suitable options to be used in robot planning systems.
Automatic generation of object shapes with desired functionalities
Oct 16, 2018

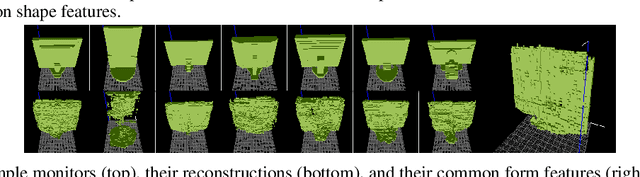
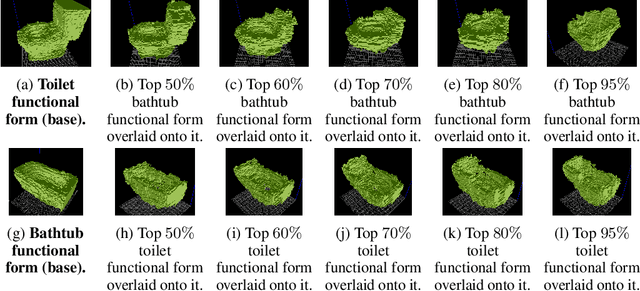
3D objects (artefacts) are made to fulfill functions. Designing an object often starts with defining a list of functionalities that it should provide, also known as functional requirements. Today, the design of 3D object models is still a slow and largely artisanal activity, with few Computer-Aided Design (CAD) tools existing to aid the exploration of the design solution space. To accelerate the design process, we introduce an algorithm for generating object shapes with desired functionalities. Following the concept of form follows function, we assume that existing object shapes were rationally chosen to provide desired functionalities. First, we use an artificial neural network to learn a function-to-form mapping by analysing a dataset of objects labeled with their functionalities. Then, we combine forms providing one or more desired functions, generating an object shape that is expected to provide all of them. Finally, we verify in simulation whether the generated object possesses the desired functionalities, by defining and executing functionality tests on it.
Applying Domain Randomization to Synthetic Data for Object Category Detection
Jul 16, 2018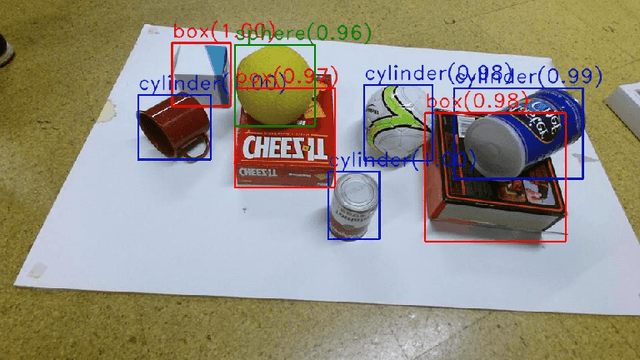



Recent advances in deep learning-based object detection techniques have revolutionized their applicability in several fields. However, since these methods rely on unwieldy and large amounts of data, a common practice is to download models pre-trained on standard datasets and fine-tune them for specific application domains with a small set of domain relevant images. In this work, we show that using synthetic datasets that are not necessarily photo-realistic can be a better alternative to simply fine-tune pre-trained networks. Specifically, our results show an impressive 25% improvement in the mAP metric over a fine-tuning baseline when only about 200 labelled images are available to train. Finally, an ablation study of our results is presented to delineate the individual contribution of different components in the randomization pipeline.