 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Domain Randomization to Synthetic Data for Object Category Detection
Paper and Code
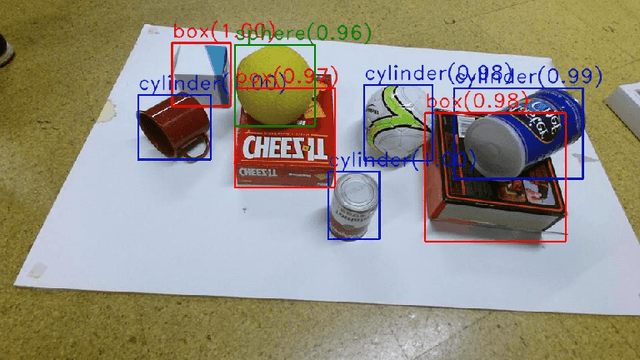



Recent advances in deep learning-based object detection techniques have revolutionized their applicability in several fields. However, since these methods rely on unwieldy and large amounts of data, a common practice is to download models pre-trained on standard datasets and fine-tune them for specific application domains with a small set of domain relevant images. In this work, we show that using synthetic datasets that are not necessarily photo-realistic can be a better alternative to simply fine-tune pre-trained networks. Specifically, our results show an impressive 25% improvement in the mAP metric over a fine-tuning baseline when only about 200 labelled images are available to train. Finally, an ablation study of our results is presented to delineate the individual contribution of different components in the randomization pipeline.