 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIDEE: Tidying Up Novel Rooms using Visuo-Semantic Commonsense Priors
Jul 21, 2022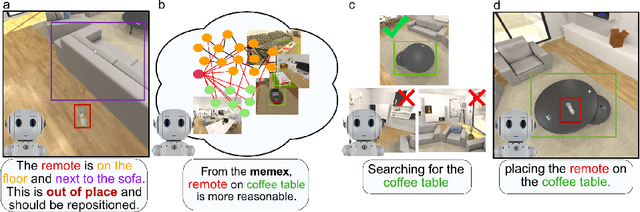
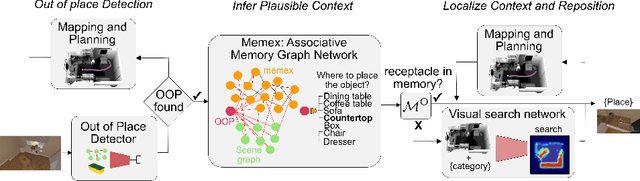

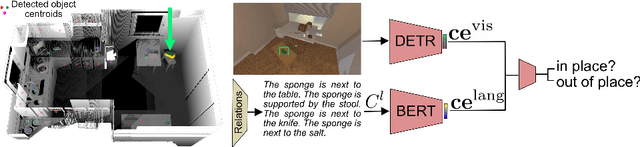
We introduce TIDEE, an embodied agent that tidies up a disordered scene based on learned commonsense object placement and room arrangement priors. TIDEE explores a home environment, detects objects that are out of their natural place, infers plausible object contexts for them, localizes such contexts in the current scene, and repositions the objects. Commonsense priors are encoded in three modules: i) visuo-semantic detectors that detect out-of-place objects, ii) an associative neural graph memory of objects and spatial relations that proposes plausible semantic receptacles and surfaces for object repositions, and iii) a visual search network that guides the agent's exploration for efficiently localizing the receptacle-of-interest in the current scene to reposition the object. We test TIDEE on tidying up disorganized scenes in the AI2THOR simulation environment. TIDEE carries out the task directly from pixel and raw depth input without ever having observed the same room beforehand, relying only on priors learned from a separate set of training houses. Human evaluations on the resulting room reorganizations show TIDEE outperforms ablative versions of the model that do not use one or more of the commonsense priors. On a related room rearrangement benchmark that allows the agent to view the goal state prior to rearrangement, a simplified version of our model significantly outperforms a top-performing method by a large margin. Code and data are available at the project website: https://tidee-agent.github.io/.
SENSORIMOTOR GRAPH: Action-Conditioned Graph Neural Network for Learning Robotic Soft Hand Dynamics
Jul 18, 2021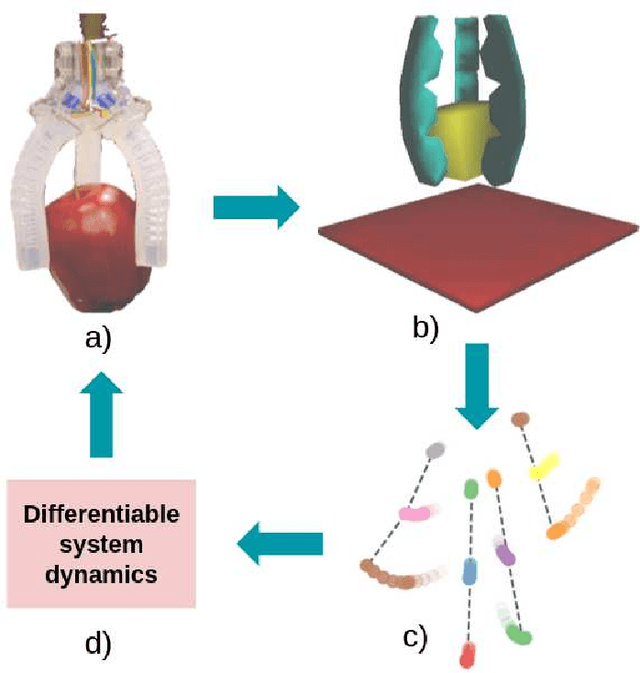
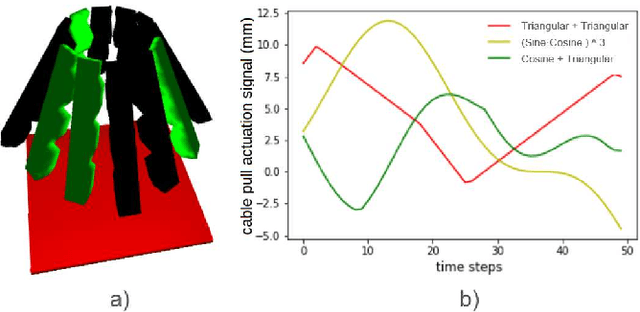
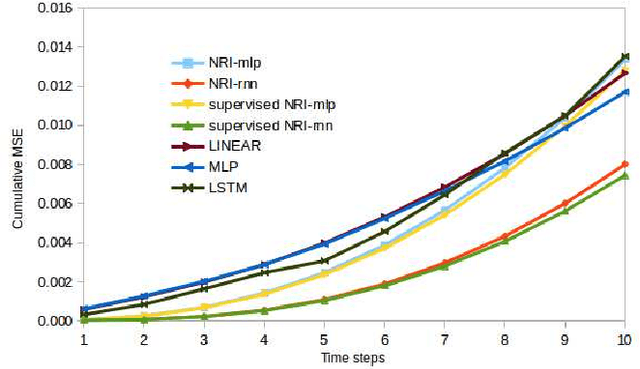
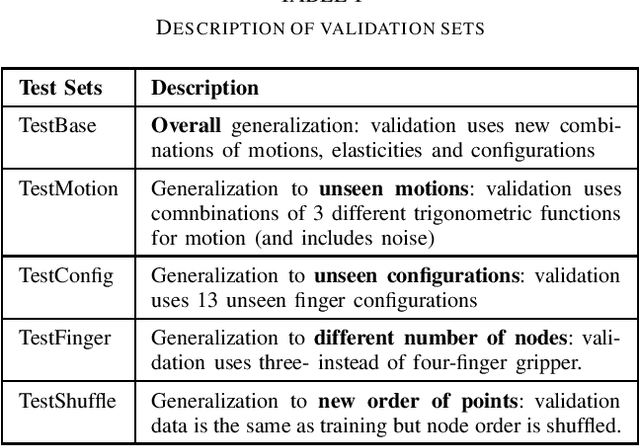
Soft robotics is a thriving branch of robotics which takes inspiration from nature and uses affordable flexible materials to design adaptable non-rigid robots. However, their flexible behavior makes these robots hard to model, which is essential for a precise actuation and for optimal control. For system modelling, learning-based approaches have demonstrated good results, yet they fail to consider the physical structure underlying the system as an inductive prior. In this work, we take inspiration from sensorimotor learning, and apply a Graph Neural Network to the problem of modelling a non-rigid kinematic chain (i.e. a robotic soft hand) taking advantage of two key properties: 1) the system is compositional, that is, it is composed of simple interacting parts connected by edges, 2) it is order invariant, i.e. only the structure of the system is relevant for predicting future trajectories. We denote our model as the 'Sensorimotor Graph' since it learns the system connectivity from observation and uses it for dynamics prediction. We validate our model in different scenarios and show that it outperforms the non-structured baselines in dynamics prediction while being more robust to configurational variations, tracking errors or node failures.
Tracking Emerges by Looking Around Static Scenes, with Neural 3D Mapping
Aug 04, 2020We hypothesize that an agent that can look around in static scenes can learn rich visual representations applicable to 3D object tracking in complex dynamic scenes. We are motivated in this pursuit by the fact that the physical world itself is mostly static, and multiview correspondence labels are relatively cheap to collect in static scenes, e.g., by triangulation. We propose to leverage multiview data of \textit{static points} in arbitrary scenes (static or dynamic), to learn a neural 3D mapping module which produces features that are correspondable across time. The neural 3D mapper consumes RGB-D data as input, and produces a 3D voxel grid of deep features as output. We train the voxel features to be correspondable across viewpoints, using a contrastive loss, and correspondability across time emerges automatically. At test time, given an RGB-D video with approximate camera poses, and given the 3D box of an object to track, we track the target object by generating a map of each timestep and locating the object's features within each map. In contrast to models that represent video streams in 2D or 2.5D, our model's 3D scene representation is disentangled from projection artifacts, is stable under camera motion, and is robust to partial occlusions. We test the proposed architectures in challenging simulated and real data, and show that our unsupervised 3D object trackers outperform prior unsupervised 2D and 2.5D trackers, and approach the accuracy of supervised trackers. This work demonstrates that 3D object trackers can emerge without tracking labels, through multiview self-supervision on static data.
Anticipation in Human-Robot Cooperation: A Recurrent Neural Network Approach for Multiple Action Sequences Prediction
Feb 18, 2019

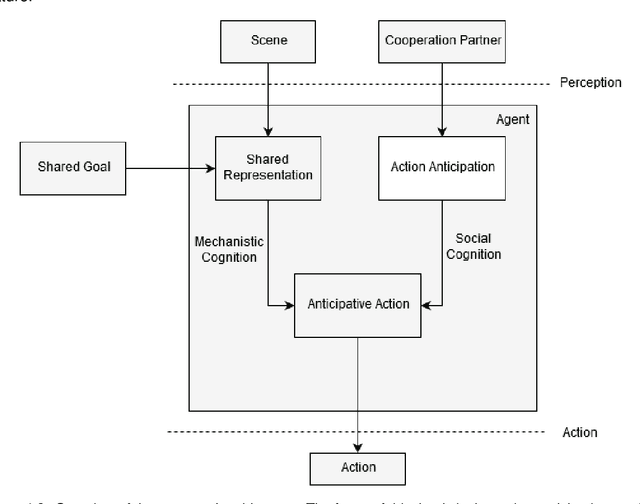
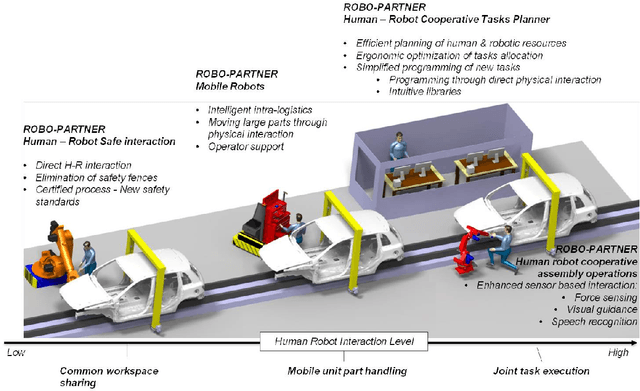
Close human-robot cooperation is a key enabler for new developments in advanced manufacturing and assistive applications. Close cooperation require robots that can predict human actions and intent, and understand human non-verbal cues. Recent approaches based on neural networks have led to encouraging results in the human action prediction problem both in continuous and discrete spaces. Our approach extends the research in this direction. Our contributions are three-fold. First, we validate the use of gaze and body pose cues as a means of predicting human action through a feature selection method. Next, we address two shortcomings of existing literature: predicting multiple and variable-length action sequences. This is achieved by introducing an encoder-decoder recurrent neural network topology in the discrete action prediction problem. In addition, we theoretically demonstrate the importance of predicting multiple action sequences as a means of estimating the stochastic reward in a human robot cooperation scenario. Finally, we show the ability to effectively train the prediction model on a action prediction dataset, involving human motion data, and explore the influence of the model's parameters on its performance. Source code repository: https://github.com/pschydlo/ActionAnticipation