 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalogy-Forming Transformers for Few-Shot 3D Parsing
Apr 27, 2023We present Analogical Networks, a model that encodes domain knowledge explicitly, in a collection of structured labelled 3D scenes, in addition to implicitly, as model parameters, and segments 3D object scenes with analogical reasoning: instead of mapping a scene to part segments directly, our model first retrieves related scenes from memory and their corresponding part structures, and then predicts analogous part structures for the input scene, via an end-to-end learnable modulation mechanism. By conditioning on more than one retrieved memories, compositions of structures are predicted, that mix and match parts across the retrieved memories. One-shot, few-shot or many-shot learning are treated uniformly in Analogical Networks, by conditioning on the appropriate set of memories, whether taken from a single, few or many memory exemplars, and inferring analogous parses. We show Analogical Networks are competitive with state-of-the-art 3D segmentation transformers in many-shot settings, and outperform them, as well as existing paradigms of meta-learning and few-shot learning, in few-shot settings. Analogical Networks successfully segment instances of novel object categories simply by expanding their memory, without any weight updates. Our code and models are publicly available in the project webpage: http://analogicalnets.github.io/.
TIDEE: Tidying Up Novel Rooms using Visuo-Semantic Commonsense Priors
Jul 21, 2022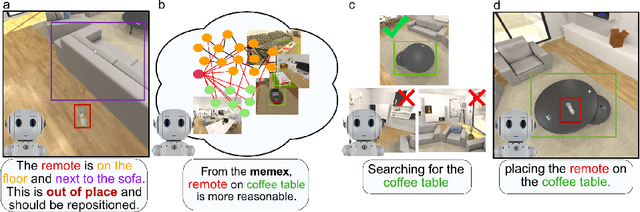
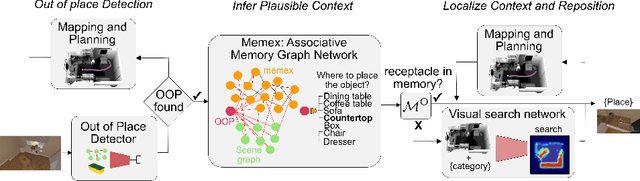

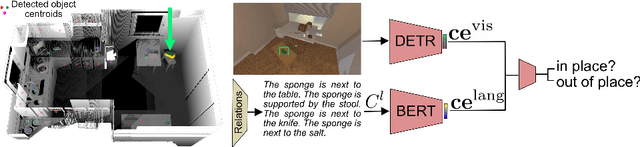
We introduce TIDEE, an embodied agent that tidies up a disordered scene based on learned commonsense object placement and room arrangement priors. TIDEE explores a home environment, detects objects that are out of their natural place, infers plausible object contexts for them, localizes such contexts in the current scene, and repositions the objects. Commonsense priors are encoded in three modules: i) visuo-semantic detectors that detect out-of-place objects, ii) an associative neural graph memory of objects and spatial relations that proposes plausible semantic receptacles and surfaces for object repositions, and iii) a visual search network that guides the agent's exploration for efficiently localizing the receptacle-of-interest in the current scene to reposition the object. We test TIDEE on tidying up disorganized scenes in the AI2THOR simulation environment. TIDEE carries out the task directly from pixel and raw depth input without ever having observed the same room beforehand, relying only on priors learned from a separate set of training houses. Human evaluations on the resulting room reorganizations show TIDEE outperforms ablative versions of the model that do not use one or more of the commonsense priors. On a related room rearrangement benchmark that allows the agent to view the goal state prior to rearrangement, a simplified version of our model significantly outperforms a top-performing method by a large margin. Code and data are available at the project website: https://tidee-agent.github.io/.
A Simple Baseline for BEV Perception Without LiDAR
Jun 16, 2022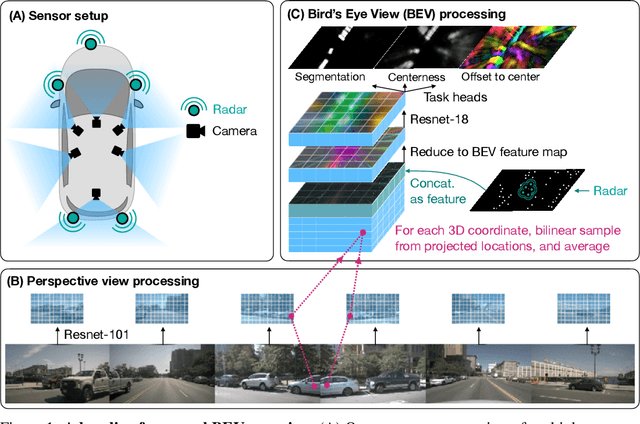



Building 3D perception systems for autonomous vehicles that do not rely on LiDAR is a critical research problem because of the high expense of LiDAR systems compared to cameras and other sensors. Current methods use multi-view RGB data collected from cameras around the vehicle and neurally "lift" features from the perspective images to the 2D ground plane, yielding a "bird's eye view" (BEV) feature representation of the 3D space around the vehicle. Recent research focuses on the way the features are lifted from images to the BEV plane. We instead propose a simple baseline model, where the "lifting" step simply averages features from all projected image locations, and find that it outperforms the current state-of-the-art in BEV vehicle segmentation. Our ablations show that batch size, data augmentation, and input resolution play a large part in performance. Additionally, we reconsider the utility of radar input, which has previously been either ignored or found non-helpful by recent works. With a simple RGB-radar fusion module, we obtain a sizable boost in performance, approaching the accuracy of a LiDAR-enabled system.
Particle Videos Revisited: Tracking Through Occlusions Using Point Trajectories
Apr 08, 2022



Tracking pixels in videos is typically studied as an optical flow estimation problem, where every pixel is described with a displacement vector that locates it in the next frame. Even though wider temporal context is freely available, prior efforts to take this into account have yielded only small gains over 2-frame methods. In this paper, we revisit Sand and Teller's "particle video" approach, and study pixel tracking as a long-range motion estimation problem, where every pixel is described with a trajectory that locates it in multiple future frames. We re-build this classic approach using components that drive the current state-of-the-art in flow and object tracking, such as dense cost maps, iterative optimization, and learned appearance updates. We train our models using long-range amodal point trajectories mined from existing optical flow datasets that we synthetically augment with occlusions. We test our approach in trajectory estimation benchmarks and in keypoint label propagation tasks, and compare favorably against state-of-the-art optical flow and feature tracking methods.
Move to See Better: Towards Self-Supervised Amodal Object Detection
Nov 30, 2020


Humans learn to better understand the world by moving around their environment to get more informative viewpoints of the scene. Most methods for 2D visual recognition tasks such as object detection and segmentation treat images of the same scene as individual samples and do not exploit object permanence in multiple views. Generalization to novel scenes and views thus requires additional training with lots of human annotations. In this paper, we propose a self-supervised framework to improve an object detector in unseen scenarios by moving an agent around in a 3D environment and aggregating multi-view RGB-D information. We unproject confident 2D object detections from the pre-trained detector and perform unsupervised 3D segmentation on the point cloud. The segmented 3D objects are then re-projected to all other views to obtain pseudo-labels for fine-tuning. Experiments on both indoor and outdoor datasets show that (1) our framework performs high-quality 3D segmentation from raw RGB-D data and a pre-trained 2D detector; (2) fine-tuning with self-supervision improves the 2D detector significantly where an unseen RGB image is given as input at test time; (3) training a 3D detector with self-supervision outperforms a comparable self-supervised method by a large margin.
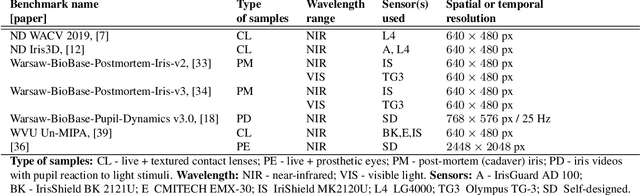
Iris Liveness Detection Competition (LivDet-Iris) -- The 2020 Edition
Sep 01, 2020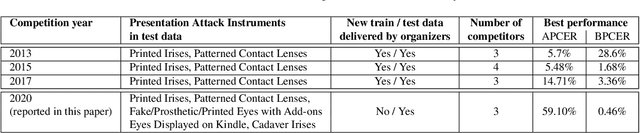
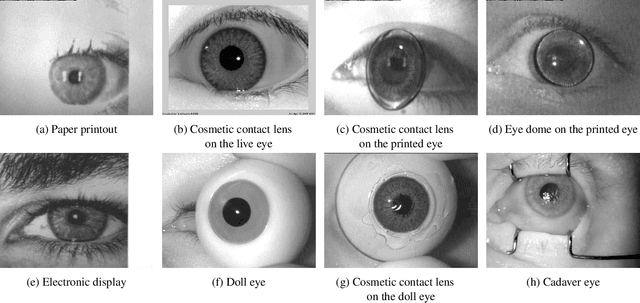
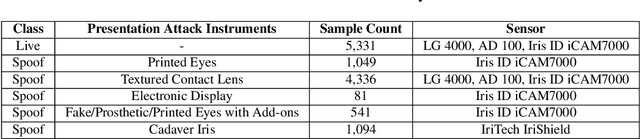
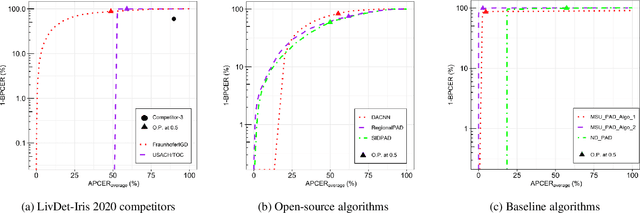
Launched in 2013, LivDet-Iris is an international competition series open to academia and industry with the aim to assess and report advances in iris Presentation Attack Detection (PAD). This paper presents results from the fourth competition of the series: LivDet-Iris 2020. This year's competition introduced several novel elements: (a) incorporated new types of attacks (samples displayed on a screen, cadaver eyes and prosthetic eyes), (b) initiated LivDet-Iris as an on-going effort, with a testing protocol available now to everyone via the Biometrics Evaluation and Testing (BEAT)(https://www.idiap.ch/software/beat/) open-source platform to facilitate reproducibility and benchmarking of new algorithms continuously, and (c) performance comparison of the submitted entries with three baseline methods (offered by the University of Notre Dame and Michigan State University), and three open-source iris PAD methods available in the public domain. The best performing entry to the competition reported a weighted average APCER of 59.10\% and a BPCER of 0.46\% over all five attack types. This paper serves as the latest evaluation of iris PAD on a large spectrum of presentation attack instruments.
Open Source Iris Recognition Hardware and Software with Presentation Attack Detection
Aug 19, 2020
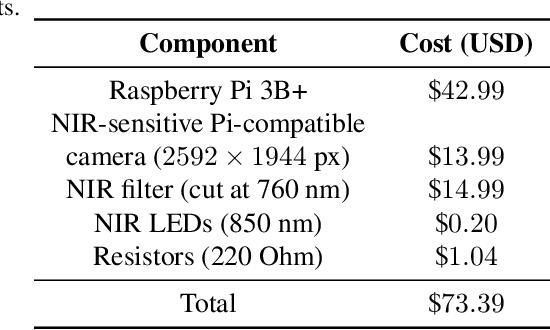
This paper proposes the first known to us open source hardware and software iris recognition system with presentation attack detection (PAD), which can be easily assembled for about 75 USD using Raspberry Pi board and a few peripherals. The primary goal of this work is to offer a low-cost baseline for spoof-resistant iris recognition, which may (a) stimulate research in iris PAD and allow for easy prototyping of secure iris recognition systems, (b) offer a low-cost secure iris recognition alternative to more sophisticated systems, and (c) serve as an educational platform. We propose a lightweight image complexity-guided convolutional network for fast and accurate iris segmentation, domain-specific human-inspired Binarized Statistical Image Features (BSIF) to build an iris template, and to combine 2D (iris texture) and 3D (photometric stereo-based) features for PAD. The proposed iris recognition runs in about 3.2 seconds and the proposed PAD runs in about 4.5 seconds on Raspberry Pi 3B+. The hardware specifications and all source codes of the entire pipeline are made available along with this paper.
Iris Presentation Attack Detection: Where Are We Now?
Jul 16, 2020
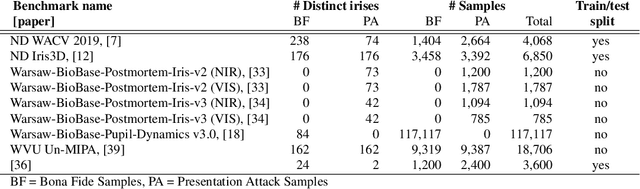
As the popularity of iris recognition systems increases, the importance of effective security measures against presentation attacks becomes paramount. This work presents an overview of the most important advances in the area of iris presentation attack detection published in recent two years. Newly-released, publicly-available datasets for development and evaluation of iris presentation attack detection are discussed. Recent literature can be seen to be broken into three categories: traditional "hand-crafted" feature extraction and classification, deep learning-based solutions, and hybrid approaches fusing both methodologies. Conclusions of modern approaches underscore the difficulty of this task. Finally, commentary on possible directions for future research is provided.
Robust Iris Presentation Attack Detection Fusing 2D and 3D Information
Feb 21, 2020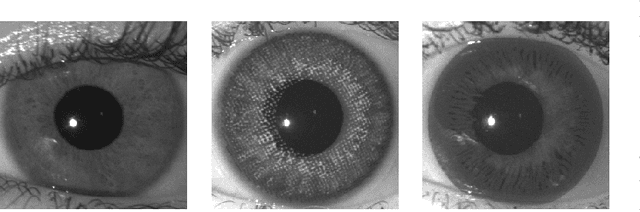
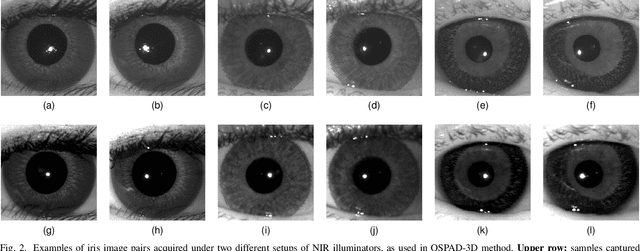

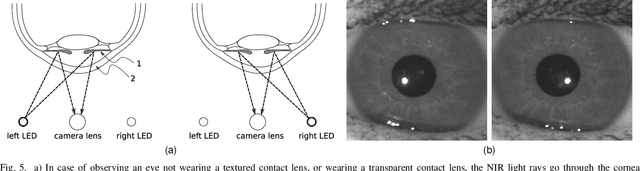
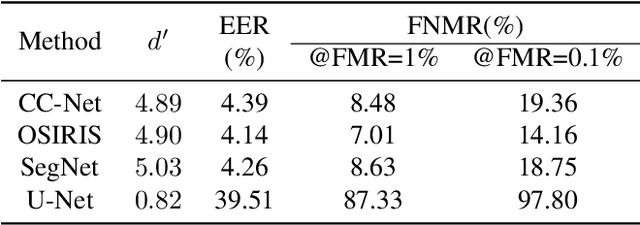
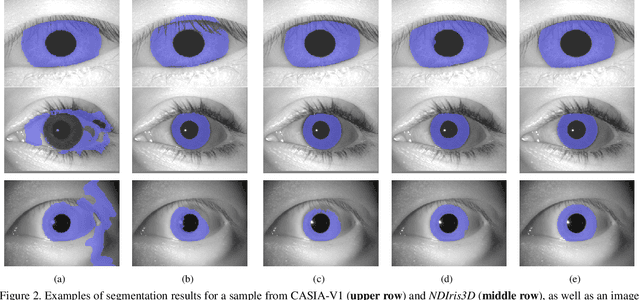
Diversity and unpredictability of artifacts potentially presented to an iris sensor calls for presentation attack detection methods that are agnostic to specificity of presentation attack instruments. This paper proposes a method that combines two-dimensional and three-dimensional properties of the observed iris to address the problem of spoof detection in case when some properties of artifacts are unknown. The 2D (textural) iris features are extracted by a state-of-the-art method employing Binary Statistical Image Features (BSIF) and an ensemble of classifiers is used to deliver 2D modality-related decision. The 3D (shape) iris features are reconstructed by a photometric stereo method from only two images captured under near-infrared illumination placed at two different angles, as in many current commercial iris recognition sensors. The map of normal vectors is used to assess the convexity of the observed iris surface. The combination of these two approaches has been applied to detect whether a subject is wearing a textured contact lens to disguise their identity. Extensive experiments with NDCLD'15 dataset, and a newly collected NDIris3D dataset show that the proposed method is highly robust under various open-set testing scenarios, and that it outperforms all available open-source iris PAD methods tested in identical scenarios. The source code and the newly prepared benchmark are made available along with this paper.
AlignNet: A Unifying Approach to Audio-Visual Alignment
Feb 12, 2020
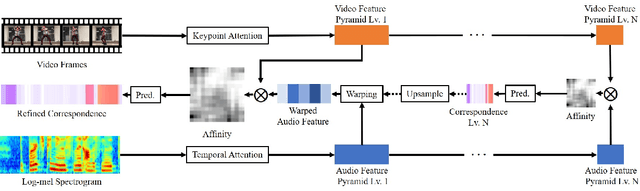
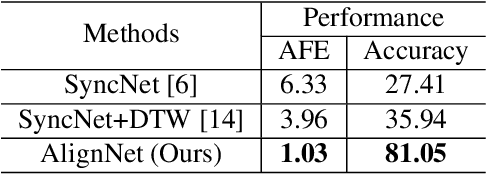

We present AlignNet, a model that synchronizes videos with reference audios under non-uniform and irregular misalignments. AlignNet learns the end-to-end dense correspondence between each frame of a video and an audio. Our method is designed according to simple and well-established principles: attention, pyramidal processing, warping, and affinity function. Together with the model, we release a dancing dataset Dance50 for training and evaluation. Qualitative, quantitative and subjective evaluation results on dance-music alignment and speech-lip alignment demonstrate that our method far outperforms the state-of-the-art methods. Project video and code are available at https://jianrenw.github.io/AlignNet.