 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViBES: A Conversational Agent with Behaviorally-Intelligent 3D Virtual Body
Dec 16, 2025



Human communication is inherently multimodal and social: words, prosody, and body language jointly carry intent. Yet most prior systems model human behavior as a translation task co-speech gesture or text-to-motion that maps a fixed utterance to motion clips-without requiring agentic decision-making about when to move, what to do, or how to adapt across multi-turn dialogue. This leads to brittle timing, weak social grounding, and fragmented stacks where speech, text, and motion are trained or inferred in isolation. We introduce ViBES (Voice in Behavioral Expression and Synchrony), a conversational 3D agent that jointly plans language and movement and executes dialogue-conditioned body actions. Concretely, ViBES is a speech-language-behavior (SLB) model with a mixture-of-modality-experts (MoME) backbone: modality-partitioned transformer experts for speech, facial expression, and body motion. The model processes interleaved multimodal token streams with hard routing by modality (parameters are split per expert), while sharing information through cross-expert attention. By leveraging strong pretrained speech-language models, the agent supports mixed-initiative interaction: users can speak, type, or issue body-action directives mid-conversation, and the system exposes controllable behavior hooks for streaming responses. We further benchmark on multi-turn conversation with automatic metrics of dialogue-motion alignment and behavior quality, and observe consistent gains over strong co-speech and text-to-motion baselines. ViBES goes beyond "speech-conditioned motion generation" toward agentic virtual bodies where language, prosody, and movement are jointly generated, enabling controllable, socially competent 3D interaction. Code and data will be made available at: ai.stanford.edu/~juze/ViBES/
The Language of Motion: Unifying Verbal and Non-verbal Language of 3D Human Motion
Dec 13, 2024Human communication is inherently multimodal, involving a combination of verbal and non-verbal cues such as speech, facial expressions, and body gestures. Modeling these behaviors is essential for understanding human interaction and for creating virtual characters that can communicate naturally in applications like games, films, and virtual reality. However, existing motion generation models are typically limited to specific input modalities -- either speech, text, or motion data -- and cannot fully leverage the diversity of available data. In this paper, we propose a novel framework that unifies verbal and non-verbal language using multimodal language models for human motion understanding and generation. This model is flexible in taking text, speech, and motion or any combination of them as input. Coupled with our novel pre-training strategy, our model not only achieves state-of-the-art performance on co-speech gesture generation but also requires much less data for training. Our model also unlocks an array of novel tasks such as editable gesture generation and emotion prediction from motion. We believe unifying the verbal and non-verbal language of human motion is essential for real-world applications, and language models offer a powerful approach to achieving this goal. Project page: languageofmotion.github.io.
Tracking Emerges by Looking Around Static Scenes, with Neural 3D Mapping
Aug 04, 2020We hypothesize that an agent that can look around in static scenes can learn rich visual representations applicable to 3D object tracking in complex dynamic scenes. We are motivated in this pursuit by the fact that the physical world itself is mostly static, and multiview correspondence labels are relatively cheap to collect in static scenes, e.g., by triangulation. We propose to leverage multiview data of \textit{static points} in arbitrary scenes (static or dynamic), to learn a neural 3D mapping module which produces features that are correspondable across time. The neural 3D mapper consumes RGB-D data as input, and produces a 3D voxel grid of deep features as output. We train the voxel features to be correspondable across viewpoints, using a contrastive loss, and correspondability across time emerges automatically. At test time, given an RGB-D video with approximate camera poses, and given the 3D box of an object to track, we track the target object by generating a map of each timestep and locating the object's features within each map. In contrast to models that represent video streams in 2D or 2.5D, our model's 3D scene representation is disentangled from projection artifacts, is stable under camera motion, and is robust to partial occlusions. We test the proposed architectures in challenging simulated and real data, and show that our unsupervised 3D object trackers outperform prior unsupervised 2D and 2.5D trackers, and approach the accuracy of supervised trackers. This work demonstrates that 3D object trackers can emerge without tracking labels, through multiview self-supervision on static data.
Embodied View-Contrastive 3D Feature Learning
Jul 10, 2019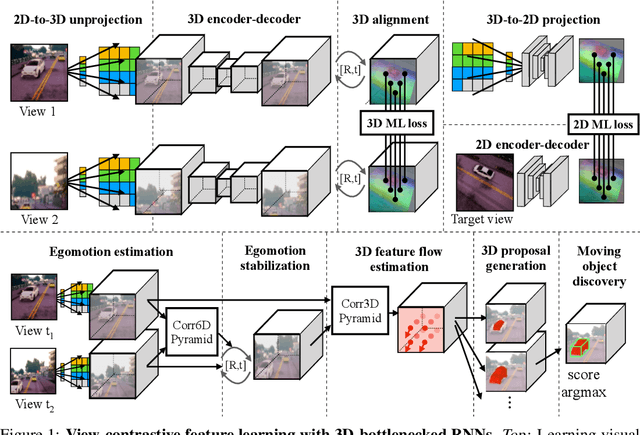
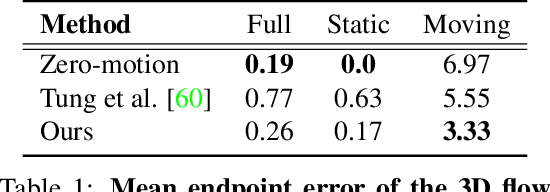

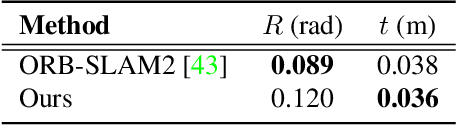
Humans can effortlessly imagine the occluded side of objects in a photograph. We do not simply see the photograph as a flat 2D surface, we perceive the 3D visual world captured in it, by using our imagination to inpaint the information lost during camera projection. We propose neural architectures that similarly learn to approximately imagine abstractions of the 3D world depicted in 2D images. We show that this capability suffices to localize moving objects in 3D, without using any human annotations. Our models are recurrent neural networks that consume RGB or RGB-D videos, and learn to predict novel views of the scene from queried camera viewpoints. They are equipped with a 3D representation bottleneck that learns an egomotion-stabilized and geometrically consistent deep feature map of the 3D world scene. They estimate camera motion from frame to frame, and cancel it from the extracted 2D features before fusing them in the latent 3D map. We handle multimodality and stochasticity in prediction using ranking-based contrastive losses, and show that they can scale to photorealistic imagery, in contrast to regression or VAE alternatives. Our model proposes 3D boxes for moving objects by estimating a 3D motion flow field between its temporally consecutive 3D imaginations, and thresholding motion magnitude: camera motion has been cancelled in the latent 3D space, and thus any non-zero motion is an indication of an independently moving object. Our work underlines the importance of 3D representations and egomotion stabilization for visual recognition, and proposes a viable computational model for learning 3D visual feature representations and 3D object bounding boxes supervised by moving and watching objects move.