 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied View-Contrastive 3D Feature Learning
Paper and Code
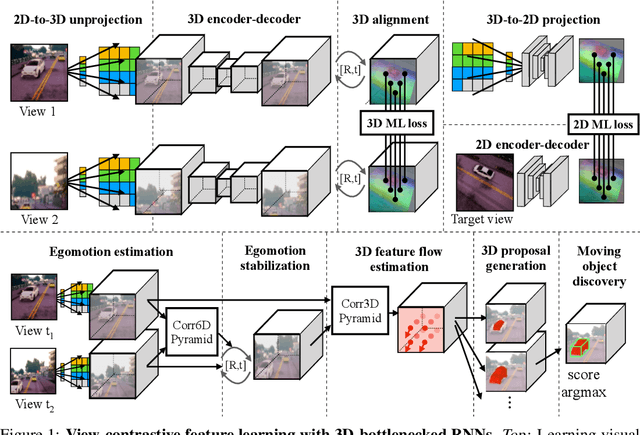
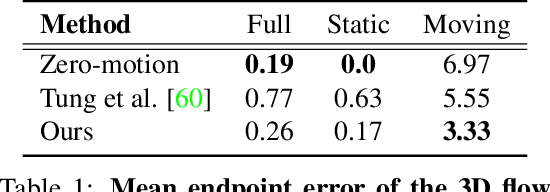

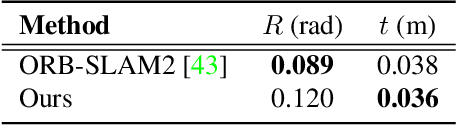
Humans can effortlessly imagine the occluded side of objects in a photograph. We do not simply see the photograph as a flat 2D surface, we perceive the 3D visual world captured in it, by using our imagination to inpaint the information lost during camera projection. We propose neural architectures that similarly learn to approximately imagine abstractions of the 3D world depicted in 2D images. We show that this capability suffices to localize moving objects in 3D, without using any human annotations. Our models are recurrent neural networks that consume RGB or RGB-D videos, and learn to predict novel views of the scene from queried camera viewpoints. They are equipped with a 3D representation bottleneck that learns an egomotion-stabilized and geometrically consistent deep feature map of the 3D world scene. They estimate camera motion from frame to frame, and cancel it from the extracted 2D features before fusing them in the latent 3D map. We handle multimodality and stochasticity in prediction using ranking-based contrastive losses, and show that they can scale to photorealistic imagery, in contrast to regression or VAE alternatives. Our model proposes 3D boxes for moving objects by estimating a 3D motion flow field between its temporally consecutive 3D imaginations, and thresholding motion magnitude: camera motion has been cancelled in the latent 3D space, and thus any non-zero motion is an indication of an independently moving object. Our work underlines the importance of 3D representations and egomotion stabilization for visual recognition, and proposes a viable computational model for learning 3D visual feature representations and 3D object bounding boxes supervised by moving and watching objects move.